
StableDiffusionで生成した画像から3Dモデルを"AIで"作成し、Unity上でキャラクターを動かすまで【CSM AIの使い方】

この記事に書いてあること
Stable Diffusionで萌え立ち絵画像を作るまで。
-使用モデルとOpenPoseの紹介
-背景を削除する「Rembg」の使用
CSMAIでの3Dモデル生成方法
-会員登録からモデル生成までの流れ
-有料・無料の出来栄えの違いについての検証。
AI製3Dモデルにアニメーションを設定する方法。
-Mixamoにモデルをアップロード
Stable AudioでBGMを作成する
Unity上で動かした結果
↑最終成果物(記事を楽しみたい人は後で見よう)
昨今のAIサービスに何があるのか、どんなことが出来るのか色々触って確かめる。
今回は
「なるべく楽してunity上で動く3D萌えキャラ」
の作成を目指す。
◆きっかけ
1枚の画像から3Dを生み出せるというサイトを見つけた。
しかも、無料。
こんなのを見たら、誰だってフルAIで3Dキャラクターが作れないかなと夢見るはず。
最終目標はunity上で元気に動く萌えキャラの姿を見ること!
ということで、以下のツールを駆使してなるべく楽して3Dキャラを作ってみる。
CSM.ai
-上記のサイト
Stable Diffusion
-プロンプト一発で萌えキャラ立ち絵が作れるご存じAI
Mixamo
-クソ3Dモデルでもスキニングしてアニメーションを付けてくれる
Unity
-萌えキャラ3Dが動く場所
↑使用ツール
GO!!!
1.「Stable Diffusion」でキャラ画像を作成する
StableDiffusionのインストール方法は割愛する。
※調べれば無限に方法が出てくるので・・・
今回はWeb-UI形式で画像生成を行っている。
ここでは、3D生成に適した立ち絵を生成するコツを書く
1.1.プロンプトについて
masterpiece,best quality,virtual youtuber, toddler, ((concept art, official art,full body)), simple background,(children under 10 years old:1.2),standing,solo,(T-pose:1.2)今回使用したプロンプトは上記の通り。
(モデルの等身を下げるために、出力キャラの年齢を下げている)
ポイントは"concept art, official art,full body,T-pose"のプロンプトだろうか。
これらを含めることで、T-poseじみたものが出るようになる。
ネガティブプロンプトについては以下の通り。
"EasyNegative, no_humans ,painting ,sketches ,(low quality, worst quality:1.5) ,deformed ,bad anatomy ,lowres ,monochrome ,grayscale ,ugly face ,half-open eyes ,deformed eyes ,open mouth ,long body ,inaccurate limb ,bad hands ,mutated hands ,mutated legs ,missing fingers ,extra fingers ,extra arms ,text ,error ,cropped ,jpeg artifacts ,signature ,watermark ,username ,artist name ,out of focus ,make-up ,(mascara)1.4 ,rouge ,face paint"
EasyNegativeを使用していることは品質を上げるポイントの一つかも。
1.2.使用モデル
かわいい。
safetensors形式のファイルをダウンロードし、models>stable-diffusionフォルダ配下に配置。
これらの手順を経て、今のところ生成される画像はこんな感じだろう

CSM-AIは少しでも人物が斜めになってると3Dモデルが左右対称じゃなくなる!!
1.3.ControlNetの使用
純粋なT-Poseを作るには、もっと正確なポーズ指定ができる方法が必要。
ネット上の叡智(下記など)を参考にさせて貰いながら、OpenPoseを導入する。

OpenPose Editorで作ったポーズデータはJSON形式でエクスポートできる。
自分が作って実際に使ったものは下記のJSONファイル。
インポートして使ってください。
JSONをインポートしたら、「Send to txt2img」を押下。
txt2img画面のControlNet項目である「Image」にポーズデータが設定されるので、更に下記のようにControlNetの設定を行う。

