
[LLM PoC]Whisper + GPT-4で服薬指導の音声から薬歴内容を自動生成させることに成功しました

こんにちは!
PharmaXエンジニアリング責任者の上野(@ueeeeniki)です!
PharmaXでは、ヘルスケア領域でのLLMの活用を目的にPoCに取り組んでいます!!
前回、疑義照会が半自動化できたというPoCの結果を記事として発信しました。
『ChatGPT Meetup Tokyo #0』でも発表させていただきました!
今回は、服薬指導の音声から、薬歴(薬局版のカルテと思っていただければ大丈夫です)の内容を自動生成することに成功したという内容を紹介したいと思います!!!
疑義照会の半自動化もかなり大きな反響をいただきましたが、今回も医療業界に取ってはかなり革新的なPoC結果になったのではないかと思います!
ただし、以下の点にはご注意ください!
私たちがLLMのPoCとして発表する内容はあくまで「技術的に可能であること」を示すものであり、参考にされた方や企業の個人情報保護の問題などについては一切の責任を負いません。 自社のデータは、各企業や個人がきちんと責任を持って取り扱っていただければと思います。
弊社では、LLMのPoC段階では、サンプルデータを作成してPoCを行っています。
(今回は、自社内で薬剤師と他のメンバーで録音した服薬指導の音声でPoCを行っています。)
また、あくまで「内容の自動生成」であり、最終的には薬剤師のチェックを経ることが望ましいでしょう。
PharmaXでも、OpenAIやMicrosoftのAzure Open AIの規約にもあるように、AIが自動で医療的な内容に回答したり、コンテンツを生成することは意図していません。
専門家が責任を持って内容を精査するようなユースケースのみを想定しています。
服薬指導&薬歴とはなにか?
医療・薬局業界に詳しい方ばかりではないと思うので、そもそも服薬指導、薬歴とは何か?という話から始めます。
服薬指導とは、患者に対して処方薬の薬効や服用の仕方、副作用などの注意点を説明すること
薬歴とは、患者に対して服薬指導した内容や他の薬剤師への申し送りなどを記載した文章
です。
医師で言えば、服薬指導は診察、薬歴はカルテにあたります。
薬局に処方せんを持って行くと、薬剤師から「この薬は食後に飲んでください」「この目薬Aとこの目薬Bは5分ほど間隔をあけて使用してください」などと説明された事があるかと思いますが、あれが服薬指導です。
服薬指導を受けなければ、薬局に行っても処方薬を購入することはできません。

また、薬歴は 、一般消費者に取っては、馴染みがないかと思いますが、患者さんの情報を整理し、評価するために、いわゆる「SOAP形式」で記入される服薬指導の記録です。
「SOAP形式」とは、Subjective(主観的所見)、Objective(客観的所見)、Assessment(評価)、Plan(計画)の頭文字をとったもので、以下のような意味があります。
Subjective (S)(主観的所見): 患者さん自身が感じている症状や問題を記録する部分です。例えば、痛みの程度や、気分の変化、食欲不振など、患者さんが伝える情報がここに記載されます。
Objective (O)(客観的所見): 検査結果や観察による客観的なデータを記録する部分です。血圧、体重、検査値(血液検査、尿検査など)、画像検査(レントゲン、CT、MRIなど)の結果がここに記載されます。
Assessment (A)(評価): SubjectiveとObjectiveの情報をもとに、患者さんの病状や薬物治療の効果・副作用を評価する部分です。問題点や改善が必要な点、治療の効果などを記載します。
Plan (P)(計画): 評価をもとに、今後の治療方針や薬物療法の変更、患者さんへの指導内容など、具体的なアクションプランを立てる部分です。
薬剤師は医師がカルテを書くのとは違って、PCで薬歴を記入しながら患者対応するのが難しいので、薬歴を書くことは薬剤師にとって大きな負担になります。
忙しい薬局では、薬剤師は常に動き回っているので、患者数が落ち着いたタイミングでそれまでの患者分の薬歴をまとめて記入するといった望ましくない状況が常態化している薬局も多いと聞きます。
その結果、薬歴の記入は薬剤師の残業時間の増加の原因になります。
そこで、服薬指導した音声から薬歴が自動で生成できれば、薬剤師の負担を大幅に削減することが可能です。
Whisper + GPT-4 APIを使った服薬指導の音声から薬歴内容を自動生成PoC
服薬指導音声から薬歴内容を自動生成する手順
服薬指導音声から薬歴内容を自動生成するための手順は以下の通りです。
① その患者の処方せんから医薬品の処方情報を抜き出して構造化する
② 服薬指導の音声の録音からWhisperで文字起こしする
必要があれば、患者と薬剤師で話者分離する必要もある
③ ①の処方情報と、②の服薬指導内容の文字起こしからGPTで薬歴の内容を自動生成する
手動作成した服薬指導会話から薬歴内容を自動生成する
順を追って説明していく前に服薬指導の内容を音声からの文字起こしするのではなく、手動で服薬指導内容を作成し、薬歴内容を自動生成可能かを確認します。
下記のような理想的な服薬指導時の会話内容を手動で作成した上で、薬歴内容を自動生成できなければ、実際の人間の会話でうまく薬歴内容を自動生成することは難しいでしょう。
薬剤師:上野さん、お待たせしました。今日はどうなされましたか?
