
チーム一丸となって開発を行うための技術と施策

Progate Path のチームリード兼テックリードとして働いている島津(*1)です。今回は技術的な側面から Progate Path の開発フローについて共有できたらいいなと思ってこの記事を公開しました。
*1…島津真人は2023年4月よりProgate CTOに就任いたしました。
Progate Path は現在、デザイナー、コンテンツプランナー、エンジニア、あとCEOのマサさん(加藤)で構成されるチームで機能開発・改善が行われています。日々開発・改善を行う中でも特に、デザイナーやコンテンツプランナーも含め全員がプロダクトのコードをさわり、 PR をつくり、直接プロダクトの改善をしていくワークフローを構築していることはこのチームのひとつの特徴かなと思っています。
このワークフローを構築するにあたって、意図的な狙いをもって行った技術選定や施策がありました。今回は Path チームが一丸となって開発できている背景となる、それらの技術や施策について紹介させてもらおうと思います。
開発がめんどくさくないリポジトリとビルドの構成
「めんどくさい」と感じることなくシステムを変更できるようにしていくことでメンバーが積極的に改善を続けられる仕組みをつくれるのではないかと考え、以下のようなことを行っています。
モノレポ構成によるソースコードと演習データの管理
Protocol Buffers と gRPC を利用したコンポーネントをまたいだ情報の共有
Docker Compose を利用したローカルの環境構築
まず、 Progate Path ではすべてのコンポーネントを一つのリポジトリに入れ、モノレポ構成でコードの管理をしています。実際のサービスを提供するシステムのコードに加え、 Progate Path のリポジトリではユーザーさんが触る演習のコードやそれの説明のためのテキストも管理しています。このようなデータをすべて一つのリポジトリに入れることで、サービス全体を簡単に立ち上げることができるようになり、テストやデプロイも一括して行えるような CI/CD を構築することができました。
この構成のおかげで、デザイナーのメンバーがQA中に演習内にちょっとしたタイポや表記違いを見つけたりしたときサッとPRを送ることができるようになったり、逆にコンテンツ開発時に Lint の設定を開発リポジトリから参考にしてきたりなど、ちょっとした変更を普段触っている領域にとどまらず低コストで入れられるようになっています。
また、 Progate Path では API 、 CLI 、 Web という大きく分けて3つのコンポーネントで構成されていますが、これらはすべて gRPC で通信しています。 Protocol Buffer は記法もわかりやすく、後方互換性があり、各言語のバインディングと型定義が簡単に生成できるためフィールドの追加や削除の影響がビルド時にわかるため、管理コストが低くなります。 また、 proto ファイルにはできる限りコメントを書くようにすることで、各 API に関するマスタードキュメントをそこで一元管理するような運用をしています。

また、複数のコンポーネントの環境構築や立ち上げを一括で行うため、 Docker Compose を利用しています。モノレポの利点を活かし、 docker-compose up を叩けば一通りのサービスが動くようにした結果、ローカルでの QA がしやすくなりました。
ただ、この部分に関してはホストのボリュームマウントをするとファイルのパーミッションの扱いが難しいという問題があるため、より良い方法がないか引き続き模索しています。
継続してスピーディーな開発が行える体制の構築
Progate Path は initial commit からちょうど1年たち、少しずつ規模が大きくなっていくにつれて開発速度を徐々に意識しなければならなくなってきました。ここでは以下に挙げたような、開発当初から意識していた開発速度に関する施策や、最近はじめた取り組みなどについて紹介しようと思います。
Feature Flag を用いたトランクベース開発
微妙に異なる多数の演習コードの管理とテスト
DevEx week の実施と継続的な積み残し解消デーの設定
Progate Path ではスピーディーに仮説検証を行っていくため、 Feature Flag を用いたトランクベースな開発フローを実践しています。
たとえば新しい UI への変更を行うような例を考えてみましょう。一つのブランチで機能開発を行い、完成してからマージするワークフローだと、新しい機能を入れた際のQAが大変になったり、別の機能修正を入れづらくなるといった問題が発生します。
一方で Feature Flag を利用すると、ユーザーさんに影響が出ないように新機能をフラグで囲うことで、小分けにしたPRをどんどん main ブランチにマージしていくことができます。さらに、 QA する際も開発メンバーにのみ機能を有効にすることができ、さらにそのまま A/B テストを開始したり、段階的にローンチしてみたりといったロールアウト方法を取ることができます。
Progate Path では、開発メンバーの少ない中でも並行してどんどん開発を進めており、それぞれの機能を独立して開発・リリースできる Feature Flag は役に立っています。