出来たのがこれ。

女の子は綺麗にT-poseだが、いらない背景まで出てきてしまったので、消す方法を探してみる。
1.4.Rembgの使用
なんと、勝手に背景を切り取ってくれるプラグインがStable-Diffusionには存在する。
その名も「Rembg」
・インストール方法
「Extensions」タブ→「Install from URL」を選択し、以下のURLを入力してインストールを押すだけ。
https://github.com/AUTOMATIC1111/stable-diffusion-webui-rembg

その後、「Installed」タブにrembgがあるのを確認して「Apply and Restart UI」で再起動すればOK

再起動したら、「Extra」タブを開いて対象の画像をセット。
左下の赤枠内「Remove-background」の項目をセットして生成する。
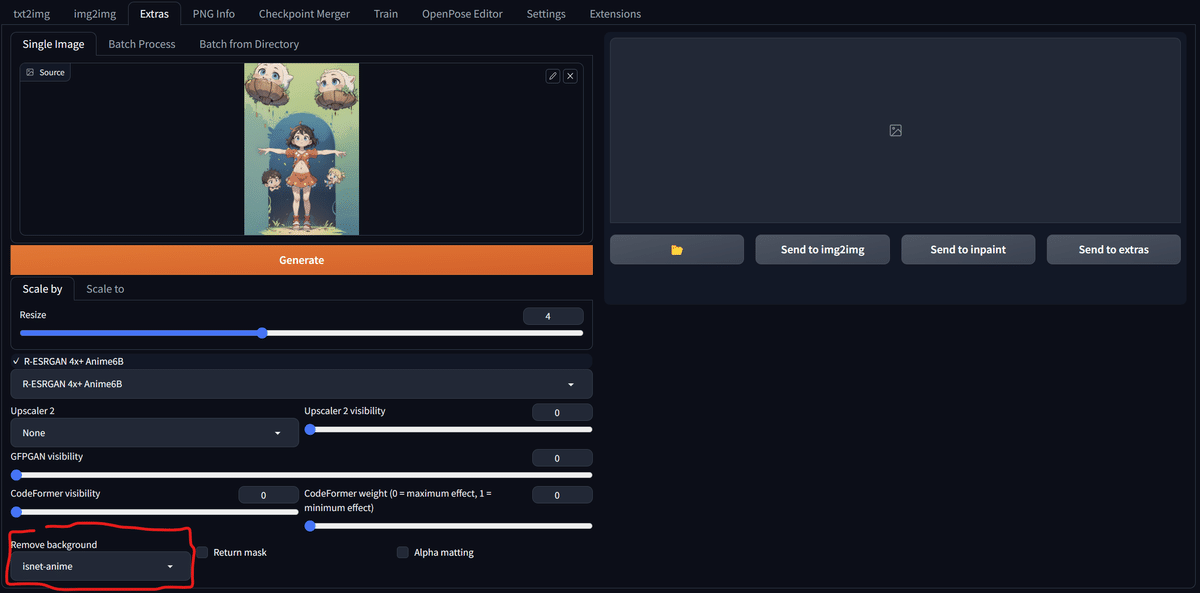
どうだ!?

ついでに350dpi化(CSM用にはここまでする必要はなさそう)
あの複雑な背景から、ここまで画像を抜き出せるのは凄い。。(左)
しかし、色々といらないパーツが多いので手直し(右)
これで画像は完成!!!
2.「CSM.AI」で3Dモデル作成
2.1.無料アカウントを作成する。
上記URLへアクセスし、アカウントのサインアップを行う

