
強化学習 Q学習をコードにすると?

こんにちは!
ぷもんです。
前回、Q学習の式を理解するというnoteで
Q学習について、Q学習で使う式について理解しました。
今回はこのQ学習の理解をもとに具体的なコードを理解していきます。
今回やるのはこのコードです。
def get_action(state, action, observation, reward):
next_state = digitize_state(observation)
next_action = np.argmax(q_table[next_state])
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_state
for episode in range(num_episodes):
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps):
env.render()
observation, reward, done, info = env.step(action)
action, state = get_action(state, action, observation, reward)
episode_reward += rewardまずは前半部分のこちらのコードからやっていきます。
def get_action(state, action, observation, reward):
next_state = digitize_state(observation)
next_action = np.argmax(q_table[next_state])
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_state・def〜returnで関数を定義
defとreturnで関数を定義しているのがわかります。
next_actionとnext_stateを返す
get_action(state, action, observation, reward)という関数が定義されています。
def?return?という方は
強化学習に必要な「Qテーブル」と「離散値で表す関数」をつくるには?
で詳しく書いたのでそちらをご覧ください。
続いて、defとreturnの間を見ていきます。
next_state = digitize_state(observation)
next_action = np.argmax(q_table[next_state])next_stateには
強化学習に必要な「Qテーブル」と「離散値で表す関数」をつくるには?
で定義したdigitize_state(observation)の関数が使われています。
この関数はフィードバックで得られる値を4の4乗の256の離散値で表す関数
だったので状態を256の離散値にしていることがわかります。
・np.argmax
np.argmaxは最大値のindex(何番目の要素か?)を返す関数です。
今回はnext_stateのQテーブル(表みたいなもの)
にnp.argmaxが使われているので
状態が1番いいものが何番目の要素なのか?を
出していることがわかります。
・Q学習の式をコードにすると...
続いてはこちらです。
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action]これは前回、Q学習の式を理解するで理解した
Q学習の式のそのままなので
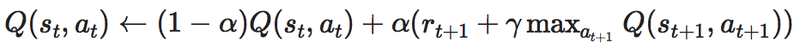
この式に値を当てはめていることがわかります。
この式は
何回も試行錯誤をやってみて
今の状態のQ値と
実際に行動してみて時刻t+1でもらった報酬r_{t+1}と
そのさきにもらえるであろう報酬の最大値であるMAX{Q(s_{t+1}, a_{t+1})}に
割引率γを掛けた値の和
を学習率αで調整しながら足すのを繰り返して
理想の状態に近づけて行く
という意味の式だったので
強化学習がここで行われているのがわかります。
つまり、今見てきた前半部分は
強化学習をしてその結果を返す関数を定義していたことがわかりました。
・意外と簡単な後半部分
続いて後半に入ります。
for episode in range(num_episodes):
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps):
env.render()
observation, reward, done, info = env.step(action)
action, state = get_action(state, action, observation, reward)
episode_reward += reward結構長いですが
実はこれ棒のバランスを取るCartPoleの動かし方 強化学習を始める前に
というnoteでやったCartPoleを動すためのコードとほとんど一緒です。
そのコードがこちら↓。
for episode in range(num_episodes):
observation = env.reset()
episode_reward = 0
for t in range(max_number_of_steps):
env.render()
action = np.random.choice([0, 1])
observation, reward, done, info = env.step(action)
episode_reward += reward
if done:
print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1,
last_time_steps.mean()))
last_time_steps = np.hstack((last_time_steps[1:], [episode_reward]))
break
if (last_time_steps.mean() >= goal_average_steps):
print('Episode %d train agent successfuly!' % episode)
break違うところはこれだけです。
state = digitize_state(observation)
action = np.argmax(q_table[state])
action, state = get_action(state, action, observation, reward)これは先ほどやったものとほとんど同じで
強化学習の要素を追加してCartPoleを動せるようになっていることがわかります。
・つまり...
今回理解したコードでは
・前半部分でQ学習をするための関数を作り
・後半部分でそれを組み込んでCartPoleを動せるようにしている
ことがわかりました。
ここまで長かったですがやっと強化学習が進み始めました。
ただ、ここからさらに調整をしていく必要があるみたいなので頑張ります。
参考にしたサイトはこちらです。
最後まで読んでいただきありがとうございました。
ぷもんでした!
noteを日々投稿してます! もしいいなと思ってもらえたら サポートしてもらえるとありがたいです。 VRやパソコンの設備投資に使わせていただきます。 ご意見、質問等ありましたらコメントください。 #ぷもん でつぶやいてもらえると励みになります。 一緒に頑張りましょう!