
自社システムをHerokuからGCPにリプレースした話 -全体像 前編-

株式会社YOJO Technologies」から「PharmaX株式会社」へ社名変更いたしました。この記事は社名変更前にリリースしたものになります。
開発のbonです。
弊社では6/12に既存事業のLINEを用いた漢方・サプリのサブスクリプションサービスであるYOJOのシステム基盤を、HerokuからGCPへとリプレースしました。
実は以前の投稿(※)でHerokuの全体像をご紹介したのはここに至る伏線だったのです。
※以前の投稿はこちらです
※今回の記事は割と壮大な記事ですのでご了承ください……。
全体スケジュールは以下のとおりです。
・2022/4某日 発案→承認
・2022/4 要件固め&スケジュール調整→検証・実装
・2022/5 検証・実装
・2022/6 本番移行前作業を消化しつつ12日に正式リプレース
・現在 安定稼働中
4月上旬に発案からの承認を得て、4月中旬からチームとして要件とスケジュール決めをしました。その後は6/12まで検証と実装を繰り返してリプレース作業を完遂しました。
リプレース前のアーキテクチャ構成図(一部)と機能紹介
リリース前のアーキテクチャはこんな感じです。
Vercel、Cloud Run、Herokuと多種多様なクラウドサービスを利用して、いい感じに運用していました。
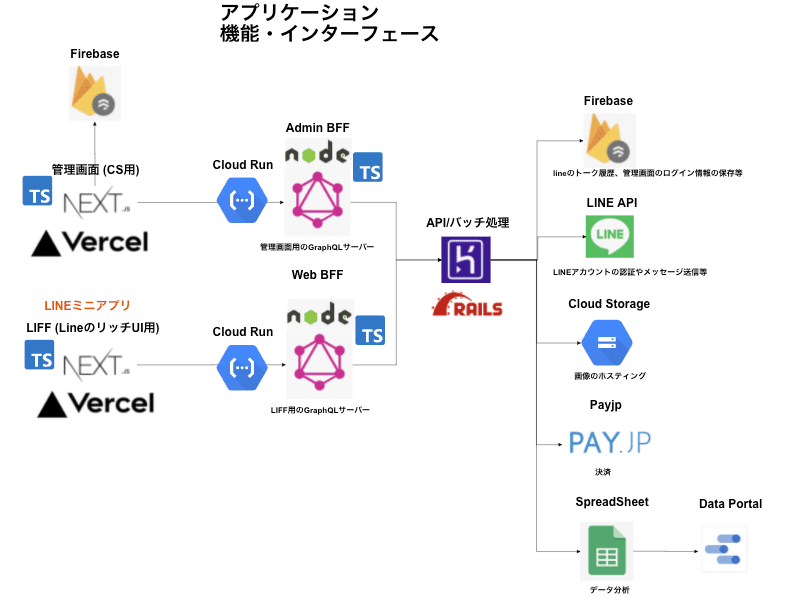
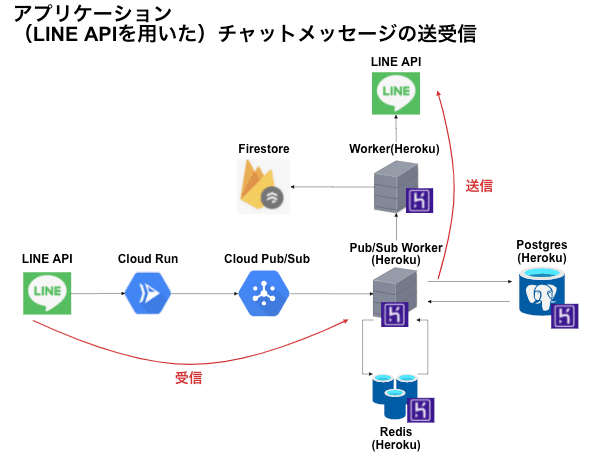
弊社のサービスは、LINEと弊社の管理システムとをつなぎ患者さんと薬剤師とのコミュニケーションを管理することと、患者さん向けにサブスクリプションでの漢方・サプリメントの販売が主な機能です。
LINEからの患者さんのメッセージは一度Cloud Run経由でCloud Pub/Subにキューイングし、それをHerokuに配備されたSubscriber用のサービスが取りにいきメッセージを処理します。この処理中で特定のメッセージについてはBotが返信するようにしています。それ以外のメッセージは基本的にはFirebaseへ書き込みされ、薬剤師が利用する管理画面にリアルタイムに反映されます。(一部のデータはPostgreSQLにも保存)
このコミュニケーション管理システムにより、薬剤師は薬局店舗内でも自宅でも、あるいは旅行先でも患者さんとコミュニケーションを取ることが可能です。そのため、弊社ではこのシステムを利用している薬剤師のことをリモート薬剤師と呼称しています。
リプレースに至る経緯
そもそも、サービス基盤をまるっとリプレースしてしまおうと至る経緯はなんだったのかというと以下のとおりです。
DBがパブリックに公開されておりセキュリティ的に厳しくなってきた
コストパフォーマンスが割に合わなくなってきた
Herokuの技術を尖らせるより現代的クラウドネイティブに乗っかりたかった
まずHerokuでは、Enterprise契約以外でAdd-Onで追加したDBはパブリック公開されます。そのため、特定の顧客データを扱うようなサービスの場合、通常プライベートネットワークを持つオンプレミスの環境やクラウドサービスにおけるシステム運用よりも高いセキュリティリスクを持つことになります。事実弊社のDBも毎日ブルートフォース攻撃を受けていました。
次にコストパフォーマンスの問題です。YOJOのサービスはtoC向けなので、広告掲載やSNSのバズりのタイミングでサービスへの流入がスパイクすることがありました。その都度Herokuのサーバーを増強したりAdd-Onをスケールアップしたりしていました。しかし、特定のAdd-On(例えばDB)はスケールダウンができないものもあり、Herokuのサーバー自体も今後も手動でやり続けるかというとそれも大変です。もちろんさまざまな監視を作ってHeroku CLIを組めば、KubernetesのReplicaSetのようにコンテナ管理を自動化できるのかもしれません。とはいえ、そこに技術を投入するよりは今後確実に必要となるクラウドネイティブな技術を習得したほうが、スキル面でもエンジニアのキャリアにつながり運用コストも成長の糧になると思っていました。
