
3日でLLMのPoCを個人で作った時にやったこと

こんにちは。PharmaXのエンジニアの古家(@enzerubank)です!
普段PharmaXではスクラムマスターをやったり、Webフロントエンドのテックリードをやったりしています。
今回は個人でLLMのPoCを作った時にやったことについてまとめたいと思います。マネージャーなどでLLMについて自分で手を動かしてみて学びたいと思っている人の参考になれば幸いです。
長いので読み飛ばして興味のある項目だけ読んでもらえればと思います。
なぜPoCを作ろうと思ったのか
PharmaXの開発チームでは2023年に重点的に取り組む技術戦略・コアコンピテンシーの一つとして「ChatGPTを始めとする生成AI/LLM関連技術の実戦投入」を掲げています。弊社開発チームの技術戦略・コアコンピテンシーに関しての詳細はこちらの記事をご確認ください。
LLMチームが社内に立ち上がり、R&D的に検証を行っており、そろそろ本格的にプロダクトに実践投入していく段階に入っています。そんな中で自分自身はまだLLMを使って動くものを作ったことがなかったため、やれることの解像度を高めるためにPoCを作ってみようと考えました。
Day1 (要件定義〜事例調査)
インセプションデッキを作成

一人開発ですが、まず要求(やりたいこと)を整理するため、簡易的なインセプションデッキを書くことにしました。
今回はサジェスト機能の作り方を試してみたかったため、読書データを元におすすめの本を教えてくれるツールを作ることにしました。

個人開発の場合、やらないことを決めることは大事です。リソースは限られているため、理想形を作り切るのは現実的ではありません。
今回の目的は、立派なプロダクトを作るというより、PoCなので最低限CLIで投げた質問に対しておすすめの本を返答してくれる所を作れればOKです。
あとは後々、アプリケーションへの実装を考えた時に組み込み方のイメージが湧くようになればよいとしました。

あとは期間とトレードオフスライダーを決めました。今回3日間で確保できる時間は朝活をがんばっても最大13時間だと分かっていたため、さきほど決めた最低限のスコープがとりあえず動くレベルでOKとしました。
ここで決めたトレードオフスライダーが開発を始めてからの判断基準に非常に役立ちました。やっぱり判断基準を明示化しておくのは大事ですね。
ユーザーストーリーとユースケースを記述

ユーザーストーリーは「要求仕様を自然言語で簡潔に表したもの」です。1つ目がプロダクト要求で、2つ目はプロダクトには関係ないですが、今回のPoCプロジェクトの目的を達成するには不可欠なため、ビジネス要求的なものになります。
タイトルを簡潔にするため、仕事でもユーザーストーリーの背景や目的はチケットの詳細欄に記入する運用にしているため、タイトルは「xxxとしてyyyできる」という形式にしてます。
今回の3日間では、上記程度でやりたいことが箇条書きされていれば十分なため、これ以上は書きませんでした。

