
【完全初心者OK!】StableDiffusionで誰でも簡単に画像を自動生成する方法!【google Colab × WebUI】

この記事では今流行りの「stable diffusion」を使った画像生成の方法を誰でも実践できるように分かりやすく解説していきます!
stable diffusionは、主にローカル環境で利用する方法とgoogle colabを利用する方法がありますが、今回は使っているパソコンのスペックに依らずにstable diffusionを使用できるgoogle colabを使った方法の解説をしていきます。
Stable diffusionと同じ画像自動生成にMidjourneyというサービスもあります。Midjourneyの使い方についてはこちら
事前準備
google Colabとgoogleドライブを使える状態にしておいて下さい。googleアカウントさえ持っていれば誰でも使えます。
AUTOMATIC1111の導入
google colabでstable diffusionを使うのにも様々な方法があるのですが、今回は「AUTOMATIC1111」のノートブック「maintained by Akaibu」を利用する方法を紹介していきます。手軽さと使用モデルやloraなどのカスタマイズ性のし易さを考えての選択です。
まず以下のリンクの「maintained by Akaibu」をクリックします。
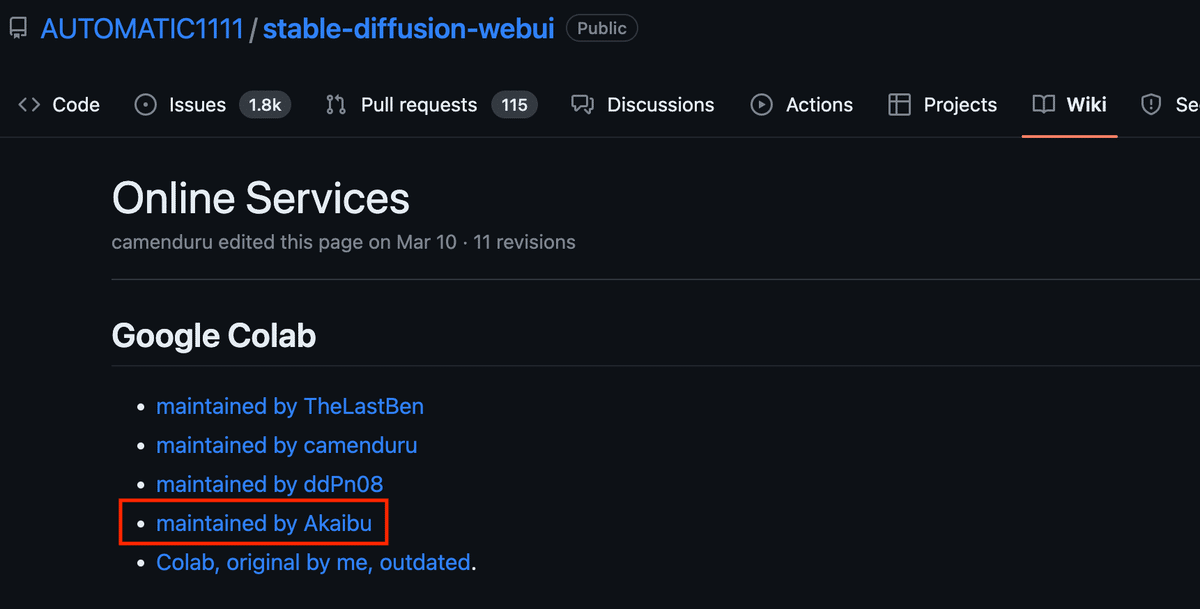
するとノートブックが自動的に起動します。
このノートブックを直接使ってもいいですが、今後のために「ファイル」→「ドライブにコピーを保存」を選択し、googleドライブにノートブックをコピーしそちらを編集することをオススメします。
これでノートブックの基本の準備は終了です。

モデルのダウンロード