まとめると以下のような感じです。
コストパフォーマンスを考慮した場合サービスがうまくいくにつれて考えるべきことがどんどん増える
↓
プロダクトに割く開発のリソースが減る
↓
コストパフォーマンスのバランスが崩れていく
↓
開発がつらい
加えて、現状では複数のクラウドサービスを併用していることで、通信経路が多岐に渡ることによるサービスのスループットに影響を与えており、コストパフォーマンスに見合わなくなってきていました。
そして弊社に入社してから私がびっくりしたことの1つだったのが、エンジニアがほぼログを見ないことでした。ログにはさまざまなシステム運用上の効率化や改善のヒントが眠っており、不具合の原因調査においても、どういうトランザクションやリクエストで何が起きたのかを明確にする上で不可欠なはずです。しかし、リプレース前のアーキテクチャ構成の影響でログが断片的になってしまっていることと、Papertrailというログ機能では精度の高いログ調査が困難(見づらい、探しづらい)という課題があり、エラーを上手く特定できません。そのため、エラー管理ツールのSentryに検知されたエラーログを見ながらなんとか原因を特定するというマンパワーで乗り切るという状況でした。
まずはログ集約基盤のツールでも入れるなり統一するなり、ログをすべて一箇所に集約&可視化し調査をしやすくするだけで、運用・保守のコストを削減できるのではないか……と個人的に思っていました。
最後にHerokuをやめる判断についてです。
Herokuでのサービス展開は初期フェーズではかなり有用な手段だと思う一方で、順調にスケールしていくサービスをHeroku上でうまく運用するための技術を磨くことには若干違和感がありました。Herokuの大規模サービス運用自体がニッチなスキル過ぎてインターネット上にも参考になる情報があまりなく、あっても古い情報(2016年)だったからです。
また、主要クラウドサービスベンダー配下にサービスを配置したほうが技術的にも新しいことにチャレンジしやすいはずです。弊社開発組織としても、主用のクラウドサービスを使ったほうがメリットは大きいと判断し、リプレースを決断しました。
あと、個人的には貧乏性なので「絶対にHerokuを使っていた頃よりも運用費を安くしてやる」という思いもありました。(確約できないのであくまで個人の野心でしたが……結果は後ほど)
今回のプロジェクトで意思決定したこと
ここからは、この成功プロジェクトを進める上でどういうことをやってきたかをプロジェクトマネジメントの観点で述べていきます。開発の話題がないためつまらないかもしれませんが、汎用性・再現性は少なからずあると思うため、ぜひご自身のプロジェクトに活用いただけると幸いです。
患者満足度世界一のために、顧客影響を最小限に抑える施策を検討
まずリプレースプロジェクトについて事業責任者へ提案したところ、すんなり承認を得たことで本格的に進めざるを得なくなりました。(本当はこっそり時間を見つけて調査→移行のシミュレーションをしたかった)
プロジェクトメンバーはこんな感じです。
プロジェクト専任メンバー 2人(私を含む)
他プロジェクト兼任メンバー 3人
計5人
プロジェクト発足後、すぐにリプレース先のクラウドサービスをどこにするかを検討しました。とりあえず既に弊社として利用実績のあったAWS、GCPのいずれかで良さそうだなと思い、全メンバーとキックオフを兼ねてリリースの大まかな方針を議論。リプレース後の画像を見ていただくと分かるように、リプレース先はGCPに決定しました。主な決定理由は以下のとおりです。
既存サービスの一部がすでにGCP管理下にあったから
BigQuery利用コストが削減できそうだから
リプレース前のアーキテクチャ図を見ていただくと分かるように、すでにいくつかの機能はGCP管理下。AWSとのマルチクラウド構成は学習コストも管理コストも増えてしまうので、現状の開発組織の人数規模や各メンバーのスキルに鑑みてGCPに統一するほうが良いと考えました。
