
パナリットのデータクレンジング

データマネジメントやデータ分析において、とても重要なのはデータの質を高めることです。この解説書はパナリット導入時に行われる、システム連携後の「データクレンジング」について、実例と共に解説します。

ライター紹介
Hervé Froc エルベ・フロック Data Engineer | パナリット・ジャパン
フランスESIEA大学に卒業し、AXA Direct Japan に入社。同社でBI・機械学習・データ処理・データマネジメント・DataOpsなどに従事。
0. データクレンジングとは?
データクレンジングとは不正確・不完全・欠損したデータを特定し、それらを変更・置換・削除しデータの質を高めるためのプロセスの総称です。下の図のように繰り返し行うことで、常にデータを正常な状態に保つことが重要です。データサイエンティストはよく“Garbage in, garbage out”(ゴミデータを分析してもゴミ分析しか生まれない)と言いますが、質の高い分析結果を得るためにも、データの質を高めることは非常に重要です。
以下、パナリットで行うデータクレンジングの7つのステップを説明します。

1. データセットの統合
人事データは多くの場合さまざまなシステムやファイルに分断され、ときにフォーマットさえ異なることもあります。分析業務を行う前に、データセットを統合する必要があります。
以下は2つのデータテーブル(従業員テーブル、組織テーブル)ですが、従業員テーブルには部署コードが書かれていますが部署の詳細やチームについては情報がありません。
従業員テーブル:

組織テーブル:

分析に必要な際はこのテーブルのデータを連携し、一元化する必要があります。
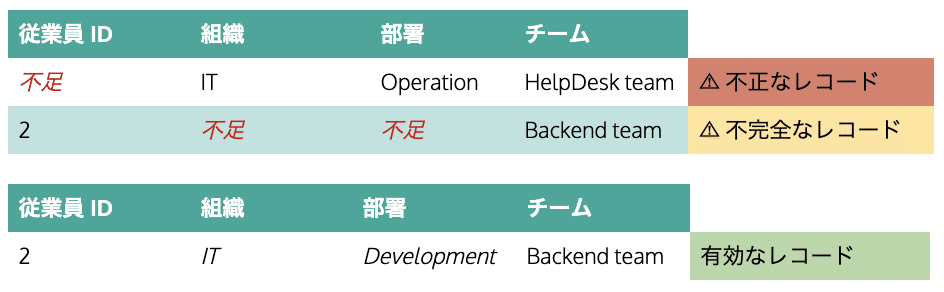
2. 不足データの扱い
不足データの取り扱いは、多くの場合以下の2パターンに分類できます:
必須項目が不足している場合: 従業員IDのような必須項目は非常に大切であり、欠落しているとデータセットの有用性が無効となる場合もあります。この場合、データレコードを削除するか、可能であるなら修正する必要があります。
その他の項目でデータが不足している場合: これらの項目にデータが欠落している場合、分析に影響し場合によっては間違ったインサイトを与える可能性があるため、可能な限り値を入力する必要があります。
例:
3. データの標準化
標準化の目的は、整理されていないデータを整え、統一された見方を提供することです。複数のソースからのデータを統合する場合、使用される用語はしばしば意味や定義が異なるため、社内での混乱を招くこともあります。
部署やチーム名などの項目は、多くの場合複数の値が散見されます。これは、特にデータが手動で入力され、人々が独自の定義でチーム名を入力する場合に多く発生します。統一された名称でデータを標準化することが必要です。
チーム名称における例:

4. データの正規化・構造化
統計では、正規化とは通常、異なるスケールで測定された値を共通のスケールに調整することを指します。データの正規化も同様の概念に従います。目的は、分析用に最適化された独自の構造を持つためにデータを変更および再編成することです。 (データの正規化はデータベースの正規化とは異なることに注意してください)
人事データの正規化とは具体的にどういうことを指すか?パナリットでは通常、クライアントのデータ階層を調整(または重複の消去を)し、グラフの可視化やクエリースピードを最適化するためデータを再構築します。またパナリットのデータウェアハウスは人事データ分析専用に作られており、計算のクエリースピードを最適化する構造にデータを格納します。このように、クライアントデータを取り込む際パナリットは最適なデータ構造にするためデータの再編成を裏で行なっているのです。
従業員雇用形態を階層分けした例:

階層に重複が散見されるものを再編成した例:
▼クレンジング前

▼クレンジング後(フィルターが円滑に作動するよう重複を排除したもの)

また、ときにクライアントのデータ構造は一時的な分析をするのには適したフォーマットだとしても、中長期的な分析には向かないこともあります。
例えば下記のようなデータ構造を持つ組織は、各従業員の特定の評価期のスコアが知りたい場合は問題ありませんが、長期スパンですべての評価期のスコアを可視化する場合は使用が困難です。データモデリングの観点では、スコアはメジャーを表しますが、日付はディメンションであり、単一のフィールドに統合されると柔軟性が失われてしまいます。その場合、パナリットは一時的な分析にも、長期間での総合的な分析にも、双方耐えられるような推奨データフォーマットへの変換をサポートします。
▼クレンジング前

▼クレンジング後(日付ディメンションを分離したもの)

5. 重複データの取り扱い
複数のデータセットを統合するときに、データレコードが重複することはよくあります(とくに、システムをまたいだデータセットAとデータセットBの関係性が多対多の場合)。パナリットではデータをデータウェアハウスにアップロードする前に、常に重複レコードをチェックして削除します。
6. データエンリッチメント(データの価値向上)
データエンリッチメントとは、既存のデータセットに価値ある情報を追加するプロセスです。パナリットでは必要に応じてケースバイケースでこれを行い、顧客に元のデータセットのみでは得られない価値を提供します。
以下は、あるクライアントに対して提供した例です。クライアントのシステムには従業員が働いている勤務地の“店舗名称”はありましたが、県・都市・地区などの情報が不在でした。これでは従業員の配属が都心や地方にどう分散しているか分からないですし、エリアによって賃金格差がどれくらいあるかなどの分析も非常に困難です。そこで、オープンAPIも駆使しながら店舗名称を手がかりに、各店舗の住所を取得し、県・都市・地区別に振り分けるボットを構築し、これらの情報を元のデータに統合しました。
例:

7. データ検証
データ検証は、クレンジングされたデータの一貫性と信頼性を確保するための重要なプロセスです。データが一連の検証ルールまたは検証制約に合致するかを測るテストを行います。
ルールの一例:
従業員の年齢は、法定労働年齢と同じかそれ以上である
従業員IDはユニーク(一意)である
さいごに
データのクレンジングはいかなる分析にとっても重要ですが、実際どれほどの時間や労力がかかるか多くの人は見落としがちです。 CrowdFlowerの調査によると、大多数のデータサイエンティストはデータのクレンジングと整理に業務時間の60%を費やしているそうです。
自社のリソースでデータクレンジングをする代わりに、Panalytのパワーエンジンを検討されるようでしたら、担当営業もしくは hello@panalyt.com までご連絡ください。
皆さまのデータプロジェクトに実りがありますよう!

この記事が気に入ったらサポートをしてみませんか?