
GPT-2を使ったテキスト生成をAWS Lambdaで行うコストを実測する

GPTモデルを使ってTwitterのBotのなどを運用したい場合に、月額固定で課金されるインスタンスをレンタルするか、使った分だけ課金されるサービスを選択するか、どちらがお安いかを調べてみます。
今回はAWS LambdaでGPT-2(rinna/japanese-gpt2-medium)のテキスト生成を行い、必要なメモリ、実行時間を計測して一回当たりの生成コストを実測してみます。
結論
計測方法の前に結論を書いておきます。
AWS Lambda で rinna/japanese-gpt2-medium で100トークン生成すると、1回あたり1.08円
t4g.mediumの月間コストが3,567円のため、月に3000回以上生成しないなら、Lambdaのほうが安い
デプロイパッケージの作成方法を選ぶ
AWS Lambdaにコードをデプロイするには、コードと依存ライブラリをzipにまとめてアップロードする方法と、dockerのコンテナイメージをアップロードする方法があります。
zipファイルの方は、展開後のサイズが250MBまでの制限があるようですが、依存ライブラリで250MBを超えてしまうので、dockerのコンテナイメージを使う方法にしました。

コンテナイメージは10GBが上限なので、大丈夫そうですね。
AWSのベースイメージから、コンテナイメージを作る
AWSはLambda用のコンテナイメージを作るためのベースイメージを公開しており、それを利用したDockerfileを書いていきます。
ここの公式ドキュメントに解説とDockerfileのひな形があります。
ハンドラを書くapp.py、Dockerfile、モデルファイルを置いたディレクトリを用意します。

app.pyにhandler関数を定義して、この中でテキスト生成します。
Lambdaでの生成にかかる時間を測りたいので、生成トークン数を100に固定しています。
app.py
import json
from transformers import T5Tokenizer, AutoModelForCausalLM
def handler(event, context):
model_path = "."
tokenizer = T5Tokenizer.from_pretrained(model_path)
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained(model_path)
prompt = "明日の予定は"
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
do_sample=True,
min_length=100,
max_length=100,
pad_token_id=tokenizer.pad_token_id)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {
'statusCode': 200,
'body': json.dumps(generated_text)
}
Dockerfileの先頭で、ベースイメージを利用する宣言をします。
この中で、pipで依存ライブラリをインストールしています。
Dockerfile
FROM public.ecr.aws/lambda/python:3.9
# Copy function code
COPY app.py ${LAMBDA_TASK_ROOT}
COPY models/ ${LAMBDA_TASK_ROOT}
# Install the function's dependencies using file requirements.txt
# from your project folder.
RUN pip3 install transformers torch sentencepiece --extra-index-url https://download.pytorch.org/whl/cpu --target "${LAMBDA_TASK_ROOT}"
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "app.handler" ]ローカルで動作確認
app.pyとDockerfileがあるフォルダでdocker buildし、docker runでコンテナを起動します。9000番でリクエストを待ち受けている状態です。
> docker build -t gpt-lambda .
> docker run -p 9000:8080 gpt-lambda(Windowsの場合)Git bashなど、PowerShell以外のクライアントを使って、curlコマンドで動作確認ができます。
PowerShellを使うと、"Unable to unmarshal input: Expecting value: line 1 column 1 (char 0)" のエラーが帰ってくるので注意してください。
MINGW64 ~
$ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'デプロイして実測
ECRへpush
デプロイの手順はこのページの images-upload に書いてある通りです。
PowerShellだと以下のようなイメージです。
環境変数にアクセスキーとシークレットを設定し、DockerにECRへのアクセス情報を与え、ECRにリポジトリを作って docker push しています。
> $Env:AWS_ACCESS_KEY_ID = 'access key id'
> $Env:AWS_SECRET_ACCESS_KEY ='secret access key'
> aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 012345678901.dkr.ecr.ap-northeast-1.amazonaws.com
> aws ecr create-repository --repository-name gpt-lambda --image-scanning-configuration scanOnPush=true --image-tag-mutability MUTABLE
> docker tag gpt-lambda 012345678901.dkr.ecr.ap-northeast-1.amazonaws.com/gpt-lambda
> docker push 012345678901.dkr.ecr.ap-northeast-1.amazonaws.com/gpt-lambdaLambda関数の作成
この資料通りに、マネジメントコンソールのLambda関数の作成でコンテナイメージを選択し、ECRにpushしたものを選べばOKです。
Lambda関数の設定で、メモリとタイムアウト時間を変更しておきます。
rinna/japanese-gpt2-medium の場合、メモリは2048MBではたりず、3072MB必要でした。

測定結果と見積もり
100トークン生成した場合の測定結果です。
課金期間 147329ms になりました(147秒)。

オハイオの場合、Lambdaの単価は以下の表の金額です。
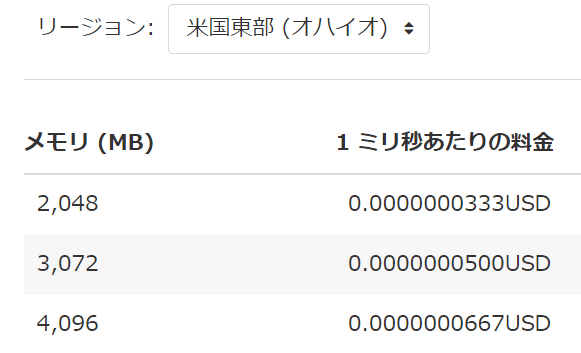
メモリ3,072MBの場合、1ミリ秒当たりの料金は 0.0000000500USD なので、2022/10/29時点の為替レートを使うと、
0.0000000500[USD/ms] x 147329[ms] x 147.46[円/USD] = 1.08円
100トークン1回生成あたり、1.08円になりました。思ってたより高い…(0.1円ぐらいを期待していました)。
EC2との比較
EC2だと、メモリ3G以上で安めのt4g.mediumで計算すると3,567円なので、月に3000回以上生成しないなら、Lambdaのほうが安いです。
0.0336[USD/h] x 30[日] x 24[hour/日] x 147.46[円/USD] = 3,567円

SageMakerサーバレス推論
調べていて初めて知りましたが、AWSの機械学習サービスSageMakerにもサーバレス推論機能があります。
価格表を見ると、3,072MBメモリだと秒あたり0.00006USDなので、推論時間がLambdaと同じと仮定すると1回あたり1.3円で、Lambdaより若干高いです。
実測したわけではないので、もしLambdaとは裏のCPUが違う場合、課金時間が変わる可能性はあります。
0.00006[USD/s] x 147[s] x 147.46[円/USD] = 1.3円

この記事が気に入ったらサポートをしてみませんか?