ユースケースは「ユーザー(アクター)とシステムのやり取りを定義したもの」です。今回はプロダクト要求は1つしかなく、ユースケースも1つしかないですね。
本来だと、ここでシーケンス図も合わせて書いておくことで、後のシステム設計を行いやすくするのですが、そもそも今回は解像度が低い状態で行っているため、シーケンス図は書きませんでした。
事例調査
要件定義のフォーマットや企画のアイデアを考えたりしていたら、何だかんだで時間を使ってしまったため、Day1の残り時間は事例調査に使うことにしました。
自分がやりたいことをネットで検索し、似たようなことをやっていそうな人を探していきました。今思うと、いきなり具体的な事例を調べるところから入ってしまい、そもそもLlamaIndexやOpen AIで何で、どういう時に、どう使えばいいのかが理解できていませんでした。
2日目の前提知識の学習を1日目のメインにしてもよかったなと思いました。
参考にした記事
Day2 (前提知識の学習〜技術調査)
2日目は開発に入る前に、LLMの概要・大枠を知るために自分がわからないことを順にインターネットで検索して調べていきました。
自分の中で大枠が構造化できていると、読書や実際に手を動かしながら、詳細を学ぶ時に効率的にインプットできるためです。
インプット内容の詳細について書いていると文量が長くなりすぎてしまうため、項目のみ以下に並べてみました。これらの項目を上から順に学んでいけば、AIについて詳しくない人でも全体感は見えてくるかと思います。
インプットした項目
AI、機械学習、深層学習の関係
AI、自然言語処理、LLMの関係
CNN、RNN、Transformerの概要
BERTとGPTといったLLMの概要
ファインチューニング・プロンプトエンジニアリングの概要
LlamaIndexの概要
ここまでの事前学習で読書AIを作るためにはLlamaIndexを経由してオススメの本に関するテキストデータをベクトル化 & ローカルに保存し、そこに対してクエリを実行すれば作れそうだなということがわかったため、Day3から実際に手を動かしていきました。
Day3 (設計〜実装)
前提知識の学習でDay2まで時間を使ってしまったため、実装はサンプルコードをそのまま動かして理解度を高める程度にすることにしました。この時、インセプションデッキで作ったトレードオフスライダーが役に立ちましたね。
使用技術・実装方針の決定
長々と前提知識を調べてきましたが、今回作りたい読書AIをCLIで動かしたいだけであれば、LlamaIndexだけ使えれば十分です。独自データをインデックス化してクエリを叩くだけなので、今回は特にプロンプトをこだわったりとかはしないことにしました。構成は以下です。
使用技術
開発環境
Google Colaboratory
言語
Python
DB
Notion
ライブラリ
LlamaIndex
実装
実装したコードは以下のようになりました。
import os
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = "XXXXXX"
os.environ["NOTION_INTEGRATION_TOKEN"] = "XXXXX"
!pip install llama-index
from llama_index import LLMPredictor, ServiceContext, download_loader, GPTVectorStoreIndex, load_index_from_storage, StorageContext
from langchain.chat_models import ChatOpenAI
# gpt-3.5-turbo を指定
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor = llm_predictor)
# Notion Loaderの設定
NotionPageReader = download_loader('NotionPageReader')
integration_token = os.getenv("NOTION_INTEGRATION_TOKEN")
reader = NotionPageReader(integration_token=integration_token)
# データベースIDから子ページのページIDを取得
page_ids = reader.query_database("XXXXXXXXXXXXXXXXXXXX")
# 取得したpage_idsを出力
print(page_ids)
# Notionのデータの読み込み
documents = reader.load_data(page_ids=page_ids)
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
index.storage_context.persist()
# indexの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
answer = query_engine.query("SREを学ぶオススメの本はありますか?またその本の概要を教えてください")
print(answer)処理の流れとしては、以下のようになっています。LlamaIndexが外部データとLLMの仲介を色々とやってくれていることがわかりますね。
Notionの指定DBの各ページから本のテキストデータを取得
GPTVectorStoreIndexで本のテキストデータを読み込み、Open AI APIに問い合わせを行い、Embeddings(文章をコンピュータが計算できるようにベクトル化したもの)のデータを取得
上記の情報を格納したインデックスファイルを作成
質問文のEmbeddingsをOpen AI APIから取得
インデックスファイル内の各ノードを検索し、関連性の高いノードを抽出
抽出したノード内のテキストを参照しながら、Open AI APIへ問い合わせを実行
Open AI APIの返答を元に最終的な内容を表示
PoCの結果
実際作ってみたPoCを使って、質問をしてみました。
まずSREについてのオススメ本を聞いた時の例。これはいい感じにSRE関連で書かれていた本をNotionから抽出して返答してきてくれています。
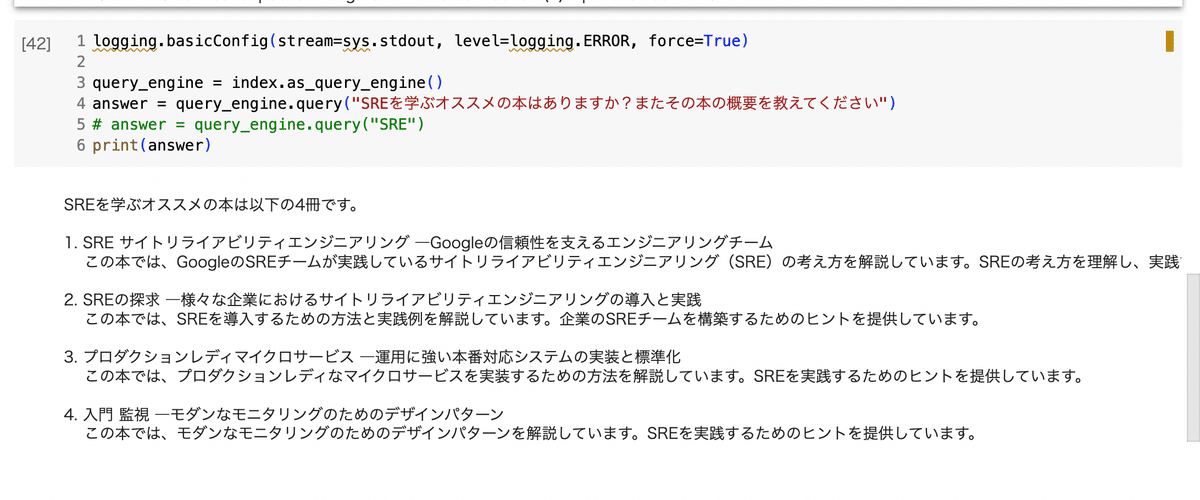
ちなみにNotion側はインフラ系の本をまとめるページになっていて、SREはこんな感じで書かれていました。

