
【LlamaIndex🦙✨】Notionのデータベースからindexを作成する

はじめに
この記事は、LlamaIndex(旧GPT Index)のNotion Loaderを使用して、Notionのデータベースを読み込んでindexを作成する方法を紹介します!
※技術に関する解説は行いません🙇
今回使用するのは、Llama HubにアップされているNotion Loaderです。
ソースコードなど詳細はこちらからご覧ください⏬
準備
Python実行環境(Google ColabでOKです)
Open AIのAPIキー
Notion
インテグレーションの作成(APIトークン取得)
indexを作成するページへのコネクトの追加
データベースIDの取得
Notion インテグレーションの作成
Notion Loaderは、Notion APIを利用するためインテグレーションを作成する必要があります。
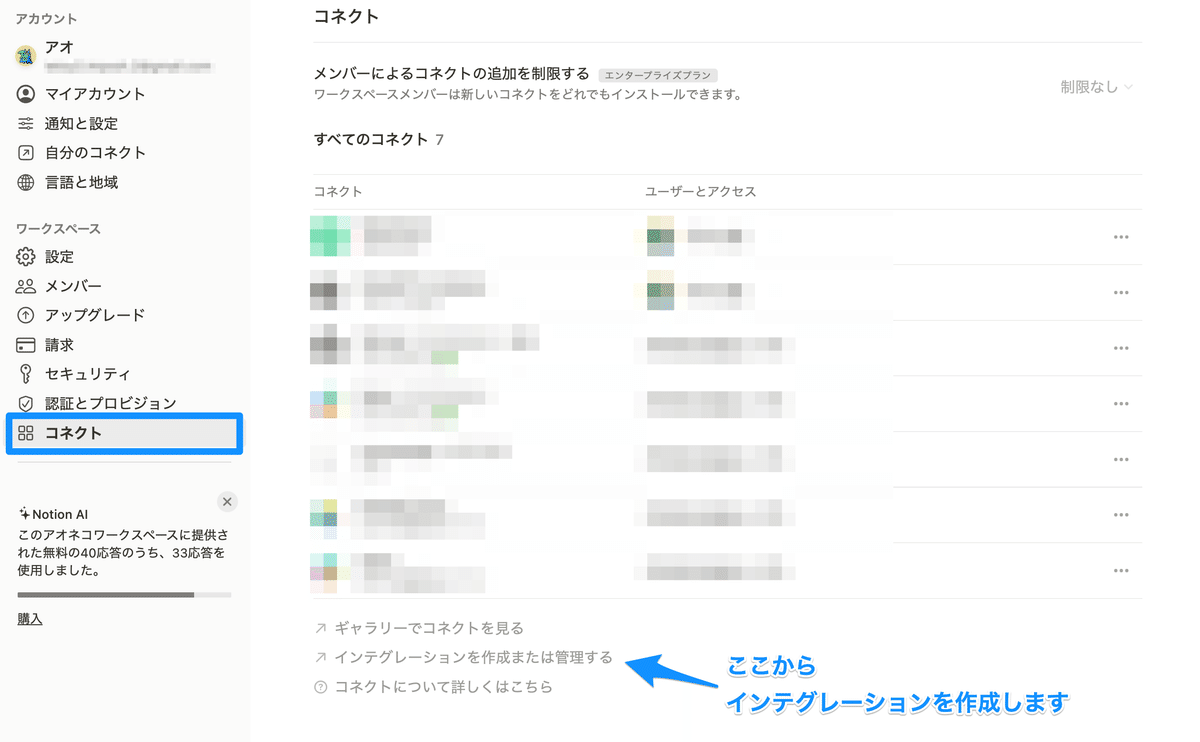
下部にある「インテグレーションを作成または管理する」をクリックしてください。
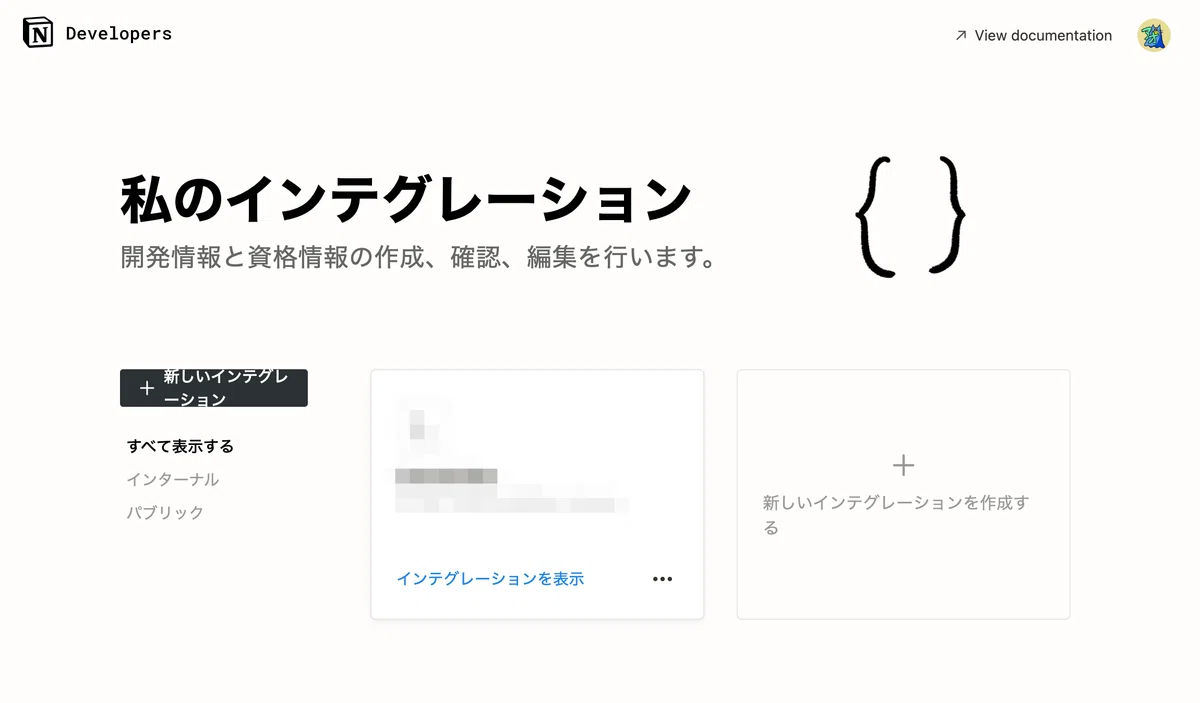


コピーをし忘れてしまっても後で表示できるのでご安心ください!
Notion ページコネクトの追加

先ほど作成したインテグレーションを選択します。
※検索でヒットしない場合は、Notionアプリを再起動すると読み込まれます。
Notion データベースIDの取得
今回は、データベースを読み込んでindexを作成するため、NotionのデータベースIDを取得します。

https://www.notion.so/{データベースID}?xxxxx
今回使用するのは、{データベースID}の部分です。
以上でNotion側での準備は完了です!
使用するNotionデータベースサンプル
今回は子ページが4つ格納されているデータベースを使用します。
これをもとにindexを作成して、質問してみたいと思います!

Google Colab
まずは環境変数の設定を行います。
Open AIのAPIキーと先ほど取得したNotionインテグレーショントークンをセットします。
import os
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = "Open AIのAPIキーをセット"
os.environ["NOTION_INTEGRATION_TOKEN"] = "Notionのインテグレーショントークンをセット"次にログを出力するための設定を行います。
(不要な場合は設定しなくてOKです)
import logging
import sys
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)LlamaIndexをインストールしてください。
!pip install llama-index以下のモジュールをインポートしてください。
from llama_index import LLMPredictor, ServiceContext, download_loader, GPTVectorStoreIndex
from langchain.chat_models import ChatOpenAIgpt-3.5-turboを使用するように設定を行います。
# gpt-3.5-turbo を指定
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor = llm_predictor)Notion Loaderの設定を行います。
# Notion Loaderの設定
NotionPageReader = download_loader('NotionPageReader')
integration_token = os.getenv("NOTION_INTEGRATION_TOKEN")
reader = NotionPageReader(integration_token=integration_token)Notion Loaderのquery_databaseメソッドを使用して、データベースIDから子ページのIDを取得します。
# データベースIDから子ページのページIDを取得
page_ids = reader.query_database("NotionのデータベースIDをセット")取得したページIDを確認してみましょう!
