
自社システムをHerokuからGCPにリプレースした話 -全体像 後編-

株式会社YOJO Technologies」から「PharmaX株式会社」へ社名変更いたしました。この記事は社名変更前にリリースしたものになります。
開発のbonです。
前回の記事(※)ではGCPへのリプレースについて現状と経緯をお話しました。今回はプロジェクトをどう進めてきたかや、戦略・意思決定のプロセスなどをマネジメント観点でお伝えしようかと思います。リプレースに関わる細かい実装上の話や技術的な話は別記事で書いてもらう予定です。
※前回の記事はこちら
リプレースのスケジュール
再掲になりますがプロジェクトの全体スケジュールは以下のとおりです。
・2022/4某日 発案→承認
・2022/4 要件固め&スケジュール調整→検証・実装
・2022/5 検証・実装
・2022/6 本番移行前作業を消化しつつ12日に正式リプレース
・現在 安定稼働中
4月上旬に発案からの承認を得て、4月中旬からチームとして要件とスケジュール決めをしました。その後は6/12まで検証と実装を繰り返してリプレース作業を完遂しました。
リプレース前後のアーキテクチャ構成図
再掲になりますが、リリース前のアーキテクチャは以下の通りです。

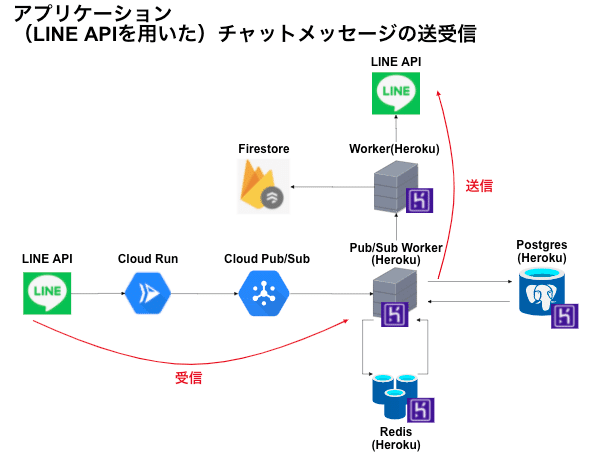
このアーキテクチャがリプレース後はきれいにすべてGCPに移行できました。

ただし、以下の記事にも書いているようにHerokuで利用していた画像配信サービスのCloudinaryとパフォーマンス管理ツールのScoutだけは、リプレース後もそのまま利用しています。理由は後述します。
リプレース後の結果
リプレースの結果を先に述べておきます。まず課題の再掲です。
DBがパブリックに公開されておりセキュリティ的に厳しくなってきた
コストパフォーマンスが割に合わなくなってきた
Herokuの技術を尖らせるより現代的クラウドネイティブに乗っかりたかった
ログを使った不具合調査の効率化
最初の課題のDBについては、アーキテクチャ図で示したとおりプライベートなサブネットに配置しました。グローバルIPすら付与していないため外部からの疎通は一切不可能です。ただし、リードレプリカはBigQueryとの疎通を優先するためにグローバルIPの付与とUSリージョンという特殊構成にはなっています。とはいえリードレプリカ側からのマスターDBサブネットへの疎通はGCPのインフラが突破されない限りはできないはずなので、ひとまず十分なセキュリティを確保することができました。
次にコストパフォーマンスについてです。システムのパフォーマンス可視化についてはパフォーマンス管理ツールのScoutを利用します。Scoutは定期的にサーバーのパフォーマンスデータ(画面描画にかかる時間や内部処理の実行時間の内訳など)を計測・収集してくれるため、特に何もしなくともシステムを使っていれば勝手にデータが溜まっていきます。
リプレース前と後でパフォーマンスを比較したかったので、以下のようにリプレース日の前後2日間のバックエンドサーバーのパフォーマンスデータを期間指定で可視化しました。

