
PharmaXのデータ基盤と今後の展望

はじめに
はじめまして。2021年の6月からPharmaXのBI (Business Intelligence) チームでデータエンジニアとして働いている 古家 (@enzerubank) です。
突然ですが、みなさんデータ基盤を開発したことはありますか?
私はPharmaXに来るまではなく、社内にも知見のあるメンバーがいなかったため、技術責任者の上野と一緒に学びながら、四苦八苦して作り上げていきました。
本記事ではデータ基盤の構築についてここ半年くらいで試行錯誤したことを振り返っていきたいと思います。
従来のデータ基盤(構想段階)
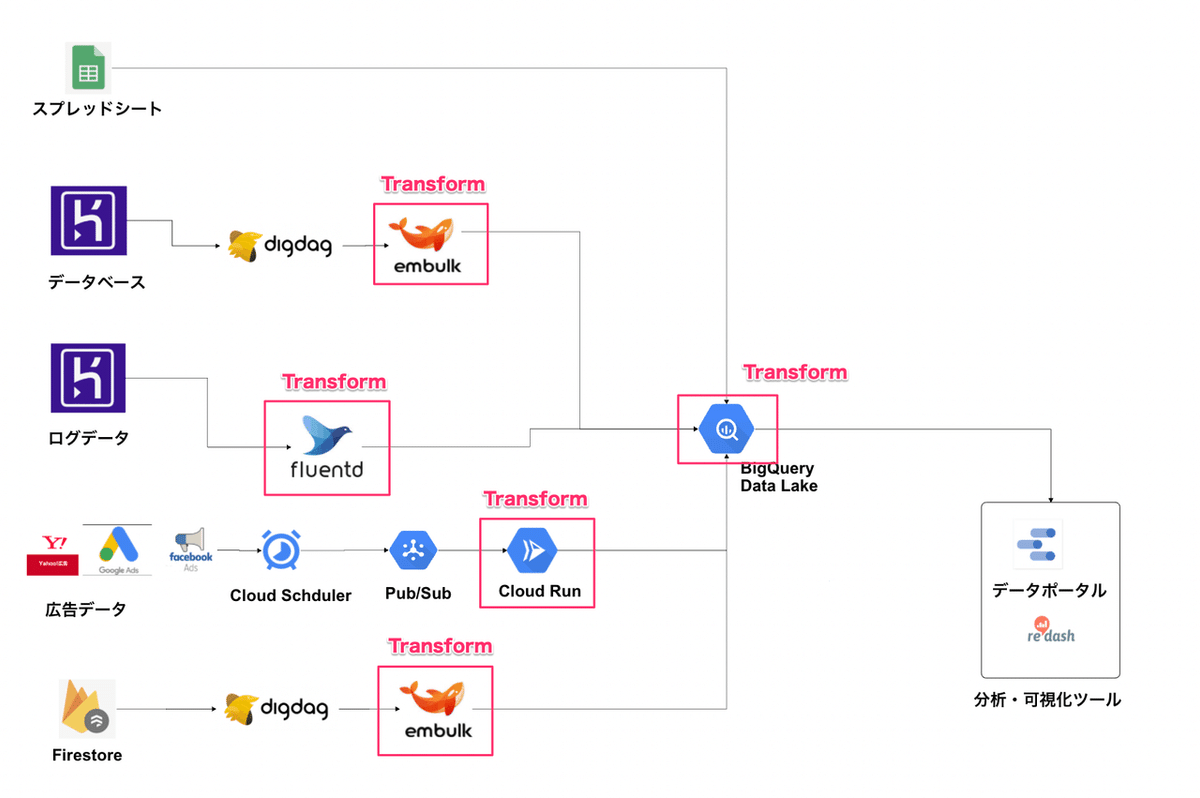
私がジョインした時に構想されていたデータ基盤がこちらでした。