患者:はい、子どもを抱っこしようとしたら腰がピキッといってしまって。。。それから腰の痛みが引かなかったので、クリニックに行って薬をもらうことにしました。
薬剤師:それはお辛いですね。今回は痛みを和らげるための薬が2種類出ています。
1つ目がモーラステープというお薬です。
・・・(中略)・・・
患者:飲み薬は1回飲んだらどれくらい間隔を空ける必要がありますか?
薬剤師:1回飲んだら、6時間ぐらい空けるようにお願いします。
他になにか気になることはありますか?
患者:分かりました。ありがとうございます。他に気になることはないです。
薬剤師:お大事にどうぞ。
ここでは、APIではなく、ChatGPT-4を使って、検証してみます。
下記のようにChatGPT-4に与えてみました。

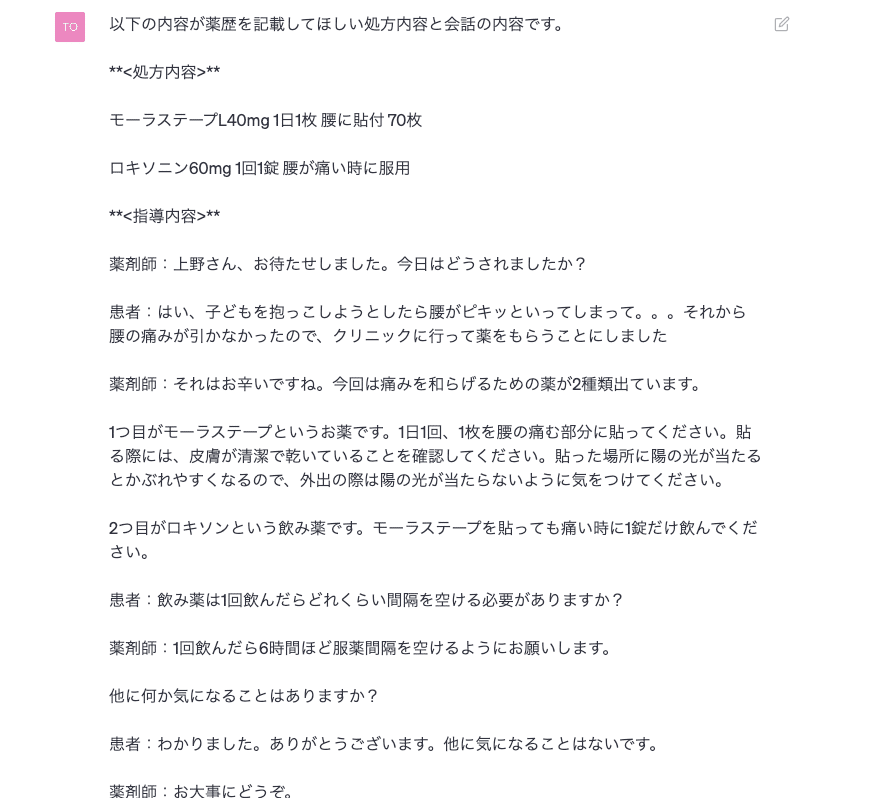
その結果、完成した薬歴が下記のような内容です。

弊社の薬剤師によれば、かなり丁寧に薬歴が記載できているとのことです。
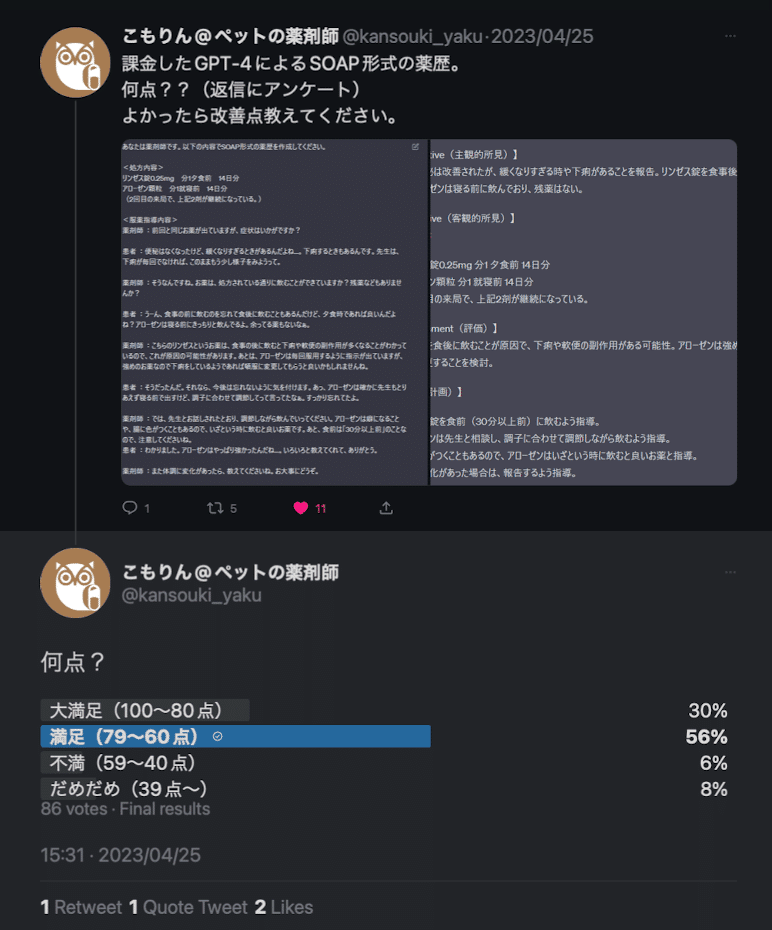
このような例であれば、他社の薬剤師の方が試しているのをSNS上でいくつか見かけましたが、例えば、下記のように薬剤師のみなさんの反応を見ている限りかなり満足の行く内容が生成できているようです。
(こもりんさんにアンケート結果まで載せていいとおっしゃっていただいたのでご参考にしていただければ!)
会話内容を手動で作成した場合であれば、GPT-4はいい感じで薬歴内容を生成してくれることが分かったので、服薬指導音声から薬歴内容の自動生成も十分可能なのではないか?という手応えを得ることができました。
特に、手順②で、服薬指導の音声をきれいに文字起こしできるかということと、薬剤師と患者のいわゆる「話者分離」が可能かどうかが技術的論点だということになるでしょう。
では、早速順を追って見ていきましょう。
① その患者の処方せんから医薬品の処方情報を抜き出して構造化する
この①は、下記の記事で詳細を記載しているので、軽く説明するにとどめます。

処方せんの赤枠の欄に記載されている処方内容をOCRなどで取得をし、GPT-4を使って下記のように構造化させます。
[{
"薬名": "セルトラリン錠25mg",