すぐにアカウント作成は完了するので、ログイン画面に戻り、Googleアカウントからログインを行う。
2.2.画像をアップロード→モデル作成
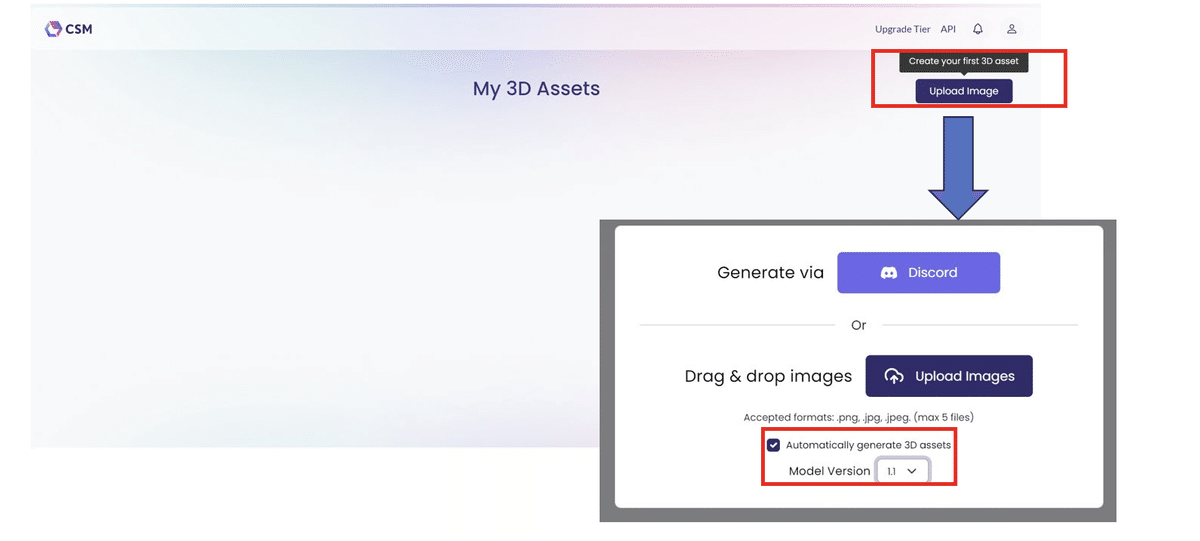
後は画像をうpして待つだけの簡単な作業
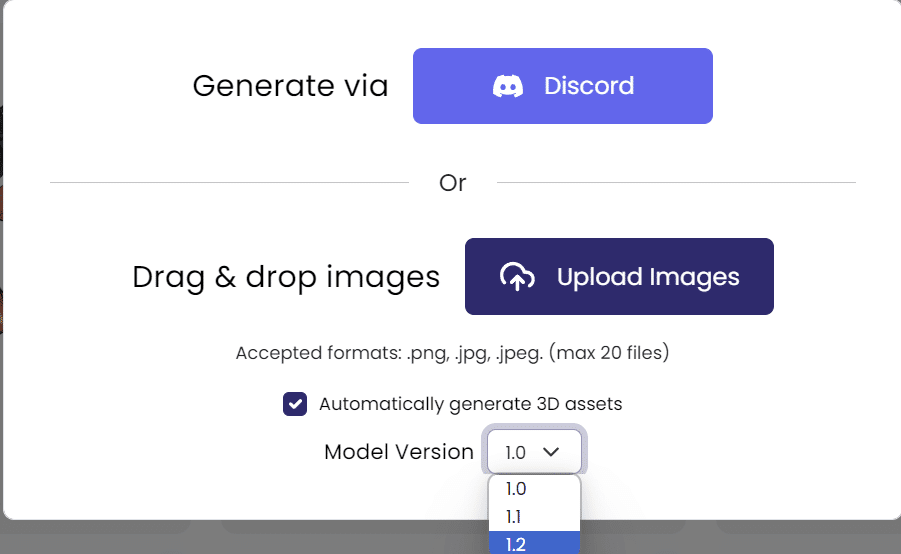
ログインすると、真っ白な「My 3D Assets」画面が表示されるので、右上のアップロードイメージから「Model Version」を指定して画像をアップロード
アップロードが完了すると、以下のようにアセット画面が更新される。
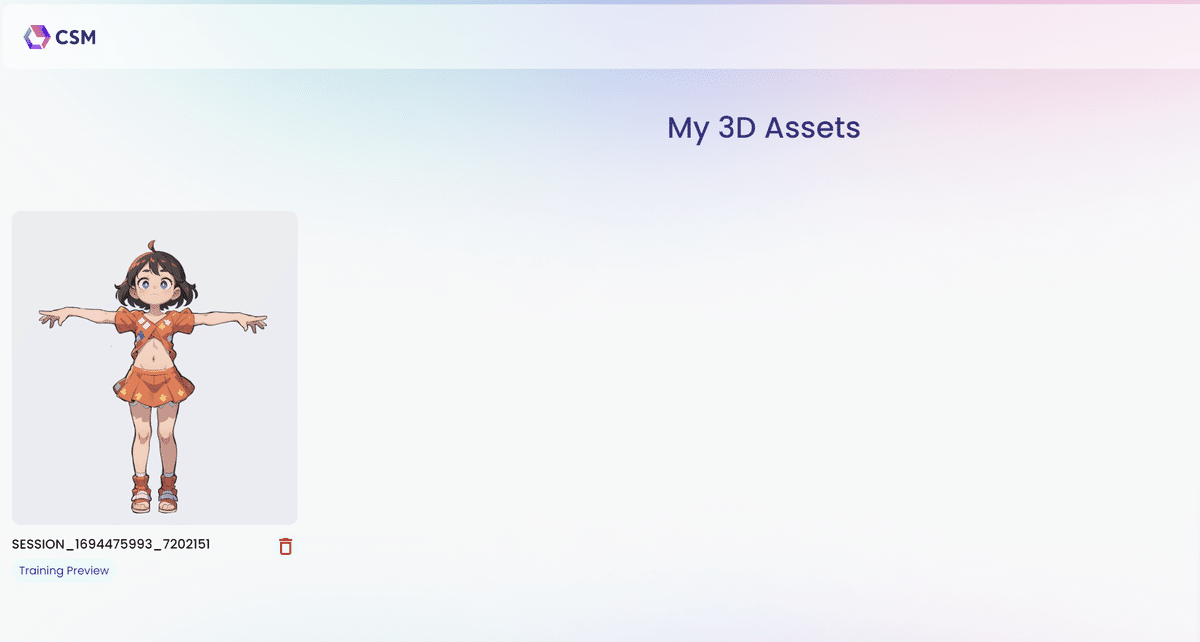
画像をクリックすると、以下のように四面図(?)のプレビューが見れる。
右の空白部分に、これから生成される3Dモデルが配置される。