リプレース日が2022/6/12で、画像中心左寄りの突出した棒グラフあたりです。
リプレース作業が完了したのは2022/6/13の深夜2時ごろでした。画像中央右側の棒グラフが見えなくなっているところあたりです。劇的なパフォーマンス改善を達成していることがわかります。
フロントエンド(実際に薬剤師が利用する管理画面)は画面全体の描画速度を2秒程度縮めることができました。
また、リプレース後数週間、各種Cloud RunのCPU、メモリ、コンテナ数などのメトリクスをGCP側で収集し、それぞれの数値を6/17に変更しました。その結果、リプレース後のパフォーマンスを維持しつつHerokuで稼働していたときよりも20,000円〜40,000円/月のコスト削減を実現することができました。このコストにはBI分析と検証機のコストを含んでいませんが、もしかするともっとコストダウンできている可能性もあります。
というわけで、リプレースにより十分なコストパフォーマンスの最適化を実現できたのではないかと考えています。
次にクラウドネイティブへの乗っかりという点ではGCPをフルに活用するクラウドインフラ構成へリプレースしたことで、今後GCPのさまざまな恩恵を受けることもできるようになり、インフラは監視・アラート検知以外はTerraformでIaCを実現しているため変更管理も容易になりました。チームメンバーもTerraformのスキルやリプレース時の考慮点、リプレース手順など新しい経験を積めたのではないでしょうか。
最後に、個人的な課題でもあったログ調査についてもCloud RunがCloud Loggingにすべてのログを勝手に転送してくれるため、時系列でログを追うことがめちゃくちゃ簡単になりました。さらにGCPのGUI上からログ調査するにあたりクエリを使ったり時間の範囲を絞ったりすることで検索も楽になりました。体感ではエラーの発生原因を特定するのに10分かからないくらいです。以前はSentryを見る人に依頼→コードを見る→推測する……という流れだったため、時間云々以前の問題ですね。生産性、保守性どちらをとっても十分な改善だといえます。
なお、プロジェクトはほぼほぼオンスケでのリリースを完遂しています。リプレース中・リプレース後のトラブルは10件くらいでしたが、どれも顧客影響の小さいものだったので、総合して悪いところが1つもない珍しく成功したと胸を張って言えるプロジェクトとなりました。チームの皆さん、お疲れさまでした!
次章からは実際にプロジェクトを進める上でやったマネジメントについて書いていきます。
見積もりとスケジューリング
作業が決まったら次にやることといえば見積もりです。しかし、我々メンバーはGCPのすべてを知っているわけではありません。そこで、すでにHerokuからGCPへリプレースした事例を探すことにしました。
Jiraで見積もりとスケジュールを可視化
最初に見つけたのが、HerokuからGKEへの移行方法について書かれたGoogleの公式ドキュメントです。弊社ではCloud Runへの置き換えを検討していたため参考程度に留めました。(特にDBの移行まわり)
次に見つけたのがSmartHR社のリプレースの事例を紹介したクラスメソッド社の記事でした。弊社でもほぼそのまま使えそうな情報が記載されていたので、こちらを参考に作業を洗い出しました。
作業の洗い出しについては、弊社で利用しているJira Cloudと、その拡張機能であるAdvanced Roadmapsを使いました。利用した理由は各作業の依存関係の可視化や親タスクと子タスクの可視化を一元的に行いたかったためです。Jiraの課題を作成しまくって、それらを並べると……

