
RVCで歌わせよう 改訂版3 (RVC1006Nvidia使用)

RVCのアプデ
時間がなくてしばらく触れていなかったのでアップデートが入っていることに気づけていませんでした。
アプデで変わったこと
①日本語に対応
②UVR5が組み込まれた
③rmvpe_gpuという学習方法が追加された。
また無料版Google ColabではRVCを使用できなくなりました。
アプデ
のRVC1006Nvidia.7zから新しいRVCをダウンロードできます。
RVC1006Nvidia.7zをダウンロードしたら7z-zipアプリ↓を使って解凍してください。
解凍後はRVC1006Nvidiaフォルダ内のgo-web.batを起動してください。
これで新しいRVCが使えるようになります。
基本は今までと変わりません。
学習準備
まず、歌わせたい人がしゃべっている十分程度の長さの動画、音声ファイルを用意します。
素材の注意点としては
①bgmや雑音などは極力減らす。
②句点ごと(最低二秒)ほどの長さに切り分ける。
③切り分けたファイルを画像のようにフォルダ内に保存する。
などがあります。
歌わせる
学習
トレーニングタブに飛び、五つの場所を変更します。
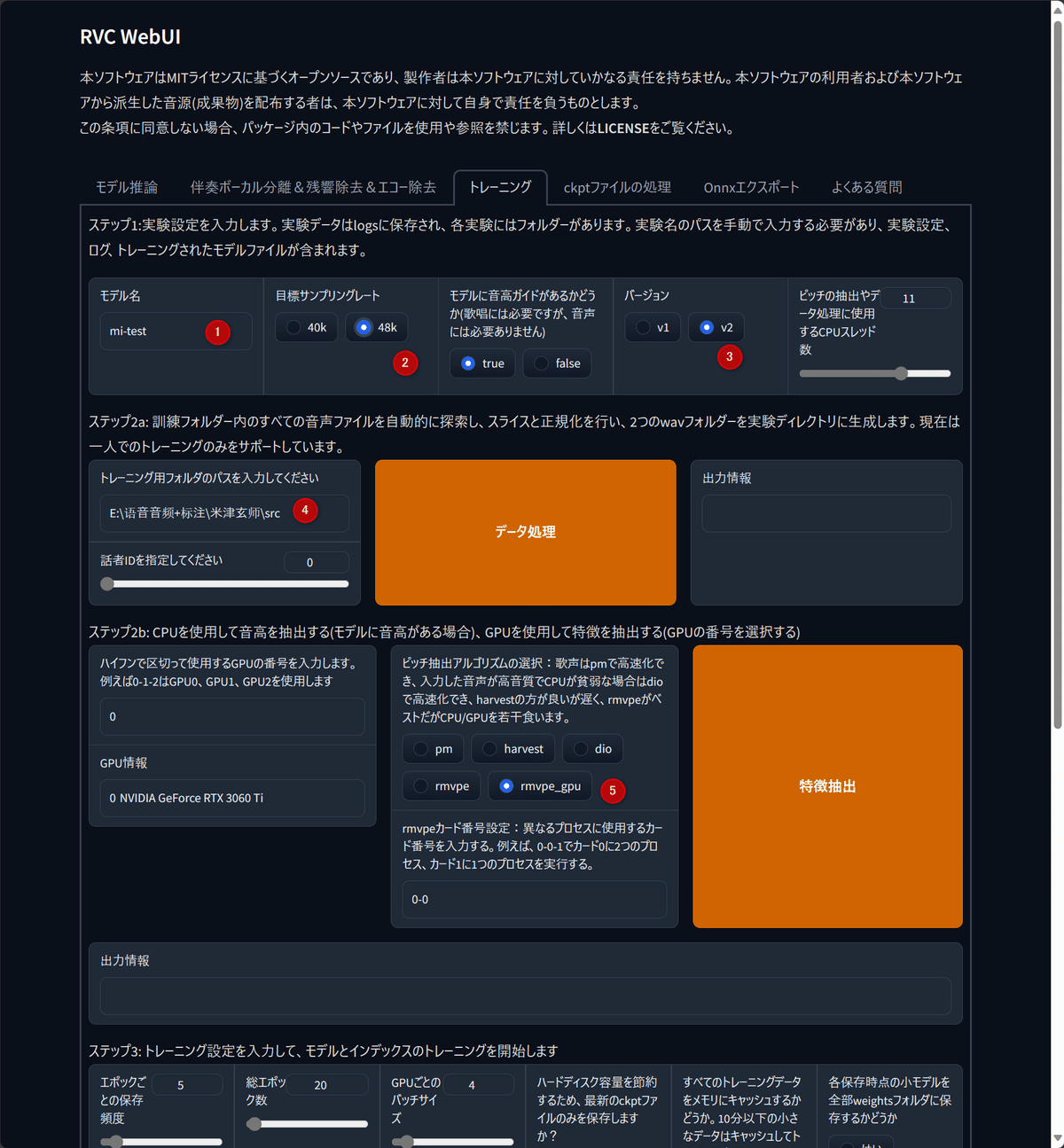
①モデル名
自分の好きな名前で大丈夫です
②サンプリングレート
48kがおすすめです。
③バージョン
v2の方がクオリティが高いです。
④パス
先ほど切り分けたファイルを保存したフォルダのパスを入力してください。
フォルダを右クリすればパスのコピーができます。
⑤アルゴリズムの選択
基本rmvpe_gpuでいいと思いますが好みで変えてokです。
その他の項目については、基本初期設定のままで大丈夫だと思います。
好みで変えてokです。
設定が終わったらワンクリックトレーニングを押してください。
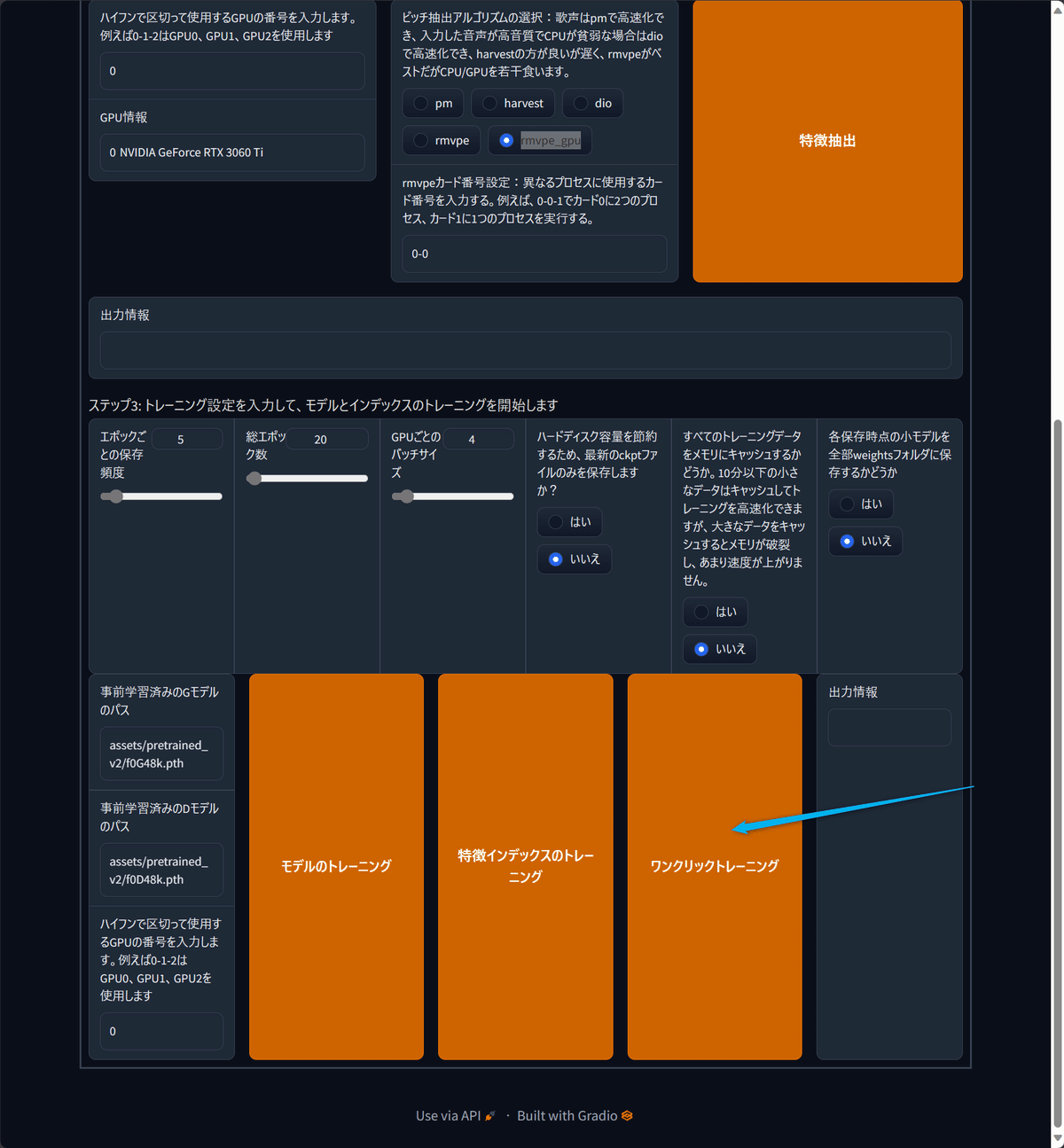
あとは出力情報に全工程が完了!と出るのを待ってください。
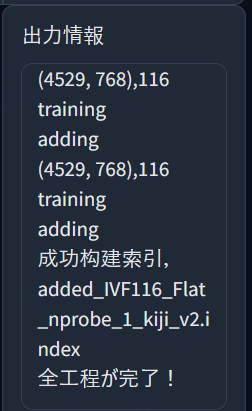
この表示が出たら学習完了です。