ここから1時間ほど待機していると、「Training Preview」から「Refining」にステータスが変化する。
そうなると、「3Dの下書き」のようなぐちゃぐちゃしたモデルが表示されるようになる。

「Refining」の完了までは数時間掛かるので、暇を潰して待ちましょう。
2.3.ご対面
Refining DONE・・・

悲しい。お腹の大きなスリットは、恐らくセンシティブであるという理由で隠されてしまったんだろう。。(口開いてるのはなんでだ・・・)
確かに画像一枚からこれが出るのはスゴイが、コレジャナイ
そういえば、これは無料プランでのモデル作成であった。
有料プランだとどうなるのか。希望をあきらめきれないので試す。
2.4.有料プラン編
先ほど「Tinkerer」の無料プランを選択した画面で「Maker」プランを選んでみる。

「Select」を押すと、下記のようなポップアップが出てくるだけでトップに戻るが、30分くらい待てば(長い)メールが届くので連打しないようにする。

CSMからメールが届いたら、記載URLに飛び、決済情報を入力すれば晴れて「Maker」プランで「Pro 3D Model Quality」なるクオリティの3Dが作れるようになる・・・らしい。
これが恐らくProクオリティ・・・
Model Version 1.2を選択し、先ほどと同じ画像をアップロードする。
果たして・・・

