
勉強メモ#3 (richmanbtcさんチュートリアル手法で試行錯誤)

前回まで
richmanさんチュートリアルを読んで実際にbotを稼働させるところまで出来た。
前回note↓
勉強メモ#2(python機械学習で仮想通貨bot作成)
今回は、僕の手法を実装してみようと思っていたが、損益グラフがすでに右肩上がりだったrichmanさんの手法を使っていろいろ改良してみることにした。
といってもどこから改良すれば良いかわからなかったので、思いついた順にとりあえず手を動かしてみた。下記はそのメモだが、二転三転します。結論を先にいうと、損益グラフが完璧な右肩上がりじゃなくても、損益を予測するモデルの精度さえ良ければいいじゃんと思いました(この辺の深掘りは次回noteで)。
どうしてチュートリアルの手法そのままでは儲からない?
バックテストで右肩上がりだから実運用でも使えそうなのに、richmanさん曰く、今のままでは儲からないらしい。
なぜか。その理由がわかれば改良して儲かるbotにできるはず。

以降、今のままでは儲からないとおっしゃる理由を予想して改良してみる。
予想(その1):エラー率の改善
予想というかチュートリアルしたときに気になった点。
今のコードそのままだとエラー率は約0.008。

Richmanさん曰く、0.00001以下が良いらしい。
なので約0.008は800倍大きい数値なのでめちゃくちゃエラー。
エラー率0.00001以下を目指して改良していこう。
そもそもエラー率とは、
バックテストの結果が「False Positive(本当は偶然なのに、偶然ではないと判定されてしまうこと)の確率」
らしい。エラー率が低いほどバックテスト結果は信頼できて、バックテストどおりの結果が実運用で出せますよ、と理解した。
次に、じゃあどんなパラメータがエラー率に影響するのか考えた。
まず最初に思いついたのはティックデータまわり。
ティックデータの質と量を向上すればエラー率が小さくなるだろうと考えた。
ちなみにあとで気づくことになるが、この時点では、特徴量がエラー率に影響するとは思いもしなかった。特徴量はバックテストの「成績」に影響はしても、成績の「真偽」にまで影響するとは思えなかったから。
話をティックデータに戻すと
質は外れ値処理、
量は時間足を小さくしてデータ数を増やす
ことでエラー率を小さくできると考えた
ただし、外れ値処理に関してはrichmanさんはしてないそうなので僕もしないことにした(https://note.com/btcml/n/ne5f730bb7c64)。
時間足を15分足より小さくしてみた(大きくもしてみた)

時間足が小さくなるにつれエラー率大きくなってる、、、なぜ。
例えば、試行回数が10回より100回の結果の方が信頼できる、みたいなことだと思ってたけど違ったみたい。
エラー率の計算式を確認してみた。
エラー率=(mean(p) * N) ^ N / N!
mean(p):p値の平均
N:mean(p)を算出するときに使った期間N個(チュートリアルではN=5)
ここでようやく気づく。ここでいうエラー率は、バックテストの結果に対するエラー率ではなく、算出したp値の平均に対するエラー率だと。
で、式をみると、エラー率の改善=p値の平均の改善、だとわかる。
予想(その2):p値平均の改善
前々回のnoteで、「p値平均が小さい=すべての期間で安定して儲かる」と理解。具体的には、0.03以下が良いらしい(上記式にあてはめるとエラー率0.00001以下になるね)。今のp値平均は約0.2なので10分の1くらいにできれば良い。
次に、どうやってp値平均を小さくすればよいか。まずは式をみてみた。

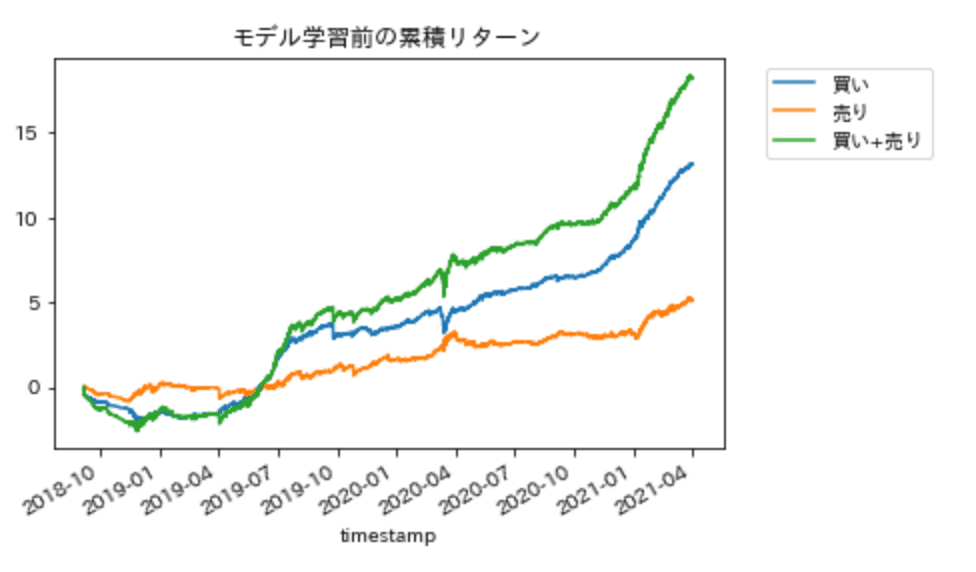
p値平均(p_mean)は、累積リターン(df['cum_ret'])に依存していることがわかる。累積リターンが凹むことなく綺麗に右肩あがり=すべての期間で安定して儲かる、と理解。
今回だと、赤丸の凹んだ部分がp値平均が大きくなってる原因かもしれない、と予想。

試しに、凹んだ部分(2019年7月以前)を取り除いてp値平均を算出してみる。結果はp値平均が約0.2→約0.04まで小さくなった(エラー率も約0.008→約6.4x10^-7まで小さくなった)。

#ティックデータ取得部分を変更
df = df[(df.index > pd.to_datetime('2019-08-01 00:00:00Z')) & (df.index < pd.to_datetime('2021-04-01 00:00:00Z'))]
凹んだ部分(2019年7月以前)がp値平均に影響を与えていることがわかったので、その部分が凹まないように累積リターンを改善できれば良い。
累積リターンは、指値位置や時間足、特徴量選択、モデル選択などたくさんのパラメータに依存している。ぼくはまずは、エントリー部分(指値位置、時間足など)から手を加えてみようと思った。特徴量選択やモデル学習の前にすでに凹んでたので(グラフ↓)。
損益予測モデルの精度
ここでいきなり話が飛ぶが、
エントリー部分をいろいろ触ったけどうまくいかず行き詰まってたときに、そもそも累積リターンが凹むことを予測できれば良いんじゃない?と思いました。凹むと予測したときはポジション持たなければ良い話だし。
ということで次回は、今の予測モデルの精度(正解率?)を調べる→精度向上、の流れでいきます。下記richmanさんのnoteで勉強します。
以上、ご購読ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?