こんな感じでスケジュールをWBSっぽくすることができます。少し画像からは分かりにくいかもしれませんが、依存関係にあるタスクを線で結ぶことでタスクAが終わらないとタスクBは開始できない……という状況を可視化することもできました。
ちなみにこのスケジュール表は、日々変わりゆく状況を見つめながら私が都度アップデートしたものなので、プロジェクト開始時に作成したものとは若干タスクの数、日程にズレがあります。
当初はリリース日を2022年5月末に置いていたため、そこから逆算しておおよそこのくらいあれば大丈夫だろう……という線を作成しました。足りない作業があれば都度課題を追加→スケジュール作成という流れで進めたことで、スクラムではない独自アジャイル開発みたいなプロジェクトスタイルになりました。
アジャイルによるスケジュール管理
アジャイルするためにはスクラムを使わなければならない……!というわけではありません。今回のように、ウォーターフォール開発で使われるWBSだけでも十分にアジャイル開発は可能です。
例えば弊社では、大型リリースをするときは最低でも3日前に社内連携し、各部署に何かしらの対応の是非や顧客対応マニュアル修正の可否、業務変更点洗い出しなどがないかをチェックしてもらう必要があります。他の企業でも似たようなフローがあると思います。
今回のプロジェクトでは日々の作業量を観測し、消化したタスク数を把握することで、リリース日がいつ頃になりそうかをおおよそ把握できるようにしていました。
これを実現するのがスクラムで使われるSP(ストーリーポイント)です。例えば1週間に完了できたSPが10であれば、全体で30SPのプロジェクトは3週間で完了することができるという計算です。追加で10SPほどバッファを見越してあげれば、大体のスケジュールを想定することが可能です。今回のプロジェクトでもSPを参考にスケジュールの調整をしました。
ただし、SPは相対的な見積もりなので、あまりにも毛色の違う作業のSPには気を遣わなければなりません(例えば採用と実装はおそらくSP 3の度合いがまったく違うはずです)。また同じSPでも人によって消化できる速度は違うため、メンバーの増減も注意が必要です。このあたりについてはチームで共通認識を持つようにしましょう。
……と、なんだかんだ良い感じのことを述べてみましたが、実際のところ本プロジェクトにおいては作業実施日が遅延しようが早まろうが顧客影響さえ最小限に抑えることができれば開発コスト増以外のデメリットは発生しません。そのため、事業としてそこまでリリース日の前後にこだわりがなかった、というのが真実だったりします(笑)
つまりリプレース系のプロジェクトは、プロジェクトマネジメントの勉強や新しい取り組みの仮説検証の場としてかなり有用だということです。ぜひ新任のPMさんは手を上げて取り組んでみてください。
会議体の設計
スケジュールを作成したあとは、実際に作業をする上でどういう会議をし、どういうドキュメントを作るかを決めました。(弊社ではドキュメントにNotionを利用しています)
会議体の設計は前職の知見を余すことなく利用し、週次ミーティングの議事録をテンプレ化しました。
参加者
タイムテーブル
・作業進捗共有
・課題、TODO確認
重大な進捗(マイルストーンを見逃してないかどうか)
共有したいこと(テーブルで起票者、内容、決まったことを定義)
課題・TODO(開発に関わるタスクはJiraに起票、事務系タスクはTODOボードを作ってそっちで管理)
毎週のミーティングの1日前に作成し、各メンバーおよびGoogleカレンダーの説明欄で事前共有しておきます。
重大な進捗は、実際はあまり使いませんでした。というのも、ここに何かしら書かれるときは「予定以上の進捗がでたとき」か「遅延が明確になりそうなとき」のどっちかしかないからです。少数メンバーの場合コミュニケーションで解決できてしまいます。
共有したいことは各人が共有したい内容を書き込む場所で、困っていることだったりメンバーと会話せずに意思決定したことだったり、今すぐ決めたいことだったりさまざまです。
TODOについては、毎週の議事録で共通のTODOボードをNotionのDatabase機能を使って共有することで前回のTODOの対応漏れや全体進捗を簡単に管理できるようにしました。
ドキュメントの方針
次にドキュメントの方針ですが、自分では良い整理法が思いつかなかったのでNotionのTemplateを利用することに……。
とはいえ、結局ドキュメントのディレクトリ分けの明確な基準が分からなかったので、大幅に内容を削って以下のような方針としました。
ディレクトリAには成果物を置く
ディレクトリBには調べたことや方針、仕様、要件整理などを雑多に書いたドキュメントを置く
必ず結論をドキュメントの冒頭に記載する
プロジェクトで決まった色々な意思決定は雑多なドキュメントの方(ディレクトリB)を見ればわかり、実際のリプレース作業で決まった内容やリプレース時の作業については成果物(ディレクトリA)を見ればOK!という感じです。
また、雑多なドキュメントについては実際の決定内容や仕様との差分はある程度許容することで「まずはとにかく書く」という点を意識しました。ドキュメントが存在しない場合、経緯を知らないエンジニアが過去の意思決定や仕様決定の背景を想像しながら0から書くという苦行をしなくて良いだけでも、かなりのメリットがあるはずです。
逆に成果物はここだけ見たらある程度の方針とプロジェクトで何をやったかが正確にわかるよう、都度内容を私が精査しました。
テストについて
リプレース作業で一番ネックになるのは、おそらくテスト範囲ではないでしょうか。
軽く考えるだけでも全網羅テスト(結合・総合テスト)、性能テスト、負荷テスト、連携テストがあるでしょう。テスト設計だけでも大量の時間を消費してしまいます。
今回のプロジェクトではスケジュール的にかなり後工程にこの作業を積んでいたこともあり、主に私が困りました。
そのとき、おぼろげながら浮かんできたんです。「リファクタリングがあった箇所と、リプレースにするにあたって発生した環境間での挙動の違いだけテストすればいいのではないだろうか」という案が。

早速リプレースで発生するであろう環境差分を以下のように洗い出しました。

その結果、テストケースはかなり絞れて10個程度まで減らすことができました。テストが万が一漏れたとしても検知できるように、Cloud Loggingとログベースの指標に対してアラート監視、エラー検知の設定も色々実施したのが下図です。

なお、上記のテスト観点のうちデータ分析については、BIチームと連携しつつ実装修正とテスト依頼して対応し、性能の検証については現状のメモリ使用率や平均リクエスト数を算出して対応しました。
最後に
長々とインフラリプレースプロジェクトにおいてやったこと・考えたことについて書いてきましたが、一番重要視したことは「顧客影響をどれだけ下げることができるか」です。
たとえGCPに完全リプレースできたとしても、弊社のエンジニアだけがうれしいようなサービスではまったく意味がありません。リプレースの経緯自体は弊社のシステムを提供する上での問題でしたが、これらの問題を解消した先にあるのは顧客満足度世界一という弊社のミッションです。
この意識をメンバー全員が持っていたことで、リプレースの方針を考えるうえでもリスクはあるがミッションに沿った選択ができたと思っています。(例えば完全なサービス停止時間をどれだけ短くできるかや、さまざまな実装方針の議論でも顧客影響を少なくするための方針は何か……など)
久しぶりにトラブルも少なく、自分としても少し余裕のあったプロジェクトでした。改めて、メンバーの皆さんありがとうございました。
今回のプロジェクトに興味を持っていただけた方、YOJOって面白そう、Apexやりたいという方がいらっしゃたら、ぜひカジュアルにお話しましょう!
この記事が気に入ったらサポートをしてみませんか?