また、この Feature Flag の仕組みはサービスのためのコードだけではなく、ユーザーさんが演習で触れるコードを生成するのにも活用されています。
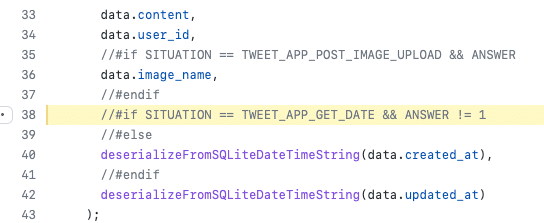
演習で提供しているソースコードは各演習の問題設定に合わせ、ほとんど同じだけど細部が微妙に異なるバリアントが複数存在するという特徴があります。そのため、単純に各演習で別々にコードを管理してしまうとベースの部分に修正を加えるたびにすべてのコードに同じ変更を適用しなければならず、演習が増えるにつれて開発負荷が上がっていくという問題がありました。
そこで Progate Path では、ユーザーさんが演習で扱うことになるプロジェクトのソースコードをフラグによって分岐できるようにしました。フラグによってソースコードを出し分けられるツールを作成し、ビルドステップを挟むことで単一のプロジェクトから複数の演習のコードを生成することができます。
さらに、このフラグの機能をつかって各演習の想定解もリポジトリに入れると、各演習の公開コードと想定解コードを生成できるようになります。これをつかって、公開コードと想定解コードの両方を生成して CI でテストを行うようなジョブを開発しています。公開時には期待通りにいくつかのテストが落ち、逆に想定解ではすべてのテストが通ることを確認できるようにする予定です。
もうひとつ、ゼロイチのフェーズでスピーディーな開発に関するトピックとして、「まだ開発が始まってから日が浅いし、しばらくは機能開発を優先していきたい」という誘惑についてここで取り上げようかなと思います。
開発をスピーディーに進め続けるためには早い段階から継続して開発者体験(Developer Experience)の向上に時間を割いていくのが大事、というのを頭では理解していたものの、現実には各自がメインのタスクをこなしており、その中で実際に行動に移すのは容易ではありませんでした。そんな中、これまで Path チームではどのように DevEx に関して進めてきたかを紹介します。
最初に意識的に DevEx について時間をとるきっかけとなったのは、 Progate Path でα版を少数のユーザーさんに試していただいたときでした。このときはα版開始までは実際に触っていただくサービスを作り上げるのに忙しかったのですが、その反動もあり、テストのカバレッジが十分でないことや、パッケージのバージョンアップに関してあまり意識が向いていないことが近々問題になりそうだというのを感じていました。そこで、α版開始から実際にユーザーさんからフィードバックを得られるまでに見つけた少しの時間で次の開発タスクを始めるのではなく、「DevEx week」という、開発体験に関わるタスクをメインのタスクとする期間を1週間ほど設けてみることにしました。
この DevEx week では、テスト追加に関するガイドラインの策定、Renovate による継続的なパッケージバージョンアップ、E2Eテストの設定とサンプルテストの追加、デプロイパイプラインの整理といった、なるべく長期に渡って継続的な効果を得られるようなタスクをチーム総出でこなすようにしました。この結果として普段の業務フローの中に継続的に DevEx の改善が組み込まれるようになり、テストの数も継続的に向上し、これまで目立ったリグレッションなくβテストをすすめることができています。
また、このような動きを引き続き行っていくため現在もチーム内では毎週金曜日を積み残し解消デーとして、各自やりたいと思っているけど手がでていないタスクをこなすよう推奨してみたり、後でやりたいタスクにラベルをつけてみたりと試行錯誤しています。

客観的なデータに基づいた意思決定
また、 Progate Path はまだまだ仮説検証を進めていくフェーズということもあり、ユーザーさんからのフィードバックや演習にまつわる各種行動がプロダクトの改善のためにとても貴重な情報源となっています。今回クローズドβを展開していくにあたり採用した方法として、1テーブルに全部のイベントを入れるという方法を紹介します。
Progate Path では現在、各種イベントを一つのテーブルに入れ、 Firehose を通して BigQuery に集約し、 Redash や Google Colab を用いてデータを解析するという方法を取っています。
BigQuery ではスキーマを定義する必要がありますが、スキーマとしては全イベントに付与されるタイムスタンプなどのパラメーターの他に、 type という文字列と params という文字列を用意しています。この params には type に対応した JSON が文字列として格納されていて、必要に応じてビューを作ることでクエリしやすいようにしています。
この構成の最も大きなメリットは、事前にスキーマを細かく決めておく必要がないという点です。試行錯誤の過程が記録されていくイベントログでは、スキーマが細かく決まっていることよりも、システムの更新に合わせて柔軟にデータを記録したり、取り出したりすることができるようにするほうが重要です。
そこで、今回 Progate Path では API サーバーにイベントを送信し、これを JSON にしてバックエンドに投げるような仕組みを作っています。データのインフラに全く手を加えることなく、アプリケーションにシンプルな JSON encoder をひとつつくるだけでログの種類をどんどん追加できるようになっています。

今後解決していきたい課題
ここまでは、これまでに行ってきた様々な施策について紹介しましたが、最後にこれから解いていきたい未解決の課題も一部紹介させてもらいたいと思います。
Docker の macOS と Linux での挙動の違い
積み残し解消デーをスムーズに回すための仕組みづくり
サービスの監視の強化
Progate Path では現在 macOS 上で開発を行っていますが、 CI/CD は Linux 上で動作しています。このため Docker Compose をどちらでも動作するようにしなければなりませんが、ホストのボリュームマウントに関する挙動の違いがあるため、ビルドの環境の検討が必要になっています。
また、積み残し解消デーに関していうと、実際に積み残しタスクに取り組むためには事前に何をやるか明確に見える状態にしておかないと、週1日で効果的にタスクをこなすのは難しいという課題があります。タスクにラベルをつける、週1日ではなくて頻度を下げて期間を伸ばすなどの改善のアイデアを出しつつ、試行錯誤している最中です。
他にも、監視の仕組みがまだ完全には整っていないというものもあります。New Relicを導入してシステム全体の監視をしようとしていますが、まだ外形監視といった仕組みが導入できているわけではありません。プロダクトのローンチなどにつれて徐々に監視体制の強化を行っていきたいと考えていますが、どのタイミングでどれくらい準備すればよいのか、優先順位付けは常に難しい課題となっています。
まとめ
今回の記事では、技術選定や施策という側面から、チーム一丸となって開発できるようにしていくために行っていることを紹介してみました。チーム全体で開発できる体制をつくり、継続していくのはとても重要なことだと考えています。
プロダクトをチーム一丸となって育てていくのに少しでも興味を持っていただけた方、課題の解決方法に興味を持っていただいた方などいらっしゃれば、ぜひ気軽に声をかけてくださいね。
島津のMeetyや他記事はこちら
この記事が気に入ったらサポートをしてみませんか?