
PyCaretでの機械学習モデルの最適化とパラメータチューニングのサンプルコード

PyCaretはPythonで使える低コードの機械学習ライブラリで、さまざまな自動化処理を提供し、データサイエンスプロジェクトの生産性を向上させることができます。
PyCaretのインストール
PyCaretは多くの依存関係を持つため、新しい環境でのインストールを推奨します。以下のコマンドを使用してインストールできます。
$ pip install pycaret[full]
このコマンドは、すべてのオプショナルな依存関係を含めてPyCaretをインストールします。
サンプルデータセットによる分析例
PyCaretを使用してサンプルデータセットを分析し、結果を可視化するプロセスを詳細に説明します。
この例では、PyCaretに組み込まれているサンプルデータセット「Insurance」を使用します。このデータセットは保険料を予測するためのもので、年齢、性別、BMI、子供の数、喫煙者かどうか、地域による情報が含まれています。
データの読み込みと環境の設定
PyCaretの環境を設定し、データを読み込みます。
from pycaret.datasets import get_data
from pycaret.regression import *
# サンプルデータセットの読み込み
data = get_data('insurance')
# PyCaretの環境設定
s = setup(data, target='charges', session_id=123, normalize=True,
polynomial_features=True,
bin_numeric_features=['age', 'bmi'])モデルの比較
異なる回帰モデルを比較し、最も性能が良いモデルを選択します。
best_model = compare_models()<実行結果>

この表は、様々な機械学習モデルを用いて回帰分析を行った結果を示しています。各行には異なるモデルが記載されており、それぞれの性能を示すいくつかの指標が列で示されています。
MAE (Mean Absolute Error): 予測値と実際の値の絶対差の平均です。値が小さいほどモデルの性能が良いことを示します。
MSE (Mean Squared Error): 予測値と実際の値の差の二乗の平均です。こちらも値が小さいほど性能が良いです。
RMSE (Root Mean Squared Error): MSEの平方根で、値のスケールが元のデータと同じになるため解釈しやすい指標です。
R2 (R-squared): 決定係数とも呼ばれ、モデルがデータのどれくらいを説明しているかを示します。1に近いほど良い。
RMSLE (Root Mean Squared Logarithmic Error): 予測値と実際の値の対数をとった上でのRMSEです。大きな値と小さな値の影響を平等に評価するために使われます。
MAPE (Mean Absolute Percentage Error): 絶対パーセンテージ誤差の平均です。パーセンテージで誤差を表示し、誤差の相対的な大きさを理解しやすくします。
TT (Total Time): モデルのトレーニングにかかった時間(秒)です。
この結果から、Huber RegressorがMAEが最小であり、かつR2が比較的高いことから、誤差が少なくデータの説明も適度に行えていることが分かります。
一方で、Gradient Boosting RegressorはMSEが最小であり、R2も最も高いため、予測の精度とデータの説明度合いに優れています。
この結果を用いて、問題の性質やデータの特性に最も適したモデルを選択することができます。
モデルの作成とチューニング
次にここで実際に精度がよかったGradient Boosting Regressor(勾配ブースティング回帰器)を設定、チューニングし、効果的な予測モデルを作成していきます。
`create_model` 関数を用いてGradient Boosting Regressorを作成します。
model = create_model('gbr')<実行結果>

この表は、回帰モデルのクロスバリデーション結果を示しています。各行が異なるフォールド(データのサブセット)でのモデルのパフォーマンスを表しており、最後の行は平均値と標準偏差を提供しています。
MAE (Mean Absolute Error): 予測値と実際の値の絶対差の平均です。この値が小さいほど、モデルの予測精度が高いことを示します。
MSE (Mean Squared Error): 予測値と実際の値の差の二乗の平均です。この値も小さいほど良いとされますが、大きな誤差があると特に大きく影響します。