"1日摂取量": "1錠",
"摂取タイミング":"1日1回夕食後に",
"処方量": "7 日分",
"注意点": ""
},
{
"薬名": "ボルタレンサポ50mg",
"1日摂取量": "1個〜2個",
"摂取タイミング":"",
"処方量": "10 個",
"注意点": ""
}]
上記の記事でも記載したように試したすべての処方せんで構造化することに成功しました。
これらは処方内容として後で服薬指導の内容と一緒にGPT-4に与える必要があります。
② 服薬指導の音声の録音からWhisperで文字起こしする
+
③ ①の処方情報と、②の服薬指導内容の文字起こしからGPTで薬歴の内容を自動生成する
②でどの程度の精度で文字起こしができていればいいのかは、③でどの程度いい感じに薬歴内容が生成できていればいいのか?とセットなので、②と③はセットで扱います。
WhisperはOSS化されているので、ローカルでも実行することができますが、OpenAIからもAPIが公開されています。
OpenAIのAPIを使うほうが多少お金はかかりますが、APIであれば精度の高いlarge-v2をかなりの処理速度で利用可能なので、ここではAPIを使いました。
Whisper単体では、話者分離ができないので、録音したファイルを与えると、以下のように話者の区別なくひたすら文字起こしされます。
今日は薬が2種類出ております 咳の症状で受診されたんですかね そうですね はい分かりましたありがとうございます じゃあまず一つ目のアストミンという薬をご説明させていただきます これは咳を止める薬です で、埋食後に1回2錠飲んでください もし咳が治まってくるようであれば無理に5日分飲まなくても大丈夫ですので 咳に調節して飲んでください もう1個目が
・・・(中略)・・・
他に何か気になられているところはございますか いや大丈夫です はい承知しましたじゃあのお大事になさってください はいありがとうございます。
多少おかしなところもありますが、かなりきれいに文字起こしできているのが分かります。
おそらく、服薬指導は、患者1人対して薬剤師1人が対応する1対1の対話であり、会議などと比較しても発言の被りなどが少なため、精度高く文字起こしできるのではないでしょうか。