2.5.ご対面2
Refine Done・・・

少し良くなった、気もする。

大分、自分の中のハードルが下がっている気もするが、"良くなった"というポジティブな気分の波に乗って、作業を進めることにする。
2.6.OBJ形式で出力
プレビュー画面右上の「Download Mesh」ボタンを押下し、OBJ形式で出力する。
Zipでダウンロードされるが、解凍はしないでおく。

これでCSMでの作業は完了となる。
テクスチャを手直ししたい場合など、Blenderに一度読み込ませると良いが、手直しできるならしてみろと聞こえてくるレベルの惨状なので、気合が必要。

3.「Mixamo」でアニメーションの設定
3.1.Mixamoにアップロード
ここからの操作は以下の記事を参考にさせて頂きました
Mixamoを開いて、先ほど出力したOBJファイルをインポートする。
MixamoもAdobeアカウントのサインアップが必要なので、Googleアカウントに紐づけるなどして、サインアップを終わらせておく。

そして、先ほどダウンロードしたZIPファイルをそのままアップロードする。
3.2.オートリギング&アニメーション設定
アップロードが終わると確認画面が出るので、正しいモデルがアップロードされていることを確認して「Next」を押下する。
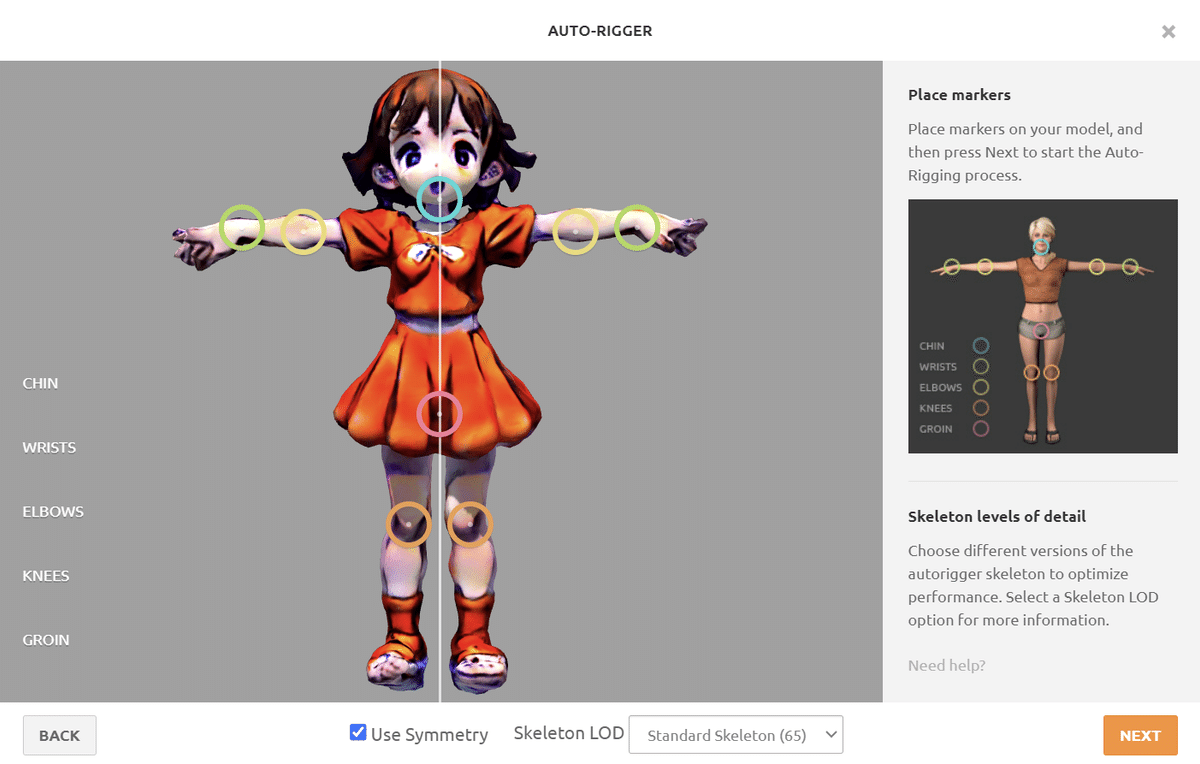
すると、下記画面になるので、サークルをドラッグアンドドロップで配置する。
顎は、先端より気持ち上の方に設定すると良い。
NEXTを押すと・・・
動いた。