RMSE (Root Mean Squared Error): MSEの平方根で、値のスケールが元のデータと同じで解釈しやすい指標です。
R2 (R-squared): 決定係数とも呼ばれ、モデルがデータのどれくらいを正確に予測できているかを示す指標です。1に近いほど良い性能を示します。
RMSLE (Root Mean Squared Logarithmic Error): 予測値と実際の値の対数を取った上でのRMSEです。対数を取ることで、大きな値と小さな値の誤差が同じように扱われ、特に金額や人口などの指数的に増減するデータに適しています。
MAPE (Mean Absolute Percentage Error): 予測値と実際の値のパーセンテージ差の平均です。この値も小さいほど予測精度が高いことを示します。
結果の解釈
MAE, MSE, RMSE: これらの指標の平均値が低いため、モデルは一貫して誤差が小さいことを示しています。
R2: 平均値が0.8220と高く、モデルがデータの大部分を説明していることを示しています。ただし、R2の標準偏差が0.0557であり、フォールドによってモデルのパフォーマンスが異なることを示しています。
RMSLE, MAPE: これらの指標も一貫して比較的低く、モデルが対数スケールやパーセンテージ誤差の観点からもうまく機能していることを示しています。
3. モデルのチューニング
`tune_model` 関数を用いてハイパーパラメータのチューニングを行います。PyCaretは自動で最適なパラメータを探索してくれます。
tuned_gbr = tune_model(model, optimize='RMSE')<実行結果>

コードの意味
コードの一部分である `tuned_gbr = tune_model(model, optimize='RMSE')` は、PyCaret の `tune_model` 関数を用いて、指定されたモデル(ここでは `model` という変数に代入されているモデルが対象)のハイパーパラメータをチューニングするための処理です。`optimize='RMSE'` という引数は、チューニングの目的として RMSE(Root Mean Squared Error)を最小化することを指示しています。これは、予測誤差の平方根を平均化した値を最小にするようにモデルのパラメータを調整することを意味します。
結果の表の解釈
結果の表は、チューニングされたモデル(tuned_gbr)の10倍のクロスバリデーション結果を示しています。クロスバリデーションでは、データセットを複数のサブセット(ここでは10個のフォールド)に分割し、それぞれのフォールドをテストセットとして使用し、残りをトレーニングセットとして使用します。表には各フォールドでの以下の指標が記載されています:
MAE (Mean Absolute Error): 予測値と実際の値の絶対差の平均。値が小さいほど良い。
MSE (Mean Squared Error): 予測値と実際の値の差の二乗の平均。値が小さいほど良い。
RMSE (Root Mean Squared Error): MSEの平方根。値が小さいほど良い。
R2 (R-squared): モデルがデータのどれくらいを正確に予測できているかを示す。1に近いほど良い。
RMSLE (Root Mean Squared Logarithmic Error): 予測値と実際の値の対数の差の二乗の平方根の平均。値が小さいほど良い。
MAPE (Mean Absolute Percentage Error): 予測値と実際の値のパーセンテージ差の平均。値が小さいほど良い。
結果の評価
平均 MAE, MSE, RMSE: これらの値が全体的に高めであることから、モデルには改善の余地があることが示されています。
平均 R2: 0.7828という値はモデルがデータの78%程度を説明できていることを示していますが、これも改善の余地があります。
平均 RMSLE と MAPE: これらの値も高いですが、特に値が大きいデータや、0に近い値での予測には注意が必要です。
標準偏差
各指標の標準偏差が小さいと、モデルのパフォーマンスが各フォールド間で一貫していることを示します。この場合、標準偏差は比較的小さいため、モデルのパフォーマンスは安定していると言えますが、全体的な性能が改善される必要があります。
4. モデルの評価
`evaluate_model` 関数を用いてモデルの性能を詳細に評価します。
evaluate_model(tuned_gbr)<実行結果>
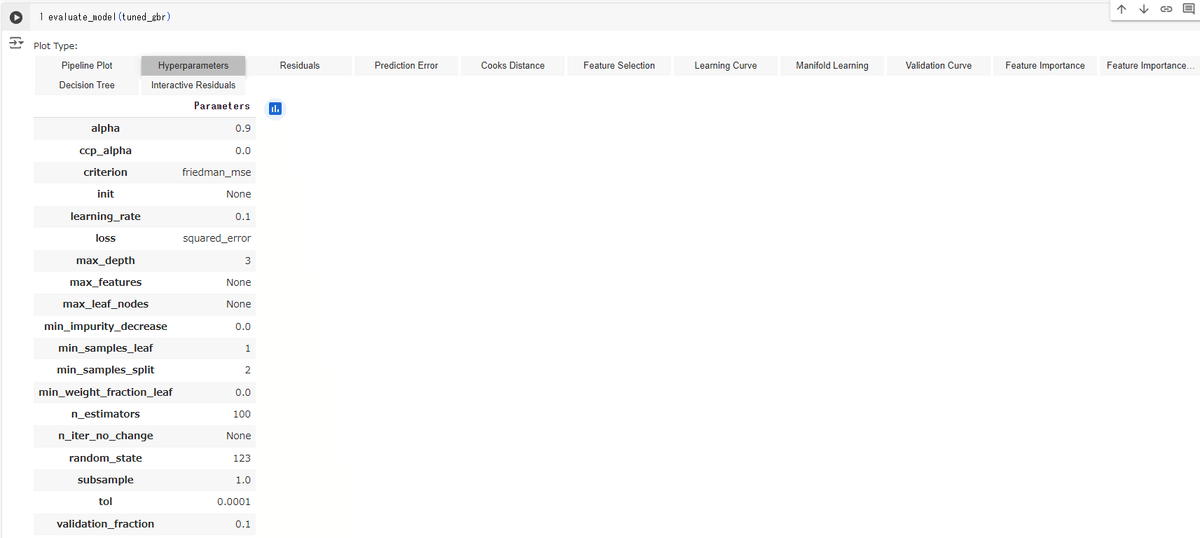