スプレッドシートはBigQueryの外部テーブルのデータソースとして、スケジュールクエリで更新するような構成です。
広告データに関してはBigQueryに直接転送する方法が見つからなかったため、Cloud Run上に各種APIを実行するNodeアプリケーションをデプロイし、Cloud Scheduelrで定期実行しようと考えました。
ログデータはHerokuのログドレインを使ってsyslogの内容をfluentdを経由してBigQueryに転送するような構成で、データベースとFirestoreはDigdag+Embulkを用いて収集する想定でした。
しかし、上記のデータ基盤を実際に構築し始めた所、すぐにさまざまな問題に直面することになります。
3つの問題と解決策の振り返り
問題1:データ変換処理の分散化
スプレッドシートの更新をスケジュールクエリで行っていた所、エラーが出るようになりました。
元のスプレッドシートでは日付の形式を「2022/01/01 10:00:00」のようにスラッシュ区切りで入力していたのですが、BigQueryの日付はハイフン区切りでないと認識してくれません。
そのため元データを直してもらうかBigQueryで変換処理を行うためのスケジュールクエリをまた別途で書かないといけなくなります。
そうするとスプレッドシートの数が増えていればいくほど、ワークフローの管理が困難になることがわかってきました。
また今回のデータパイプラインはETLを想定していますが、データ変換処理 (Transform) を行うとすると、Embulk、Cloud Run (Nodeアプリ)、fluentd、スケジュールクエリの4つの異なる記法を覚えて、それぞれ処理を書かないといけなくなります。
実質稼働できるデータエンジニアは私しかおらす、それでは保守も引き継ぎも困難になる課題がありました。
解決策
この問題の解決には加工処理を転送中に行うのではなく、転送後に行うELT基盤に変更しました。
EL処理はAirbyteとtroccoで行い、T処理はdbtに役割分担をしています。
BigQueryは4層構造を採用していて、データレイクとして生データが保存されたRaw/Typeデータセットを元に再利用に便利な単位でデータを横付けしたテーブルを作るWarehouseデータセット、そして可視化用の最終成果物をMartデータセットとしています。
これにより変換処理を全てdbtに集約することができるようになり、課題として上がっていた変換処理の分散化は解消することが出来ました。

問題2:データパイプラインのワークフロー管理
従来の構成だとデータパイプラインのワークフロー管理はDigdag×2、Cloud Scheduler、スケジュールクエリの4箇所で行うようになっており、いつ何のデータが更新されるのかの順番を追いづらいという課題がありました。

解決策
この問題に対しては、ELTパイプラインのLoad処理をAirbyteとtroccoの2つに集約することで解決しました。
AirbyteはOSSのETLツールです。内部ではdbtで動作しており、自作のdbtを実行することも可能です。YOJOではtype、warehouseへの変換のdbtもAirbyteから呼び出すようにしています。
troccoはAirbyteがサポートしていない国内の広告サービスも対応しているのと、エンジニア以外のメンバーでも設定しやすいUIから採用しています。
まだワークフロー管理が2つに別れていますが、以前に比べると大分理解がしやすくなりました。

問題3:手作業によるインフラ構築の負債化
必要なインフラもGCP上に構築しているのですが、元々はBigQueryや各サーバーも担当のエンジニアがGUI画面から作成やSSHしてコマンド実行して進めていました。
十分なドキュメントも残されていなかったため、後から入ってきたメンバーがまったく仕様を把握できず引き継ぎも出来ないという問題が発生していました。
またIAM権限の管理も適切に行われておらず、正社員は全員編集者ロールを持っているというような状態で、誰かがミスをしたら環境が壊れるというリスクも持っていました。
解決策

この問題の解決には、GCPのプロジェクト・IAMアカウントの発行・IAM権限の設定を全てTerraformでIaC化することで対応しました。
また、GCPのプロジェクトではTerraform用のサービスアカウントのみオーナー権限を持たせることで、他のメンバーが追加・変更を加えることのできない状態にしました。
これによりtfファイルさえ見れば、使われているリソースと権限がひと目でわかるようになり、後続のメンバーに引き継ぎを行うことが出来るようになりました。
またCI/CDとしては5人までは無料で利用することができ、手軽にTerraformの運用を開始できるという理由から、Terraform Cloudを採用しています。
データ基盤の今後の展望
ここ半年くらいのデータ基盤構築の取り組みについて紹介してきました。
同時に社内でのデータ分析の啓蒙活動も進めており、BigQueryのWAUは平均7〜8人ほどになりました。今後さらに増やしていけるよう需要を掘り起こしていきます。
まだまだデータ基盤としては課題は沢山あり、2022年にトライしていきたいことはいくつもあります。ざっと考えていることは以下の通りです。
・データモデリングの推進
・BigQueryの4層構造の見直し
・データソースの拡充
・Redashの廃止
・SLA・SLOの管理、評価の開始
最後に、BIチームは現在2人チームでチームメンバーを募集中です!やりたいことは多いもののまったく手が足りていない状況ですのでぜひお気軽にお声掛けください。