IDが4つ取得できています。
# 取得したpage_idsを出力
print(page_ids)
['cb5db955-351f-48c5-8751-edc8dd7aef76', '958453a2-e5f9-42e6-96bd-eba6acee8624', 'ed48e33e-31ab-4a82-b821-b8fe1908f8b8', '9c76e186-4f23-44c8-956f-28f9cd71dcc7']取得したページを読み込みます。
# Notionのデータの読み込み
documents = reader.load_data(page_ids=page_ids)documentsの中身を確認してみましょう。
import pprint
pp = pprint.PrettyPrinter(indent=4) # インデントを4スペースに設定
pp.pprint(documents)
[ Document(text='件名:【キャンペーン名】開催中!お得な特典をお見逃しなく\n'
'ご担当者様\n'
'いつも当サイトをご利用いただき、ありがとうございます。この度、【キャンペーン名】を開催いたします。この機会に、お得な特典をぜひご活用ください。\n'
'■キャンペーン概要\n'
'期間:【開催期間】\n'
'対象商品:【対象商品名】\n'
'特典内容:【特典内容】\n'
'詳細については、以下のリンク先をご確認ください。\n'
'【キャンペーンページURL】\n'
'また、当サイトでは、【キャンペーン名】以外にも、さまざまな商品やサービスを取り揃えております。ぜひ、ご覧くださいませ。\n'
'何かご不明な点がございましたら、お気軽にお問い合わせください。\n'
'今後とも、当サイトをよろしくお願い申し上げます。\n'
'敬具\n'
'【会社名】\n'
'【担当者名】',
doc_id='549fa55b-7583-483c-ad69-50827ac1b649',
embedding=None,
doc_hash='9587845782747a568bcb37fc4f4a9779a85cc1c376f5964781b8418780927ba3',
extra_info={'page_id': 'cb5db955-351f-48c5-8751-edc8dd7aef76'}),
Document(text='収集する情報\n'
'当サイトでは、お客様の氏名、住所、電話番号、メールアドレスなどの個人情報を収集する場合があります。また、アクセスログやクッキー情報などの情報も収集することがあります。\n'
'収集する目的\n'
'当サイトでは、お客様から収集した個人情報を、以下の目的で利用することがあります。\n'
'\t商品のご注文やお問い合わせに対する返答\n'
'\t商品の発送や配送状況の連絡\n'
'\t新商品やサービスの案内、キャンペーンのお知らせ\n'
'\tアンケート調査やマーケティング分析\n'
'個人情報の管理\n'
'当サイトでは、お客様から収集した個人情報を適切に管理し、第三者に提供することはありません。また、個人情報を安全に保管するための措置を講じています。\n'
'個人情報の開示・訂正・削除\n'
'お客様は、自己の個人情報について、開示・訂正・削除の請求をすることができます。詳細については、当サイトのお問い合わせページをご確認ください。\n'
'クッキーについて\n'
'当サイトでは、お客様が当サイトを利用する際に、一時的にクッキーを利用する場合があります。クッキーによって、お客様のアクセス状況や利用履歴を取得し、より良いサービスを提供するために利用することがあります。',
doc_id='9e99bda7-753b-462d-bcb2-4c9846b76f8e',
embedding=None,
doc_hash='387e77a88de66c8e58db0ce4cad14d96cb6f2182ea2df34fa12d745c6ea94c14',
extra_info={'page_id': '958453a2-e5f9-42e6-96bd-eba6acee8624'}),
Document(text='キャンセル期限\n'
'注文受付後、商品の発送前に限り、キャンセルが可能です。商品が発送済みの場合や配送中の場合は、キャンセルができません。\n'
'キャンセル手数料\n'
'一部の商品については、キャンセル手数料が発生する場合があります。手数料の詳細は、商品ページやサイトのキャンセルポリシーでご確認ください。\n'
'キャンセル方法\n'
'キャンセルを希望する場合は、サイトの注文履歴ページからキャンセル手続きを行ってください。また、カスタマーサポートに連絡することもできます。\n'
'返金方法\n'
'キャンセルによる返金については、商品代金と送料が返金される場合があります。返金方法については、サイトの返品・返金ポリシーでご確認ください。\n'
'キャンセル不可の商品\n'
'一部の商品については、キャンセルができない場合があります。例えば、受注生産品や一度開封された商品、ダウンロード商品などです。キャンセル不可商品については、商品ページやサイトのキャンセルポリシーでご確認ください。',
doc_id='7713191b-2283-47e8-9e23-f734e1c188ea',
embedding=None,
doc_hash='acf4e6de397fe177e69345acf7ca37c25f75253eadf6b8eb6f55de7809771207',
extra_info={'page_id': 'ed48e33e-31ab-4a82-b821-b8fe1908f8b8'}),
Document(text='注文をキャンセルすることはできますか?\n'
'はい、注文をキャンセルすることができます。ただし、商品がすでに発送されてしまった場合はキャンセルできない場合があります。また、注文状況によっては、キャンセル手数料がかかる場合があります。\n'
'商品の返品・交換は可能ですか?\n'
'はい、商品の返品・交換は可能です。ただし、商品によっては返品・交換ができない場合があります。返品・交換に関する詳細は、サイトの返品・交換ポリシーをご確認ください。\n'
'支払い方法はどのようなものがありますか?\n'
'クレジットカード、銀行振込、代金引換、コンビニエンスストア決済など、さまざまな支払い方法があります。商品ごとに使用可能な支払い方法が異なる場合がありますので、サイトで確認してください。\n'
'配送はどのように行われますか?\n'