手動で服薬指導会話内容を作成した場合のように、話者分離した方が、より正確な薬歴内容を生成することが可能だとは思いますが、ここでは一旦、このままGPT-4に服薬指導の内容として与えてみて、薬歴が自動生成できるのか?を確認します。
何ごともステップバイステップで進むことが大事です。
結果、驚くべきことに、話者分離をせず、文字起こしした内容をそのままGPT-4に与えても、かなり丁寧な服薬指導内容を生成することができました。
S:
患者は咳と喉の痛みの症状で受診。
O:
1. アストミン錠10mg (1日6錠、分3 毎食後、5日分)
2. SPトローチ0.25mg 「明治」 (外用、医師の指示通り、15錠)
A:
咳と喉の痛みの症状に対して、咳止め薬と喉の痛みを取る薬が処方されている。
P:
1. アストミン錠10mgは、毎食後に1回2錠服用するよう指導。咳が治まってくるようであれば、無理に5日分飲まなくても大丈夫と説明した。
2. SPトローチ0.25mgは、1日6回を目安に1回1錠を口の中に含んで、噛み砕かずに少しずつ溶かすように使うよう指導。症状が良くなったら無理に飲まなくても大丈夫と説明した。
服薬指導音声の話者分離
今回試した複数の音声では、話者分離をせずともかなり精度高く、服薬指導内容を生成することができました。
しかし、もっと内容が複雑になった場合など、話者分離をした方が精度が高くなるという場面はあるでしょう。
Whisperで話者分離をする際によく用いられるのが、 Pyannoteです。
しかし、Pyannoteでは、会話内容が消失してしまうなどの問題があり、精度があまり高くありません。
Pyannoteについては、別の方の記事ですが、以下の記事などをご覧ください。
今回のPoCでは、GPT-4に話者分離をさせるという方法を取ることで、かなり精度高く分離することができました。
イメージとしては、GPT-4に「この文章は薬剤師と患者が会話をしています。それぞれの文章を薬剤師と患者どちらが話したのか分類してください」と司令するようなイメージです。
おそらく、患者1人対して薬剤師1人が対応する1対1の対話であり、お互いのロールが明確なので、きれいに分離することが出来るのだと思います。
このあたりは、また別途詳しく取り上げたいと思います!
