
Pythonで複数ファイルから見出し行を抽出して目次を作成する

VS Codeだと、マークダウンで原稿を書いていれば、Outlineに見出し行が抽出されて表示されます。
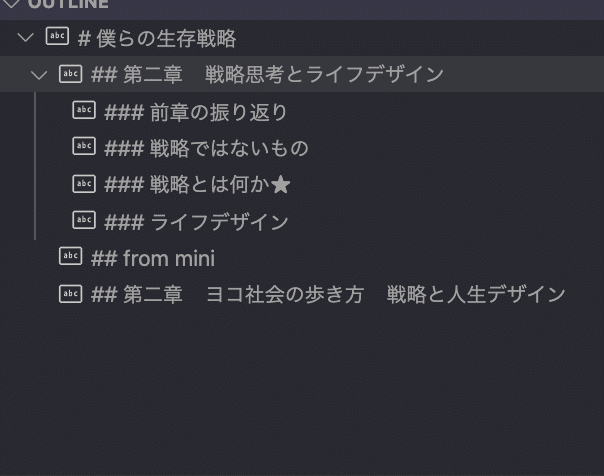
これは結構便利なのですが、章ごとにファイルを分割していると、その章の見出ししか出てきません。アウトラインを切り替えるためには、ファイルを切り替える必要があります。
だったら、原稿ファイルを走査して見出し行を抽出して、それをテキストファイルか何かに書き出せばいいんじゃね?
やってみましょう。
まずイメージしているのは、
python makeTox.py *.mdという形。プログラムファイルの後ろに、見出しを作りたいファイル名を与えたら、そこから抽出してくれる、というもの。でもって、原稿をすべて.mdで保存していれば、それらすべてを走査してくれることになります。
で、標準入出力を扱うから、「import sys」は必須でしょう(これは以前勉強した)。
あと、受け取った引数の配列の一つ目は、プログラム名になっているから、二つ目移行を利用することに。つまり、
import sys
a = sys.argv[1:]です。
あとは、この配列からfileをopenしていけばよさそうですね。一行ごとに処理するので、readlinesが使えるはず。
with open(path) as f:
l = f.readlines()このpathにループで、さっきのaの中身を放り込んでいけばいけそうです。リストの中身を取り出す繰り返しは以下。
for item in list1:さっそく書いてみましょう。
import sys
a = sys.argv[1:]
mainbody = [] #ここに見出し行を入れていくよ
for tfilepath in a:
with open(tfilepath) as f:
l = f.readlines()
for line in l:あとは、ここで取り出した行が「## hoge」みたいな形になっていたら、それを取り出してmainbodyに放り込めばOKです、というところで正規表現を使う必要性に気がつきました。
というわけで、「import re」も追加しておきます。で、それはいいとして、見出し行を抜き出すのって、どうするんだと深く考える前に、CotEditorのマークダウンのシンタックスカラーの指定方法をパクりましょう。
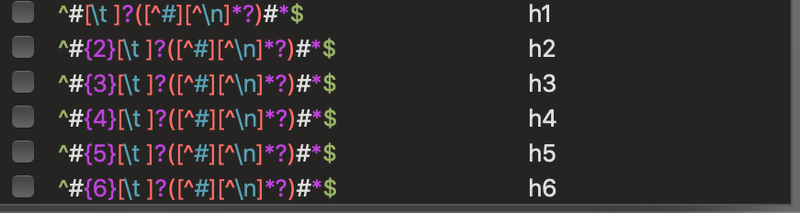
深く考えずに、これをコピーすればOKそうです(使えるものはなんでも使おうの精神で)。
あとは、判定処理のイメージですが、もしその行が正規表現のパターンにマッチする場合は、マッチした部分をmainbodyに格納して、それ以外はスルーというのでよいでしょうか。
for line in l:
h1 = re.match(r'^#[\t ]?([^#][^\n]*?)#*$', line)
if h1:
mainbody.append(h1.group())あとはこれを使いたい見出しの深さ分繰り返せばいいですね。私は見出し3までしかまず使わないので、h3まで対応していれば(いまのところ)OKです。
for line in l:
h1 = re.match(r'^#[\t ]?([^#][^\n]*?)#*$', line)
if h1:
mainbody.append(h1.group())
h2 = re.match(r'^#{2}[\t ]?([^#][^\n]*?)#*$', line)
if h2:
mainbody.append(h2.group())
h3 = re.match(r'^#{3}[\t ]?([^#][^\n]*?)#*$', line)
if h3:
mainbody.append(h3.group())見出しごとに処理を分けるのは面倒な気もしますが、たとえばインデントに差を与えるとかもできそうなので、このままにしておきましょう。
あとは、このmainbodyをテキストファイルに書き出せばOKです。toc.txtとしておきます。
with open(tocfilepaty, mode='w') as f:
f.writelines('\n'.join(mainbody))というわけで、以下で完成です。
import sys
import re
tocfilepaty = 'toc.txt'
a = sys.argv[1:]
mainbody = [] #見出し行を入れる
for tfilepath in a:
with open(tfilepath) as f:
l = f.readlines()
for line in l:
h1 = re.match(r'^#[\t ]?([^#][^\n]*?)#*$', line)
if h1:
mainbody.append(h1.group())
h2 = re.match(r'^#{2}[\t ]?([^#][^\n]*?)#*$', line)
if h2:
mainbody.append(h2.group())
h3 = re.match(r'^#{3}[\t ]?([^#][^\n]*?)#*$', line)
if h3:
mainbody.append(h3.group())
with open(tocfilepaty, mode='w') as f:
f.writelines('\n'.join(mainbody))これを「python makeToc.py *.md」すると、以下のように見出しが抽出されたものがtoc.txtに書き込まれます。

見出しの高さが論理的でないのは、この見出しの抽出をイメージしてファイルを作っていないからです。プログラムのエラーというわけではありませんのであしからず。
とりあえず、OKですね。
この記事が気に入ったらサポートをしてみませんか?