完了したら、モデル推論タブに飛び
①音源リストとインデックスパスの更新をして
②音源推論の中に自分が学習させたモデルがあるかを確認してください。
音源作成
歌わせるには音源が必要です。
カラオケにでも行って歌ってきてください。
音源を歌声とBGMに分けていきます。
伴奏ボーカル分離&残響除去&エコー除去タブに飛んでください。
やることは四つあります。

①音源のパスを入れる
ここで注意してほしいのは、入れるパスはフォルダのパスであり、ファイルのパスではないということ。
また、フォルダ内のすべての音声を分けてしまうため、新しいフォルダを作ってからやってください。
②モデル選択
HP2かHP3がおすすめです。
他の設定だとうまく分けることができません。推奨される最もクリーンな設定でもうまくいきません。
③&④ファイルの保存場所決定
分けた後のファイルを保存するフォルダのパスを入れてください。
同じフォルダでいいと思います。
以上の設定ができたら変換を押して変換し終わるまで待ってください。
歌わせる
モデル推論タブに飛んでください。
やることは五つ
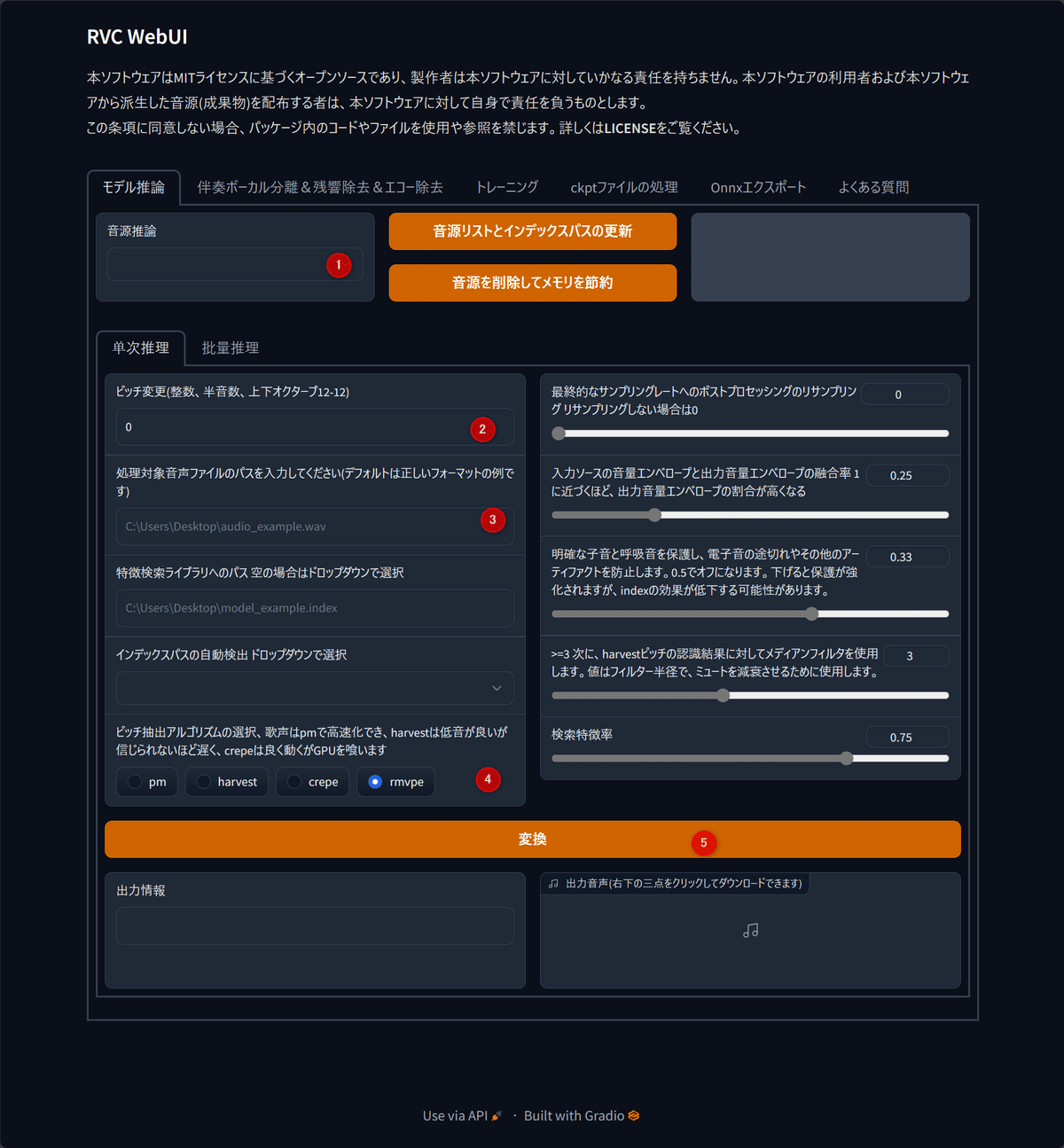
①先ほど学習したモデルを選ぶ
②ピッチ変更
男性が歌っている歌を女性に歌わせる→+12
女性が歌っている歌を男性に歌わせる→-12
絶対これというわけではないので、臨機応変に対応してください。
③先ほど声とBGMに分けた音源の声の方のファイルのパスを入力
④アルゴリズム選択
rmvpeが一番バランスがいいです。
質を求めるならharvestかcrepeがおすすめです。
⑤変換
なお、右側の設定は変えても変えなくてもいいです。
ここは自由
あとは変換終わりまで待てば、歌声は完成。
出力情報のところで聞いてみてください。
BGMとくっつける
ラストです。
Audacityをインストールして開いてください。
Audacityに生成した歌声ファイルと、分けたBGMファイルをドラックアンドドロップ。
書き出しをしたら完成です。
追記
あまりこの用途には向いてないけど新しい試してみたい人にはこれを
間違いに気が付いた方や質問はコメントにお願いします。