
Talking Head Anime 3 SW より、対応画像の高解像度化について

※この記事は開発者向けです。
Talking Head Anime 3 SWのver20240812で、1024pxのイラスト出力に対応したバージョンのアップデートを行いました。
以前に比べて、ボケやジャギーの少ない出力が可能になる場合があります。
このなかで用いた手法の簡単な紹介となります。
Talking Head Anime の入出力イラストの制限について
Talking Head Anime 3では、もともとの入力画像の解像度は512ピクセル×512ピクセルとなっています。また出力解像度に関しても同様となっています。

高解像度化について
今回の更新より前から採用していた手法は、簡単にいえば次のような手順となります。
1024ピクセル四方の画像を1ピクセル飛ばしで512ピクセル四方の画像に変換する
それを起点をずらして4枚の512ピクセル四方の画像を得る
各々の画像を変換
元の並びに再合成
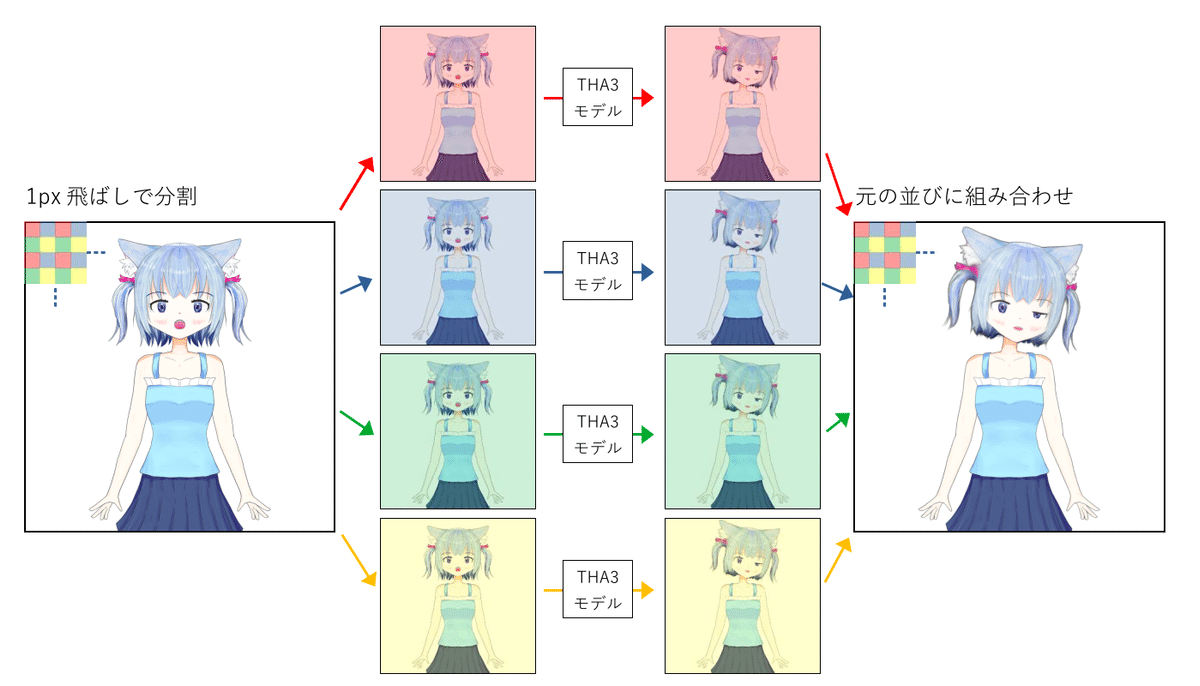
この手法の難点は、入力画像の差異により、出力に位置のわずかなずれが生じ、画像が荒れてしまうことです。特に、動きを大きくした場合に格子状あるいは線状の荒れが顕著になります。
新たに取り入れた手法
Talking Head Anime 3のモデルでは、最終の出力だけでなくいくつかの途中経過にあたるような出力を得ることができます。その中の一つに、元画像からの動きの移動量を表すマップ出力があり、これを用います。

これを用いて、次のような手法を採ります。
上記の要領で正面向きで表情のみ変えた差分を得る
移動量のマップを得る
2のマップを拡大する
3の拡大したマップに沿って1の差分の画像を変形させる
顔を振ったりした際の移動に伴うずれが生じにくくなるため、荒れが少なくなります。ただし、手順が増えるためフレームレートは出しにくくなります。

ソースコード
この手法に用いるソースコードです。(機能を絞ってまとめて抜き出したため、アプリケーション版に使っているものとは一部異なります。また、わかりやすさのため並列化をしていないため更に遅めになっています。)
このコードをもともとのtalking-head-anime-3-demoのposer.poseの代わりに呼び出すことで1024px四方の画像の入出力を行うことができます。
import torch
from torch.nn import functional as F
from tha3.poser.modes.load_poser import load_poser
# from tha3.poser.poser import Poser
device = torch.device('cuda')
model_name = "separable_half"
poser = load_poser(model_name, device)
poser.get_modules()
mapbase = torch.zeros((2,512,512), dtype = poser.get_dtype(), device = device)
for y in range(512):
for x in range(512):
mapbase[1, x, y] = x
mapbase[0, x, y] = y
def tha_inference_1k(image, pose):
image_size = 1024
with torch.inference_mode():
image_divided = [None] * 4
image_resized = None
face_output = [None] * 4
image_output = [None] * 4
torch_map = None
image_divided[0] = image[:, ::2, ::2]
image_divided[1] = image[:, 1::2, ::2]
image_divided[2] = image[:, ::2, 1::2]
image_divided[3] = image[:, 1::2, 1::2]
image_resized = (image_divided[0] + image_divided[1] + image_divided[2] + image_divided[3]) / 4.0
for l in range(4):
face_output[l] = poser.pose(image_divided[l], pose, 8)[0]
image_output[l] = image_divided[l].detach().clone()
image_output[l][:, 32:224, 160:352] = face_output[l]
torch_image = torch.zeros((4, 1024, 1024), dtype = poser.get_dtype(), device = device)
torch_image[:, ::2, ::2] = image_output[0]
torch_image[:, 1::2, ::2] = image_output[1]
torch_image[:, ::2, 1::2] = image_output[2]
torch_image[:, 1::2, 1::2] = image_output[3]
torch_map = poser.pose(image_resized, pose, 4)[0]
map_scale = image_size / 512.0
torch_image_map = torch_map * 256.0
torch_image_map = mapbase + torch_image_map
torch_image_map_large = F.interpolate(torch.reshape(torch_image_map, (1, 2, 512, 512)), (image_size, image_size), mode='bicubic', align_corners=False)
torch_image_map_large = (torch_image_map_large * map_scale).int().clamp(0, image_size - 1)
torch_image_map_large_b = torch_image_map_large[0, 0] + torch_image_map_large[0, 1] * image_size
torch_image_map_large_serial = torch.reshape(torch_image_map_large_b, (1, image_size * image_size)).tolist()
torch_source_image_serial = torch.reshape(torch_image, (4, image_size * image_size))
torch_image_serial_l = [torch_source_image_serial[:, x] for x in torch_image_map_large_serial]
torch_image_serial = torch_image_serial_l[0]
torch_image = torch.reshape(torch_image_serial, (1, 4, image_size, image_size))[0]
return torch_imageなお、このコードについてはMITライセンスとしますので、発展させていただければと思います。
MIT License
Copyright (c) 2024 pale_color
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
この記事が気に入ったらサポートをしてみませんか?