RVC WebUIで音声モデルを学習させる(画像付き)

1. RVCをインストールする
1-1. ファイルをダウンロードする。
下記のHugging FaceからRVC-beta.7zをダウンロードして解凍する。

1-2. WebUIを起動する
go-web.batを開く。
コマンドプロンプトが起動し、時間がたつと、WebUIがブラウザに開かれます。


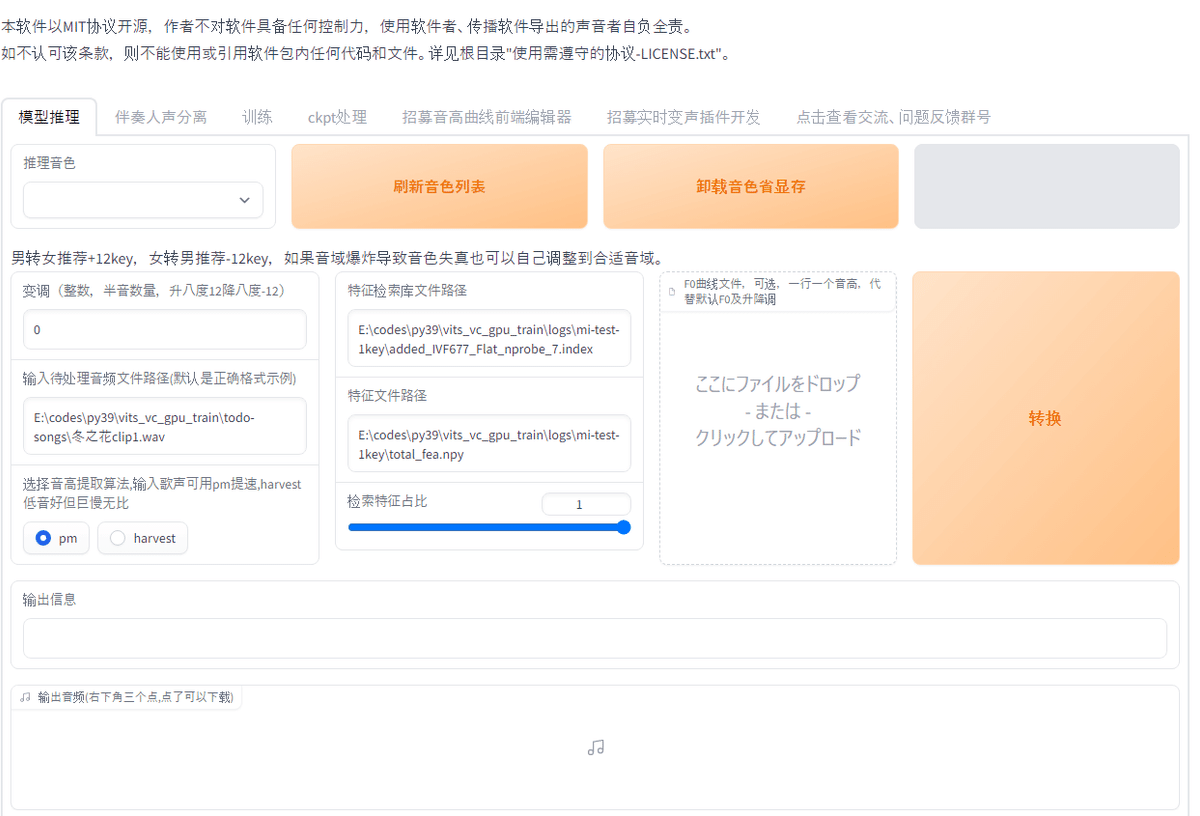
2. モデルを作成する
2-1. モデルを作成する画面へ移動します。
タブのナビゲーションから、「训练 (トレーニング)」を選択します。

2-1. Step1に生成されるファイルについての情報を入れます。
输入实验名(モデル名を入力する)に、生成されるモデルの名前を入力します。
その他の値は、好みで変更します。
目标采样率 (ターゲットサンプリングレート)
模型是否带音高指导(唱歌一定要,语音可以不要) (ピッチガイダンス付きかどうか(歌唱は必須、音声は省略可))

2-2. Step2aで学習させるファイルをインポートします。
输入训练文件夹路径 (トレーニングフォルダーパスを入力) に、トレーニングに使う音声ファイルが入ったフォルダのパスを入力します。

「处理数据」ボタンをクリックし、インポートします。
「输出信息」に、インポートしたファイル名と一緒に、「end preprocess」が表示されたらOK
2-2. Step2bで学習の環境をインポートします。
使用しているグラフィックボードとCPUについて入力します。
グラボについて入力されているので、CPUについて入力していきます。
Ctrl + Shift + Esc を押して、タスクマネージャーを開きます。
タブメニューのパフォーマンスを開きます。
「論理プロセッサ数」の数字を確認します。
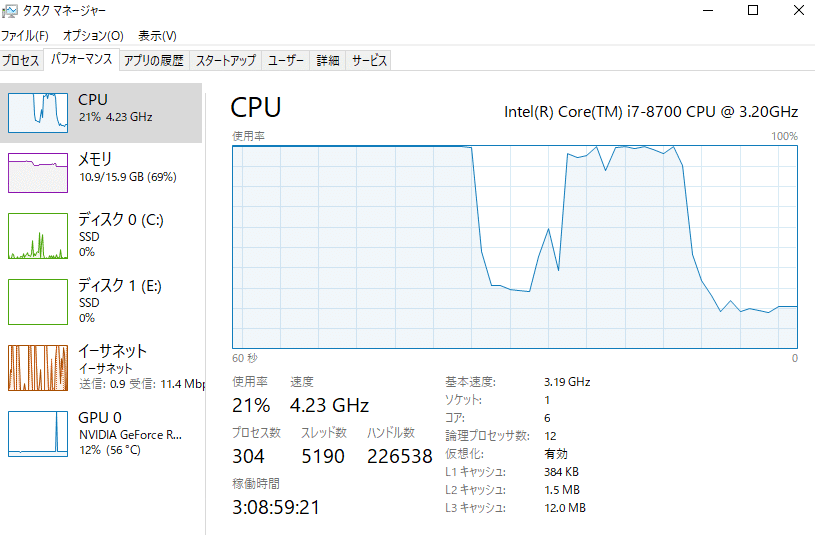
「提取音高使用的CPU进程数」に確認した値を入力します。

2-3. Step3トレーニングの設定を入力してトレーニングを開始
左上から説明していきます。
save_every_epoch(保存频率) : 学習中の保存頻度です。特に変更は不要かと
total_epoch(总训练轮数) はどれだけ学習させるかを表します。個人で試した範囲だとセリフ集100個で、3~40ぐらいが良い感じがしました。
batch_size : どれだけ1度で学習するかです。増やすと学習が早く終わりますが、増やしすぎるとエラーが出ました。絵などと違ってそこまで時間が変わらないので、そんなに増やさなくても良いかも?
他はデフォルトで基本問題ないはずです。

数値が決まったら「一键训练」(ワンクリックトレーニング)ボタンを押します。
3. モデルを確認する
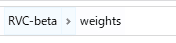
モデルの学習が終わると、RVC-betaフォルダのweightsフォルダに、2-1で設定したファイル名で保存されています。
以上でモデルの学習方法は終わりです。
モデルの学習が簡単すぎて、モデルの学習素材を集めて作る方が大変だなーという感じでした。