画像学習の過程を可視化する

先日、ワッシャーみたいな部品の検査を目視でやっても、人によって良し悪し違うし、そもそもこれ部品の検査ではなく視力検査なのでは。。。?
などと、末端の兵隊なりにいろいろと思うところがあったので、文句たれててもしゃーねーし、いい方法探すかと思って、いい方法探したら、ありました。
しかも日本語で。
自分の場合は、自動化起案したら早々にリジェクトされたので、自分だけでも楽をできたらいいやと思って、上のコードを実装してみました。
んで、学習済みのモデルを使っての転移学習なので、大して労することなくうまく行ったものの、学習の過程がテキストだと素人にはよくわからん。
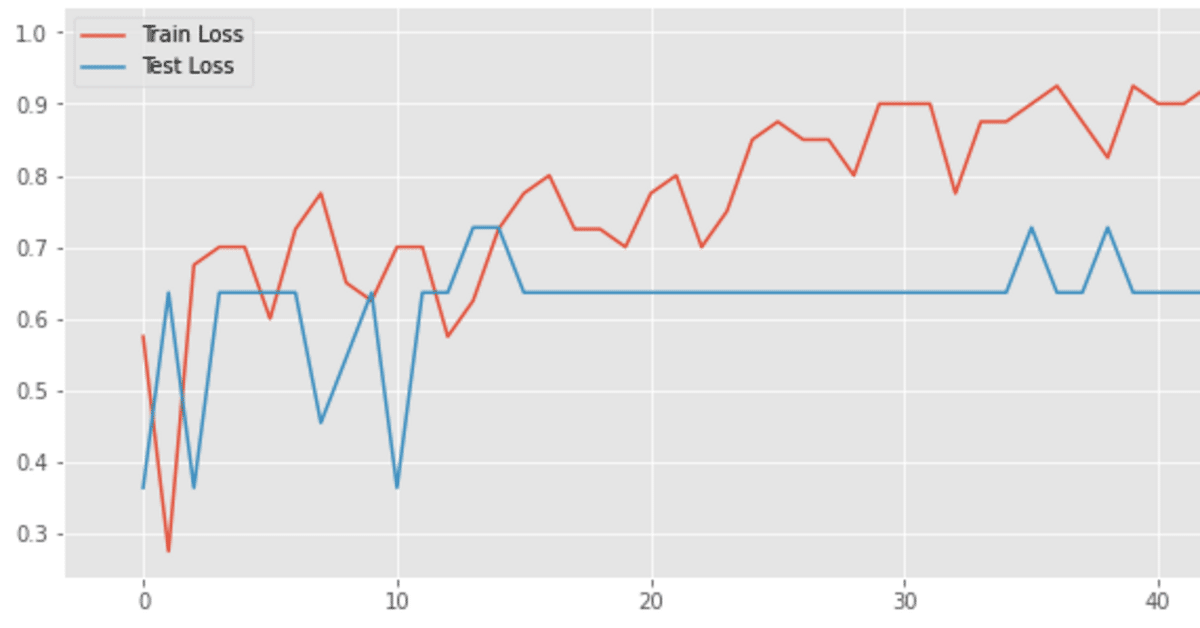
history = model.fit(X_train, y_train, batch_size=16, epochs=64, validation_data=(X_test, y_test), validation_batch_size = 8)そこで、先のコードにちょっと味付けして、プロセスを可視化してみた。
plt.style.use('ggplot')
def history_plot(history_model):
fig,ax = plt.subplots(1,1,figsize = (15,5))
ax.set_title('Loss Function')
ax.plot(history_model.history['accuracy'],label = "Train Loss")
ax.plot(history_model.history['val_accuracy'],label = "Test Loss")
ax.legend()
plt.savefig('loss_function.png')
hplot = history_plot(history)可視化してみたところ、なんとまぁ分かりやすいことに過学習しているではありませんか。。。元の記事の人が早くに止めていた理由がわかりますね。
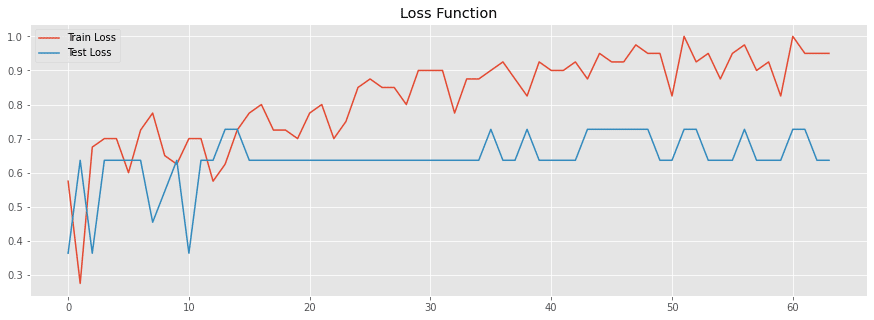
そんなときには学習を早い段階で止めたデータも呼び出せるEarlyStoppingを使うことができます。
from tensorflow.keras.callbacks import EarlyStopping
early_stop = EarlyStopping(patience=3,
restore_best_weights=True,
monitor='val_loss')
early_history = earlymodel.fit(X_train,
y_train,
batch_size = 16,
epochs=64,
validation_data=(X_test,y_test),
validation_batch_size = 8,
callbacks = [early_stop])
early_hplot = history_plot(early_history)過学習は抑制できたものの、元データの数が少なすぎるせいかそもそも精度が悪い。
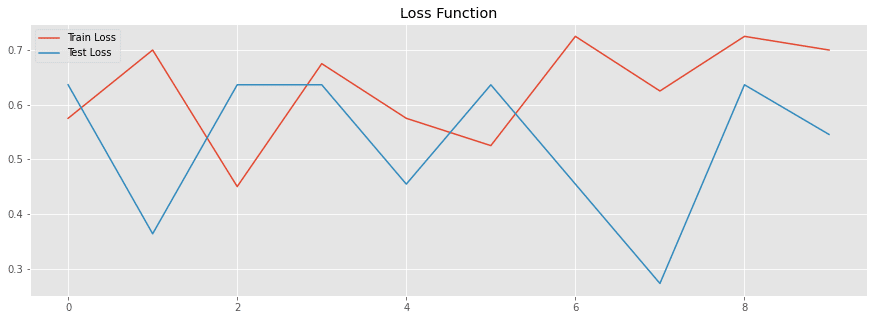
というわけで、次回は、元データの数が少ないなら、画像生成で増やしてしまえばいいじゃないということで、パチもん画像を画像生成で300枚くらい一気に増やしてみた内容を記事にします。
この記事が気に入ったらサポートをしてみませんか?