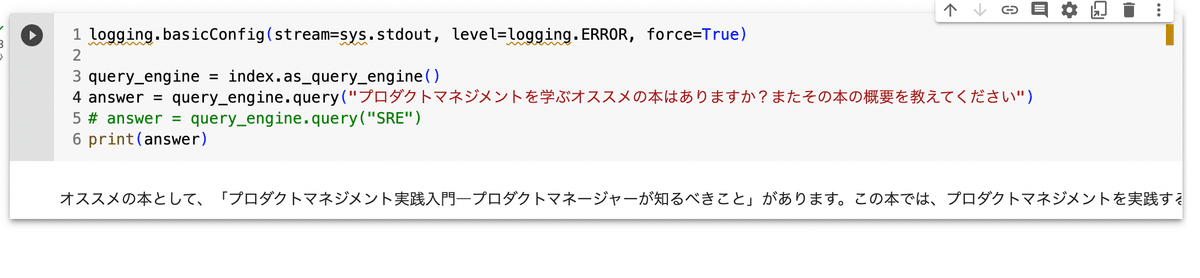
次にプロダクトマネジメントの本について聞いてみました。
この場合は完全に嘘の情報を返してきてますね(笑) こんな本はないですし、Notionにも書かれていません。
Notion側では、プロダクトマネジメントはマネジメント系として以下のようにまとめられてました。マネジメントという言葉が色々な箇所で使われていて、類似性の判断がしづらいのかもしれません。この辺りはチューニングしていきたいですね。

今回のPoCを通して、最低限のスコープとしていた「本のレコメンドをCLIで出す」「アプリケーションへの組み込み方の解像度を高める」は達成することができました。

まとめ
今回はLlamaIndexを使ってNotionをDBとしてLLMから返答を受け取るPoCを作るまでの過程をふりかえってきました。
外部データをLLMと連携させる方法はわかったため、次のステップとしてはよりこちらが返してほしい回答を得られるようにチューニングしていくことをやっていきたいと思っています。
例えば、Notionの元データをタイトル・本文で分離して類似度の判定が変わるかどうかを試したり、返答の文章例をin-context learningして同じようなフォーマットで返してもらったりなどを考えています。
この辺りの実験管理の過程やよりOpen AIのAPIの詳細について説明した記事についてはまた書ければと思います。
終わりに
PharmaXの採用情報について、こちらで随時更新しております。
もし少しでも興味をお持ちいただけ方がいらしたら、ぜひカジュアルにお話ししましょう!