stable diffusionで使用したいモデルデータをダウンロードします。モデルは「fuggingface」や「civitai」でダウンロード出来ます。今回は「ChilloutMix」という実写系のモデルを例に解説していきます。モデルには様々な種類があるので自分の目的に合わせて使ってみて下さい。
モデルの選び方はこちらの方の記事が参考になるかもしれません。
では、実際に「ChilloutMix」をダウンロードして進めていきましょう。以下のリンクからモデルのダウンロードをクリックし適当なところへ保存して下さい。
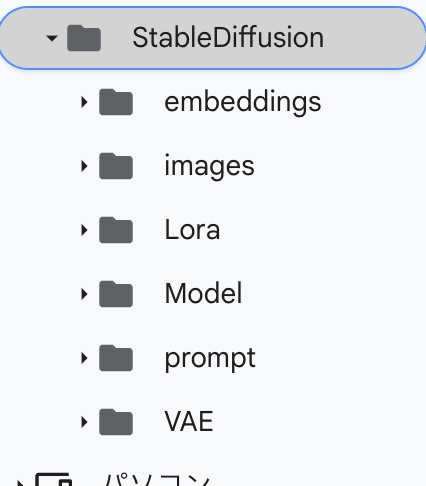
その後googleドライブに「StableDiffusion」というフォルダを作りその中に「Model」というフォルダを作ります。写真では他にも様々なフォルダがありますが機能を拡張するときに使うものなので取り敢えず「Model」というフォルダさえあればOKです。
「Model」フォルダを作ったら先ほどダウンロードした「ChilloutMix」をその中にアップロードして下さい。
WebUIの起動

さて、ここまで出来たら先ほどのノートブックに戻り一番上にコードを追加します。マウスを一番上に持っていくと追加でコードが書けるボタンが出現するのでクリックします。
そこに以下のコードをコピペして下さい。これはwebuiに直接関係するものではありませんが、colabのtorchのバージョンを変更するものでこうしないとエラーになる事例があるので先に追加しておきます。
!pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 torchtext==0.14.1 torchdata==0.5.1 --extra-index-url https://download.pytorch.org/whl/cu116その後、追加したコードの下でもう一度「+コード」を押し今度は以下のコードをコピペします。これはcolabと自分のgoogleドライブを連携するものです。
from google.colab import drive
