
[Vol.10] 数学が苦手でもできるビッグデータを活用した分析

立正大学データサイエンス学部データサイエンス学科 教授 白川清美
昨今、データサイエンスが話題になっていますが、どの本を見ても難しい数式が並んでいます。身近な事象を題材に、統計的な手法を用いた分析をしてみたいけれど、数式が理解できないので、諦めてしまいます。
そんな時、ビッグデータを使うことで、分析手法が理解できる方法があります。
今回は、整数の組を使ったシミュレーションで、平均や分散について理解してみたいと思います。ちなみに、シミュレーション手順1と手順2の内容は、EXCELなどのソフトによって簡単に再現できます。
■ シミュレーション⼿順1:条件を満たす整数組たちを作る
シミュレーションに⽤いるのは、「⾜して■になるような▲つ」という条件を満たす0以上の整数組たちです。
例えば、「⾜して100になるような2つ」の0以上の整数組は何種類あるでしょうか。0と100なら⾜して100になりますし、50と50も⾜して100になりますね。このように愚直に書き連ねていくと、
(100, 0): 100 + 0 = 100
(99, 1): 99 + 1 = 100
(98, 2): 98 + 2 = 100
⋮
(51, 49): 51 + 49 = 100
(50, 50): 50 + 50 = 100
となるので、全部で51種類あることがわかります。
■ シミュレーション⼿順2:整数組たちの平均と分散を求める
データ分析は、平均、分散などの統計量に基づいた統計的手法が使われます。ここでは平均と分散を求めてみます。
平均は、標本の個々の値を全て足した総計を、サンプルサイズで割ることで得られる、ある種の基準点です。
分散は、標本の個々の値がどのくらい平均から離れているかを数値化しています。すなわち、
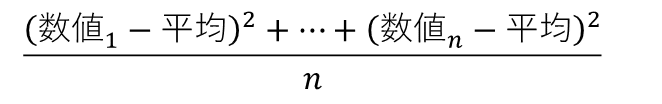
となります。nは標本の総数です。この式を変形すると、
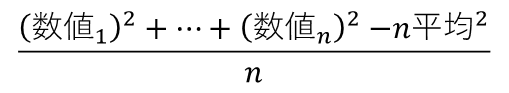
というように簡素にできます。したがって、平均さえ同じであれば、標本の個々の値の2乗和(平方和といいます)を比べるだけで、異なる標本同士で分散の大きさを比べることができるのです。
■ シミュレーション⼿順3:分散の大きさを感じる
さて、前述で2つの整数組が51種類ある、といいましたが、これを「n=2からなるような標本が51個ある」という⾒⽅をしてみてください。サンプルサイズが2である標本が、51個あるのです。このそれぞれについて、分散を求めることを考えます。すると、51個の平均と分散が求まります(図1参照)。
(100, 0) : 平均= 50,分散= 2500
(99, 1) : 平均= 50,分散= 2401
(98, 2) : 平均= 50,分散= 2304
⋮
(51, 49) : 平均= 50,分散= 1
(50, 50) : 平均= 50,分散= 0

図1 51個の標本とその分散
平均というのは、総計÷サンプルサイズであるので、51個の標本について同じ値となります。分散は、(100, 0)という組が最⼤となり、(50, 50)という組が最⼩となりました。分散というのは個々の値がどのくらい平均から離れているかを求めるものであるので、直感的にも納得がいきます。
ここで、わたしたちは、サンプルサイズが2である整数値の標本に関して、「最も分散が⼤きい場合」と「最も分散が⼩さい場合」の理論値を得たことになります。すなわち、この先どんな種類の標本を得たとしても、サンプルサイズが2である整数値の標本なら、計算することなしに「ああ、これはそこまで⼤きな分散ではないね、だってわたしは、(100, 0)というとても極端な例を知っているから」という判断ができるのです。分散を求めたところで、それが⼤きいのか⼩さいのかわからなければ、折⻆計算したのにもったいないことではありませんか。
さらに、順序統計量が算出できるなら、分散の程度について定量的に述べることができます。例えば、(75, 25)という標本の分散は、625です。これは存在しうる51個の分散の中の、50%点に相当する分散で、「分散は⼤きくも⼩さくもない」というより厳密な判断ができます。
■ データベースによる汎用化
ここまでは、簡単のために、足して100になるような2つの0以上の整数組を使いました。しかし、現実にサンプルサイズが2の標本にお目にかかることはあまりないと思います。とはいえ、「足して100になるような100つ」の0以上の整数組を考えると…1億9千万種類の標本を考えることになってしまいます。
そこで、「足して■になるような▲つ」の0以上の整数組の全種類についての統計量を、100までの■や▲でデータベース(DB)化しました。これによって、計算しなくても分散などがわかるようになっています(図2参照)。このDBの利用は、「基本統計量に基づいた度数別数値パターン検索(脚注)」で説明しています。
最後に、無数にある組み合わせパターンをいくつかの条件を付けることで、有限化しました。その有限になったパターンの統計量をデータベース化して、いろいろなことを明確化しています。このデータベースは、必要に応じて、拡張も可能な設計になっています。

図2 統計量を格納したDB
データサイエンスは、これまでにない発想により、活用範囲が広がります。まずは、データに慣れることから始めましょう!
脚注:https://rcisss.ier.hit-u.ac.jp/Japanese/micro/study06.html