大量保有報告書に関するEDINET APIのメタデータを共有します(csv)

諸事情あって大量保有報告書関連の書類を集めていますが、2023年のEDINET API改変後から、データの取得に時間がかかるような気がします。EDINET APIから提出書類を保存する際に必要になる作業の1つがドキュメントIDの保存です。
私だけかもしれませんが、EDINET APIのレスポンスステータスがたまに403?になって、有効なリクエストのはずなのに答えを教えてくれないことがあります。
時間をおいてアクセスしても改善しないため、正常な返り値が来るまで何度も時間を空けて待機するプログラムを作成しました。
もちろん書類本体のダウンロードにも時間がかかりますが、あらかじめdoc_idが分かるだけで時短になりますし、APIのアクセス負荷軽減になる(インフラは詳しくないので本当に効果あるかは知らないです)と思いますので、ぜひ使ってみてください。
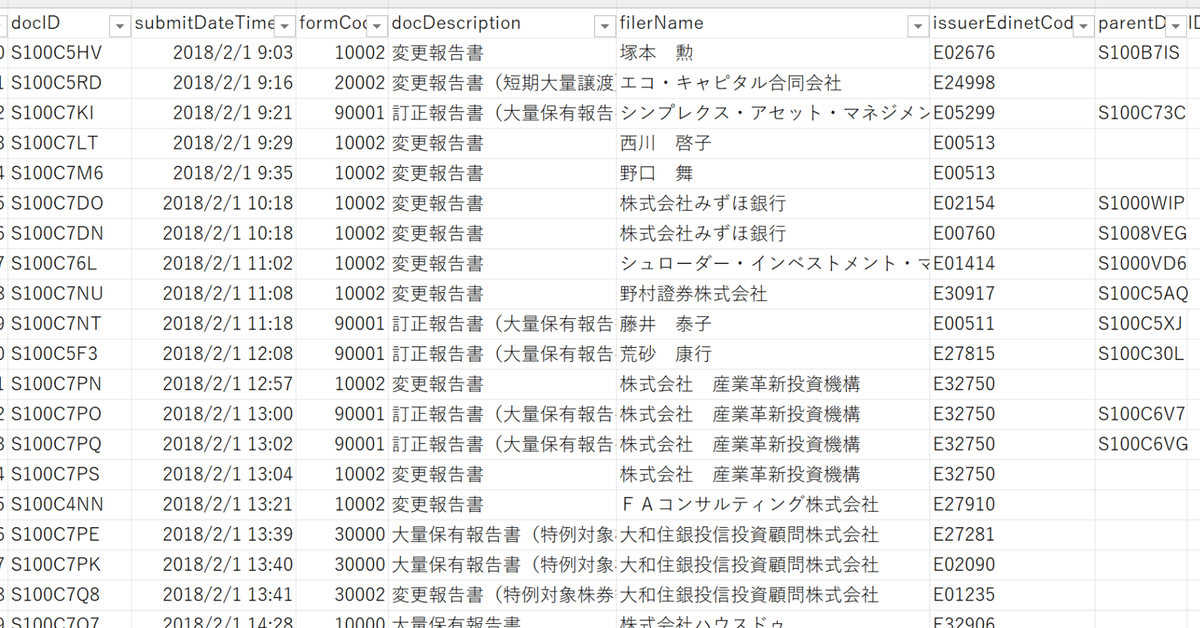
期間:2018年2月1日~2022年12月31日
収録変数:
・docID (EDINET APIから書類本体をDLするときに必要なID)
・submitDateTime(提出時間)
・formCode(様式コード)
・docDescription(書類名)
・filerName(提出者名)
・issuerEdinetCode(発行体EDINETコード)
・parentDocID(親書類コード)
※詳細定義はEDINET API仕様書p.12~
全69,897件
>内訳
・大量保有報告書: 4646件
・変更報告書:26408件
・変更報告書(短期大量譲渡):1517件
・大量保有報告書(特例対象株券等):5869件
・変更報告書(特例対象株券等):22789件
・訂正報告書:8668件

XBRLは読んでいないのでメタデータのみです
実際にメタデータを取得した際のPythonコードも掲示します。
import requests
import datetime
import pandas as pd
import time
from urllib3.exceptions import InsecureRequestWarning
from urllib3 import disable_warnings
disable_warnings(InsecureRequestWarning)
def make_day_list(start_date, end_date):
period = end_date - start_date
period = int(period.days)
day_list = []
for d in range(period):
day = start_date + datetime.timedelta(days=d)
day_list.append(day)
day_list.append(end_date)
return day_list
def make_doc_id_list(day_list):
doc_meta_data_list = []
for index, day in enumerate(day_list):
try:
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
params = {"date": day, "type": 2}
res = requests.get(url, params=params, verify=False)
print(res)
while res.status_code == 403:
time.sleep(5)
res = requests.get(url, params=params, verify=False)
print(res)
if res.status_code != 200:
print(f'response status code other than 200, in {day}')
continue
json_data = res.json()
print(day)
for num in range(len(json_data["results"])):
ordinance_code = json_data["results"][num]["ordinanceCode"]
if ordinance_code == '060': #大量保有報告書全般
# print(json_data['results'][num])
print(json_data["results"][num]["docID"], json_data["results"][num]["docDescription"], json_data["results"][num]["filerName"])
doc_meta_data_list.append([ json_data["results"][num]["docID"],
json_data['results'][num]['submitDateTime'],
json_data['results'][num]['formCode'],
json_data['results'][num]['docDescription'],
json_data['results'][num]['filerName'],
json_data['results'][num]['issuerEdinetCode'],
json_data['results'][num]['parentDocID']
])
except:
pass
return doc_meta_data_list
def main():
start_date = datetime.date(2018, 2, 1)
end_date = datetime.date(2022, 12, 31)
day_list = make_day_list(start_date, end_date)
doc_primary_data_list = make_doc_id_list(day_list)
df = pd.DataFrame(doc_primary_data_list)
# df.to_csv('primary_data.csv', encoding='cp932') #エンコーディングエラー発生するかも
with open("./primary_data.csv", mode="w", encoding="cp932", errors="ignore",newline="") as f:
df.to_csv(f)
if __name__ == "__main__":
main()この記事が気に入ったらサポートをしてみませんか?