drive.mount('/content/drive')このようにコードが追加されていればOKです。

さらにその下にあるSD1.5というコードの下3行の先頭に「#」をつけて下さい。必要ないコードなのでコメントアウトします。ここまでで上の写真のようになっていれば問題ありません。
さて次はgoogleドライブにアップロードしたモデルをwebuiにコピーしていきます。以下のコードをSD1.5の下に新たに追加して下さい。
#モデルのインストール
!cp /content/drive/MyDrive/StableDiffusion/Model/chilloutmix_NiPrunedFp32Fix.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/
#Loraのインストール
#!cp /content/drive/MyDrive/StableDiffusion/Lora/japanesedolllikenessV1_v15.safetensors /content/stable-diffusion-webui/models/Lora
#embediingインストール
#!cp /content/drive/MyDrive/StableDiffusion/embeddings/EasyNegative.safetensors /content/stable-diffusion-webui/embeddings
#VAEインストール
#!cp /content/drive/MyDrive/StableDiffusion/VAE/vae-ft-mse-840000-ema-pruned.ckpt /content/stable-diffusion-webui/models/VAE今はモデルのインストールのみを行うため他のコードはコメントアウトしてありますが、今後LoraやVAE、embeddingといったより高度な技術を使いたくなった時は、モデルと同じようにこの段階でインストールします。またchilloutmix以外のモデルを使っている人は上のコードの!cp以降のパスを書き換えて下さい。