上記は、Gradient Boosting Regressor モデルの評価ダッシュボード内の「Hyperparameters」タブが開かれている様子です。このタブでは、モデルの構成や使用されているハイパーパラメータの値を確認できます。
ハイパーパラメータの説明
alpha: 予測間隔の信頼度を指定します(このコンテキストでは関連が低いかもしれません)。
ccp_alpha: コスト複雑性剪定のパラメータで、木のサイズを制御するために使用されます。
criterion: 分割の品質を測定するために使用される関数で、ここでは「friedman_mse」が使用されています。
init: 初期推定器。Noneが指定されている場合、デフォルトの初期化が行われます。
learning_rate: 各弱学習器の寄与をどれだけ強くするかを指定します。値が大きいほど、学習は速くなりますが、過学習のリスクが増えます。
loss: 最適化する損失関数。ここでは「squared_error」が使われています。
max_depth: 木の最大の深さ。過学習を防ぐために制限されることが多いです。
max_features: 最適な分割を見つける際に考慮する特徴量の数。
max_leaf_nodes: 葉の最大数。制限されている場合、モデルの複雑さが制限されます。
min_impurity_decrease: 分割がこの値以上の不純度減少を引き起こす場合にのみ分割されます。
min_samples_leaf: 葉を形成するのに必要な最小サンプル数。
min_samples_split: ノードを分割するのに必要な最小サンプル数。
min_weight_fraction_leaf: 葉に必要なサンプルの最小加重総数の割合。
n_estimators: 弱学習器(通常は決定木)の数。多いほど予測精度が向上する可能性がありますが、計算コストが高くなります。
random_state: 乱数生成器のシード。同じ数値を使用することで、再現性のある結果が得られます。
subsample: 個々の弱学習器を訓練するために使用するサンプルの割合。
tol: 早期停止のための許容可能な誤差の増加の閾値。
validation_fraction: 早期停止のために保留する検証セットの割合。
結果の解釈
ハイパーパラメータの設定を見ることで、このモデルがどのように訓練されたか、どのような構成であるかが分かります。これらの設定はモデルの学習プロセスや最終的な性能に大きな影響を与えます。例えば、`learning_rate`が0.1と設定されていることから、学習プロセスが比較的標準的な速度で進行してい
ることが示されています。また、`max_depth`が3に設定されていることは、過学習を防ぐためにモデルの複雑さを適度に抑えていることを示しています。
これらの情報を基に、モデルのパフォーマンスを向上させるために、必要に応じて特定のパラメータを調整することが考えられます。例えば、`max_depth`を増やしてみる、`n_estimators`の数を増やしてみる、などの調整が可能です。
5. モデルの最終化
`finalize_model` 関数を使用して、全データを使ってモデルを最終的にトレーニングします。
final_gbr = finalize_model(tuned_gbr)6. 予測
`predict_model` 関数を用いて新しいデータに対する予測を行います。
(unseen_dataは自分で用意してください)
predictions = predict_model(final_gbr, data=unseen_data)7. モデルの保存とロード
モデルをファイルとして保存し、後で使用するためにロードすることができます。
# モデルの保存
save_model(final_gbr, 'final_gbr_model')
# モデルのロード
loaded_gbr = load_model('final_gbr_model')
これで、PyCaretを使用してGradient Boosting Regressorを設定、チューニングし、効果的に予測モデルを作成する一連のプロセスが完了しました。このプロセスを通じて、モデルの性能を最大化し、新しいデータに対する予測を効率的に行うことができます。
まとめ
このガイドでは、PyCaretを使用してサンプルデータセットを分析し、モデルの作成からチューニング、評価、予測までの全プロセスを実行しました。PyCaretの低コードアプローチにより、複雑なデータサイエンスタスクがシンプルでアクセスしやすくなっています。これにより、データサイエンスを学ぶハードルが下がり、さまざまな分野の専門家がデータ駆動の意思決定を行うことが容易になります。
この記事が気に入ったらサポートをしてみませんか?