またBigQueryについては副次的なものにはなりますが、GCPに集約することで弊社はすでに活用していた分析基盤であるBigQueryへのデータの流れをGCP内部で完結させることができるようになります。Herokuからのデータ取得をAirbyteでBigQueryへ転送していたのをごっそり削除できるので、この観点でもメリットがありました。
GCPへのリプレースを決定したところで、次はどうやっていくかを皆で検討。最初に私が考えたのが「データベースだけプライベートネットワークに移行する」という案です。作業が楽なのと、最初に挙げた課題の1つであるDBのセキュリティ確保をサクッと解決できるため、我ながら良い案だと思いメンバーに提案したところ、「どうせシステム停止を伴うのであれば、一気にサービスまるごと移行したほうが顧客影響も最小限に抑えられるのでは?」というフィードバックを受けました。
そこで私は気づかされるわけです。
弊社のミッションが「患者満足度世界一」であるということを。
患者満足度を考慮すれば、サービス停止は1回でかつ最小限の停止時間に留めるほうが確かに良いだろうと判断し、サービス全体の移行をプロジェクトのスコープとし、スケジュール化することにしました。これについてはリスクの面でも、たとえ切り戻しが発生したとしてもDNSの切り替えと、不運にも生まれてしまったDB差分を手作業で復旧するだけでなんとかなるので、大きな問題ではないと判断。
もちろん無停止でのリプレースがベストではあるのですが、DNSを切り替える必要がある=数分のダウンタイムはどうしても発生してしまう……ということから、顧客流入の少ない深夜帯に作業を行うことで顧客影響を最小限に抑えようと考えました。
さらにリプレース中は顧客のLINEからのメッセージや流入そのものはGoogle Cloud Pub/Subにメッセージキューとしてしばらく残し、処理しない状態を維持しておけばリプレース後に処理可能だろうということで、システム停止
の順序も工夫しました。(詳しくは多分別記事で書きます)
現状維持で頑張らないリプレースを目指す
次に各種サービスをどのGCPのサービスで動かすかを検討しました。GKEというKubernetes環境がGCPにはありますが、弊社ではインフラ専任の担当者は不在、サービスの規模的にGKEで管理するような高トラフィック・トランザクションが常時発生するわけではないため、今回はコンテナベースでのリプレースを検討し、Cloud Runを利用することにしました。
また、プロジェクトでやらないこと(意識しないこと)も勝手に決定。それがこの2つです。
今以上の可用性・信頼性を確保すること
アプリ実装の大幅リファクタリング
私の無駄に長いITの経験上、エンジニアは仕事が楽しくなったり、チャレンジや未知の課題と向き合ったときにモチベーションが上がったりという一方で、そこに多大な時間を割こうとします。「俺の考えた最強のXX」を実現するために、最高のパフォーマンスと全力思考で課題に向き合っているため問題というわけではないのですが、今回のプロジェクトにおいては短期決戦と当初の目的を優先し、「システムの非機能要件・機能要件は現状維持のまま環境を移す→そこから新たな取り組みとしてエンジニア的発展を目指す」ことに努めました。つまり楽しいチャレンジングな内容は残しつつも、可能な限り不要な課題や不確実な要素を削ぎ落とす……ということです。
ここの意思決定により、先述したCloudinaryの移行を一旦先送り。Add-Onではなく直接契約し直すところからスタートとなるため余計な時間がかかってしまう&データ移行が面倒だからです。
同じようにScoutもAdd-Onのまま利用して継続してパフォーマンスを取ることができれば、新旧でのパフォーマンスや信頼性の対比が可能なため、あえてそのままにしています。将来的にはScoutに備わっているErrors Monitoringの機能が使いたいため個別契約したいと思っています。(これがあればSentryはいらなくなるはず)
とはいえ例えば、リプレースのときにインフラのIaCをTerraformで実現し、構造化してもらったり、コンテナデプロイの並列化のためにDBマイグレーションの制御を入れたりなど、必要最小限の最適化は実施しました。これらについてもそのうち記事になると思いますのでお楽しみに。
この記事が気に入ったらサポートをしてみませんか?