colabとgoogleドライブの連携後にcolabからファイルを選択すると下の写真のようにパスがコピー出来るようになります。これで目的のファイルのパスをコピーし上のコードを書き換えて下さい。
chilloutmixでこの記事と同じように進めてきた人は何も弄らなくて大丈夫です。

ここまででこのようになっています。
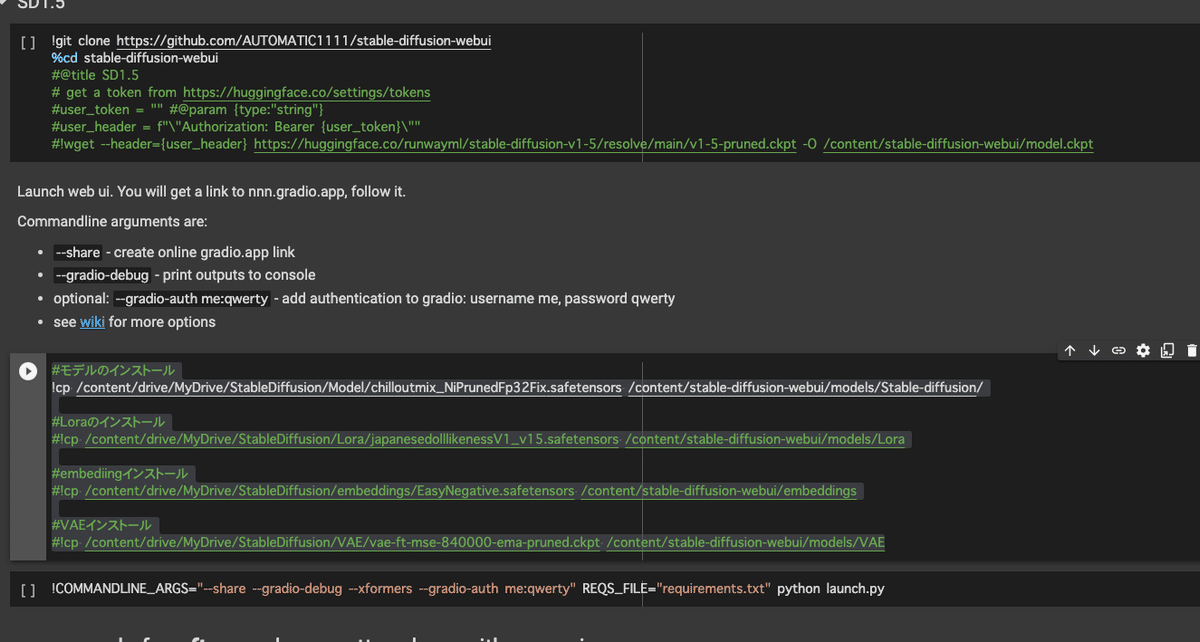
最後に一番下のコードに以下の一文を追加して下さい。下の写真のようになっていれば大丈夫です。このコマンドを追加すると画像生成のスピードがアップします。
--xformers
さてこれで準備は全て終わったので、一番上のコードから順番に実行ボタン(コード左の再生ボタンみたいなやつ)を押していって下さい。途中で許可を様々な許可を求めてくる場合がありますが全て許可していきましょう。
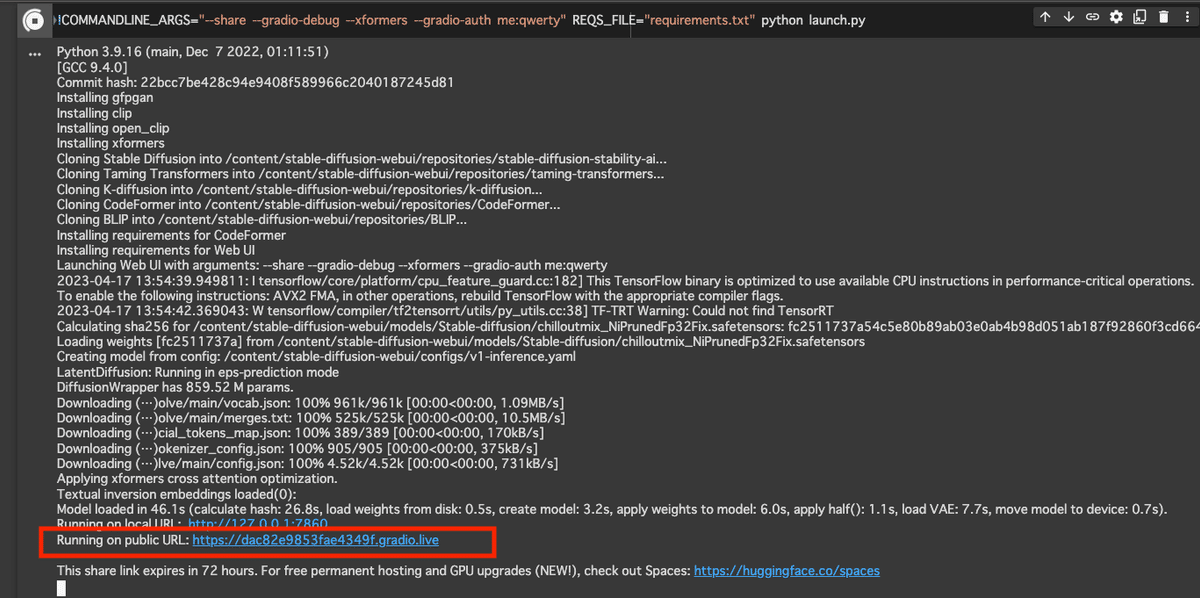
全ての実行が終わると上の写真のような画面になります。これでpublicURLをクリックすると自動でwebUIに移動します。
webuiに移動するとこのようなログイン画面が表示されるので、それぞれ「me」「qwerty」と入力してログインしましょう。
WebUIの使い方
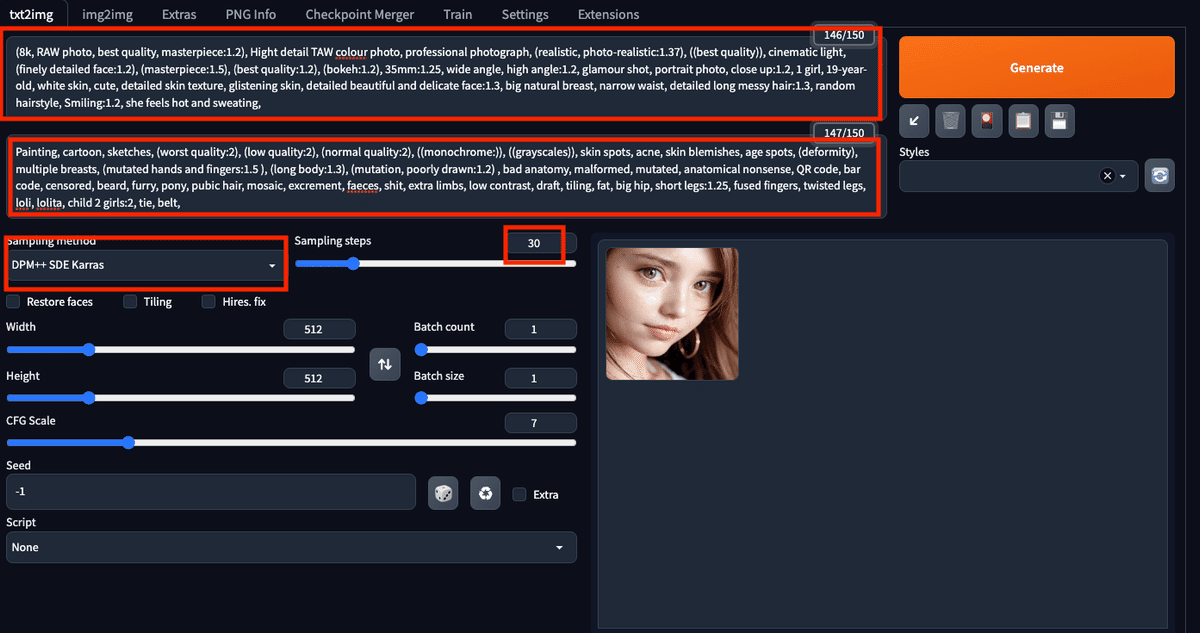
webuiにログイン出来たら早速画像を生成していきましょう。
一番上の欄にポジティブプロンプト(出力したい画像に入れたい要素)、その下はネガティブプロンプト(出力する画像に入れたくない要素)を入力します。sampling stepsを増やすと画像の鮮明度が上がります。作りたい画像の入力を終えたらGenerateをクリックすると画像が生成されます。
今回は初心者向けの超基本的な使い方のみの解説となっているので、慣れてきたら使いながらご自身でどんどんカスタマイズしみて下さい。
この記事が気に入ったらサポートをしてみませんか?