'配送は、宅配便、郵便、ヤマト運輸、佐川急便などの配送業者によって行われます。配送業者によって、配送日時や配送料金などが異なる場合があります。\n'
'商品はどのように梱包されますか?\n'
'商品は、配送業者の規定に従って、簡易包装や段ボール箱に梱包されます。商品の種類によっては、専用の梱包材を使用する場合があります。\n'
'商品の在庫状況はどのように確認できますか?\n'
'商品の在庫状況は、サイト上で確認することができます。在庫がない場合は、購入することができません。\n'
'サイトで表示されている価格は税込みですか?\n'
'価格は、サイトによって異なりますが、一般的には税込みの価格が表示されています。ただし、消費税などが含まれていない場合もありますので、ご確認ください。\n'
'商品の詳細情報はどこで確認できますか?\n'
'商品の詳細情報は、商品ページで確認することができます。商品名、価格、仕様、画像、カラー、素材などの情報が記載されています。また、商品のレビューやQ&Aも参考にすることができます。\n'
'注文した商品が届かない場合はどうすればよいですか?\n'
'注文した商品が届かない場合は、まずは配送業者の追跡サービスで配送状況を確認してください。また、サイトのカスタマーサポートに連絡し、詳細を確認することもできます。商品が紛失した場合は、再発送や返金などの対応が行われる場合があります。\n'
'クーポンやポイントなどの特典はどのように利用できますか?\n'
'クーポンやポイントは、サイトの指定された方法に従って利用することができます。クーポンは注文時にクーポンコードを入力することで、ポイントは購入時にポイントを使用することで、割引が適用されます。特典の利用方法については、サイトの特典ポリシーを確認してください。',
doc_id='88d29787-fefa-49b2-b06f-f7bbe32c8327',
embedding=None,
doc_hash='f1b87ce7b633f12f661d587c85e5767b4cad241dfb3c912feefe46571d52021d',
extra_info={'page_id': '9c76e186-4f23-44c8-956f-28f9cd71dcc7'})]きちんと取得できていましたね。
続いて、indexを作成します。
# indexの作成
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)作成したindexを保存したい場合は、下記を実行しましょう。
# こちらを追記してください
from llama_index import load_index_from_storage, StorageContext
# indexの保存 ./storageがデフォルトになっています
index.storage_context.persist()
# indexの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)LlamaIndexではindexを作成する際にOpen AIのEmbeddings APIをコールしています。
今回のサンプルデータでは、3517 tokensを使用しました。
APIの使用料としては1円未満です。(Embeddingsの料金:$0.0004 / 1K tokens)
この程度であれば問題ないと思いますが、データの中身が変わらない場合は一度作成したindexを再利用するのがオススメです。
それでは、準備が整いましたので質問をしてみましょう!
query_engine = index.as_query_engine()
answer = query_engine.query("キャンセルはできますか?")
print(answer)
はい、注文をキャンセルすることができます。ただし、商品がすでに発送されてしまった場合はキャンセルできない場合があります。また、注文状況によっては、キャンセル手数料がかかる場合があります。
Notionのデータベース内の情報をもとに回答してくれました!
では、全く関係ない質問をした場合はどうなるのでしょうか?
answer = query_engine.query("会員登録の方法について教えてください")
print(answer)
The context information does not provide any information about how to register as a member.
(文脈情報には、メンバーとして登録する方法に関する情報が含まれていません。)このように、情報が与えられていない旨の返答がきます。
おまけ
LlamaIndexのQAプロンプトは英語になっているため、日本語で質問をした場合でも英語で返答されることがしばしばあります。
特に、文脈にない質問をすると上記のように英語で返されます。
出力を安定させるためには、QAプロンプトのカスタマイズが必須です。
詳しくは公式ドキュメントをご覧ください。
以下の手順でQAプロンプトを変更可能です!
# モジュールの追加
from llama_index import QuestionAnswerPrompt
# このプロンプトを適宜変更してください
QA_PROMPT_TMPL = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question in Japanese: {query_str}\n"
)
QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL)今回は、"please answer the question"の後に、"in Japanese" を追記しました。
この部分を全て日本語に書き換えたり、「ヘルプデスク担当として回答してください」など設定することで、ある程度の出力のカスタマイズは可能です。
query_engine = index.as_query_engine(text_qa_template=QA_PROMPT)
response = query_engine.query("会員登録の方法について教えてください", text_qa_template=QA_PROMPT)
print(response)
申し訳ありませんが、この情報からは会員登録の方法についての情報が提供されていません。最後まで読んでくださりありがとうございました!
この情報は執筆時時点のものになりますので、エラーなどが出た場合は公式ドキュメントをご確認ください🙇
この記事が気に入ったらサポートをしてみませんか?