
麻雀の強化学習環境Mjx(v0.1.0)を触る(1/3)ライブラリ機能の確認編

神域Streamerリーグ最高でした。アトラス優勝おめでとうございます!
Pythonで使える麻雀の強化学習環境であるMjxというものが公開されていると知り、触ってみました。
Env(環境)
強化学習の構成要素は大きく2つで、Env(環境)とAgent(エージェント)です。
Envはゲームの状態を管理します。
EnvはAgentからアクションを受け取り、ルールに基づいて状態を更新していきます。
ゲームが終わるタイミングで、EnvはAgentにReward(報酬)を与え、Agentはそれを手がかりにしてアクションの選び方を学習していきます。
Mjxでは、ゲームの状態を管理するMjxEnvと、サンプルとしていくつかのAgentが実装されています。
まずはMjxEnvを見てみます。インスタンス化してreset()を呼ぶと東一局配牌状態になります。
import mjx
env = mjx.MjxEnv()
env.reset()
state = env.state()
state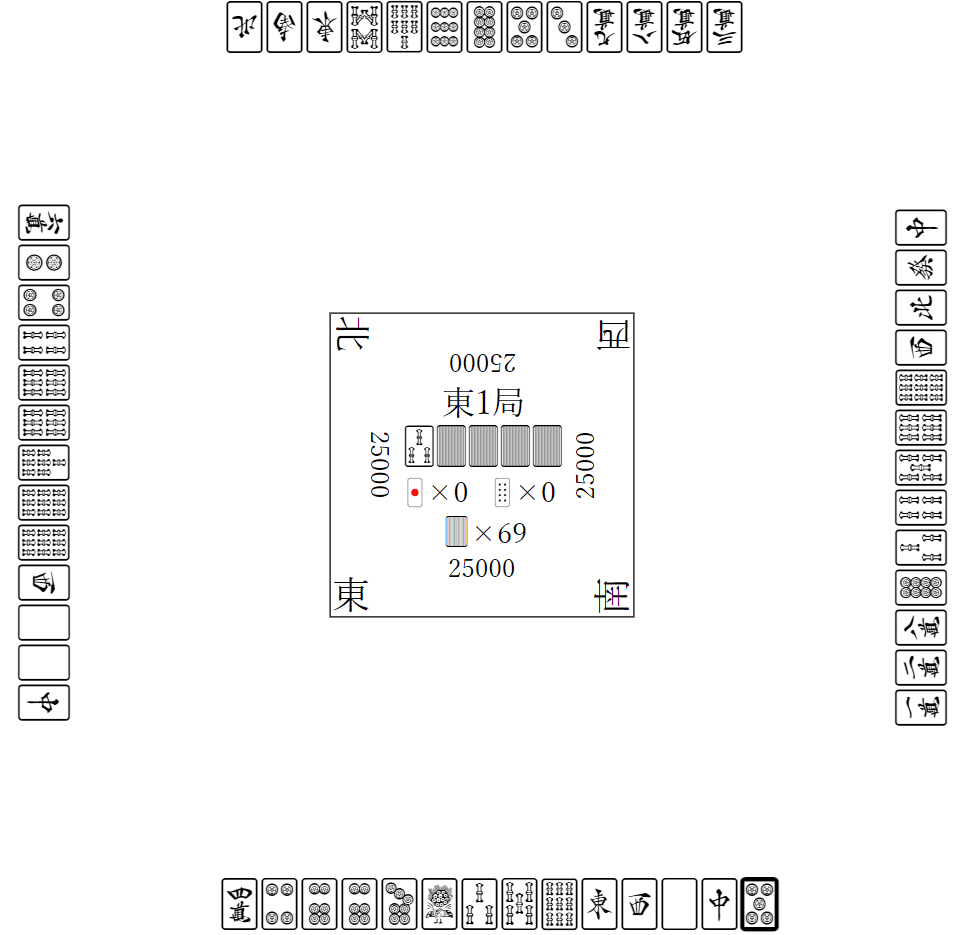
可視化がめっちゃキレイです。
env.reset()の返り値に、Agentが観測できる状態が入っています。
env.done()がTrueを返すまで、Agent4人分のアクションを使ってenv.step(actions)を呼ぶことでゲーム終了まで進行できます。
import mjx
from mjx.agents import RandomAgent
agent = RandomAgent()
env = mjx.MjxEnv()
obs_dict = env.reset()
while not env.done():
actions = {player_id: agent.act(obs) for player_id, obs in obs_dict.items()}
obs_dict = env.step(actions)
env.state()
終了時は西4局11本場になっています。
今回使ったAgentは、RandomAgentというランダムに行動するAgentだったので、流局が続いたようで点数も25000点のままですね。
Agent(エージェント)
MjxにはShantenAgentという、有用なAgentが実装されています。
https://github.com/mjx-project/mjx/blob/master/mjx/agents.py#L64
アガれるアクション(ツモ、ロン)がある場合、アガる
リーチできる場合、リーチする
チー、ポン、カンできる場合、いずれかをランダムに実行する
切るとシャンテン数が減る牌がある場合はそこからランダムに切り、ない場合ランダムな手牌を切る
さっきと同じように1ゲーム進行します(Agentを変えただけです)。
import mjx
from mjx.agents import ShantenAgent
agent = RandomAgent()
env = mjx.MjxEnv()
obs_dict = env.reset()
while not env.done():
actions = {player_id: agent.act(obs) for player_id, obs in obs_dict.items()}
obs_dict = env.step(actions)
env.state()
今度は南4局で終了し、点数も変動しています。
鳴ける場合には鳴くので、かなり副露が多くなりやすそうです。
Reward(報酬)
ゲームが終わると、Envから報酬を引き出すことができます。
これは天鳳7段の段位戦のポイントになっています。
env.rewards()
# {'player_2': 45, 'player_3': 0, 'player_0': 90, 'player_1': -135}これを使ってAgentの学習を行いますが、まずは学習できるパラメタを持ったAgentを実装する必要があります。
Agentのサンプル実装を見てみます。
https://github.com/mjx-project/mjx/blob/master/mjx/agents.py#L50
class ShantenAgent(Agent):
def act(self, observation: Observation) -> Action:
legal_actions = observation.legal_actions()
# ---(中略)---
# discard an effective tile randomly
legal_discards = [
a for a in legal_actions if a.type() in [ActionType.DISCARD, ActionType.TSUMOGIRI]
]
effective_discard_types = observation.curr_hand().effective_discard_types()
effective_discards = [
a for a in legal_discards if a.tile().type() in effective_discard_types
]
if len(effective_discards) > 0:
return random.choice(effective_discards)Envから返されるObservation(観測)には、legal_actions()というメソッドがあり、Agentの選べるアクションが取得できます。
Observationのオブジェクトから、curr_hand()メソッドなどで手配、他家の捨て牌、巡目などの情報を得られそうなことがわかります。
これらを入出力にする、学習可能なパラメタをもつAgentを実装できそうです。
次の記事で簡単なAgentを作って学習するサンプルを書いています。
麻雀の強化学習環境Mjx(v0.1.0)を触る(2/3)教師あり学習編
https://note.com/oshizo/n/n4eae69dbeb23