今後の挑戦ポイント
音質が悪い場合の性能向上
服薬指導音声からの薬歴内容の自動生成には、他にもいくつか困難なポイントが考えられます。
今回は、複数の音声でPoCを行い、会話パターンなどは複数試したことは上述しました。
一方で、実際の服薬指導ではもっと音声が割れていたり、激しい雑音が入っていたりするために、文字起こし性能がかなり低くなるという事態は想定されます。
実際、私たちの薬剤師がオンライン服薬指導をしている際にも、患者様の音声が良く聞こえないということはたまにあります。
当然、あまりにも酷すぎる場合には、時間をおいて再度通話し直すといったことはしているものの、人間であれば多少音質が悪くとも相手の会話内容を推測可能なため、そのまま服薬指導を完了してしまうということはあるでしょう。
このような場合の文字起こし→薬歴内容の自動生成の性能をいかに高めるか?がチャレンジポイントとなります。
今回音楽などの雑音を入れてWhiperで文字起こしをしても、かなり精度良く背景雑音からの切り分けができていました。
今後も研究が急ピッチで進んでいくでしょうから、私たちが頑張らずとも近いうちに文字起こし性能は爆発的に向上することが見込まれるものの、正確な薬歴記載のためにはさらなる工夫が必要だと考えられます。
話者が3人以上いる場合の性能向上
また、話者が3人以上いる場合には、薬歴内容の自動生成が困難になることも想定されます。
基本的には服薬指導は、患者1人対して薬剤師1人が対応する1対1の対話であるから非常に精度が高くなるのだろうという考察は上述しました。
しかし、あまり多くはないケースですが、患者さん側が複数人いらっしゃる場合があります。
例えば、高齢者の方の付添いで、その方のご家族(お子様やお孫様など)が一緒に会話に参加するケースなどがあり得ます。
また、小児科で、お子様の薬を受け取る際に、基本的には親御さんが対応されますが、お子様に話を振るようなケースも想定されます。
このような場合には、話者分離の難易度が多少高まることが予想されるので、薬歴内容の自動生成も多少難しくなるでしょう。
まとめ
今回は服薬指導の音声から、薬歴内容を自動生成するPoCについて紹介してきました。
まとめると、
雑音が入っていても服薬指導の音声はきれいに文字起こしすることができた
話者分離せずに服薬指導音声を文字起こしした文章から、かなり丁寧で間違いのない薬歴内容を自動生成することができた
(今回は詳細を取り上げなかったが、)話者分離もGPT-4にさせる方法で精度高く分離することができた
というような結果を得ることができました。
まだまだ改善ポイントはあるものの、Whisper + GPT-4で薬剤師の負担を大幅に減らせる可能性を示すことができました!
冒頭でも申し上げた通り、ご参考にいただく際には、個人情報の扱いやセキュリティの問題などには十分お気をつけてください。
今後半年程度で様々な分野で事例の研究がされ、LLMでできること、できないことはある程度明らかになってくるのではないかと考えています。
一方で、重要なのは、実際にオペレーションに組み込んで、オペレーションが劇的に楽になるUXを作りだすことが出来るかどうかです。
どちらかといえば、深い業務理解とアプリケーション開発の知見が必要になります。
例えば、今回のような薬歴内容を自動生成するアプリケーションを作る上でも、処方せん情報、服薬指導の音声ファイル、過去の薬歴の情報などを薬剤師がすべて手動で入力しなければならないような独立した管理画面を作ったとしても非常に不便です。
忙しい中では、結局使われないかもしれません。
というのも実際に大規模言語モデルを使おうとすると、どちらかというと高度な機械学習などの前に、LLMやChatGPTの特性を活かしたユーザー体験と、それが実際に業務で役に立つのかの証明が先に必要となります。なのでまずはとにかく高速にプロトタイピングを重ね、お客様の声を聞き、正しいものを作ると…
— 松本 勇気 | LayerXはSaaS+Fintechの会社です (@y_matsuwitter) May 2, 2023
上記の松本さんのTweetにもあるように、結局はこれまでのアプリケーション開発と同様に、まずはユーザーにとっての価値があるのかの検証と、ローンチ後もPDCAを回して体験を向上させ続ける必要があるでしょう。
最後に
もっと詳しい話を聞きたいなど、ご興味がある方は、YOUTRUSTまたはTwitter DMからご連絡をお待ちしています!
5/10(水)にLLM周りの取り組みを紹介するイベントもやるので、ぜひご参加いただければ嬉しいです!
また、生成AI/LLMの専任チームも立ち上げておりますので、ご興味ある方はご連絡ください!

この記事が気に入ったらサポートをしてみませんか?