Mixamo凄い。しかし、動くともう誤魔化せない。
萌えの要素など、もはや欠片も存在しない。テクスチャがひど過ぎる!
色々なアニメーションが用意されているので、勇姿を見届けよう。
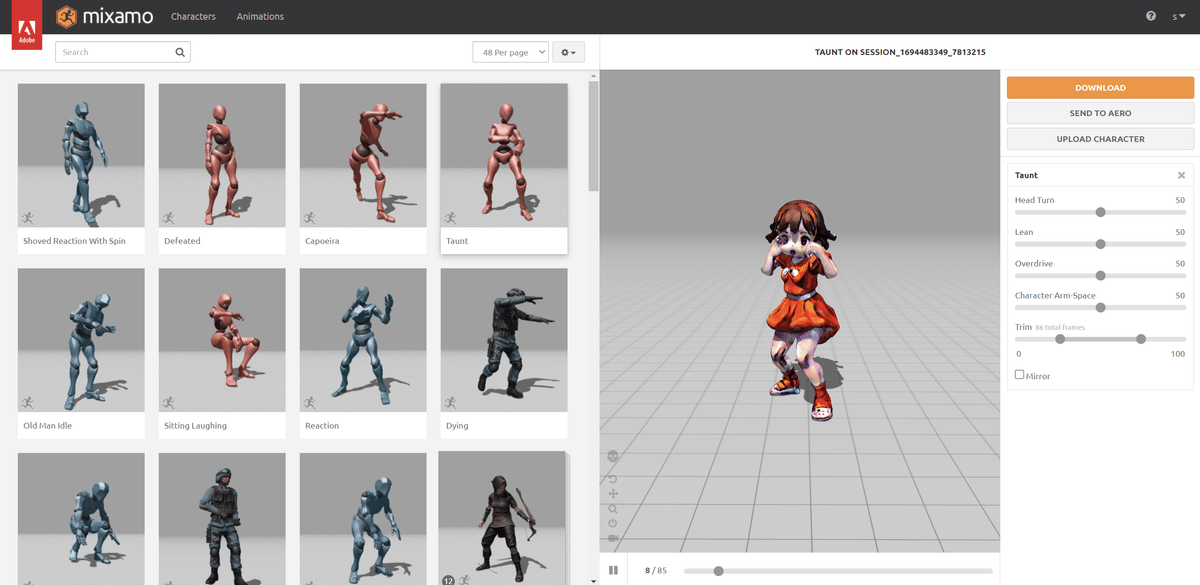
ちなみに、無料版の3Dモデルはこんなことになった。

頭(髪)と胴体が繋がってしまっているので、身体の動きに引っ張られて顔が伸びてしまっている。。。(口が開いてるのがまず論外なのだろう)
有料版のモデルの方も、髪の毛と輪郭が繋がっているので、髪が変形すると顎も変形してしまう。。
とにかく、Unity上で使うアニメーションを選択し、ダウンロードしておく。
さっきのダンスや、軽いランニングアニメーションを今回はダウンロード。
ダウンロードセッティングを特にいじる必要はありません。

以上で、Mixamoでの作業は完了です。
ここまで来たら、BadEndが明らかでもやり遂げて、この女の子を成仏させてあげなければならない。
4.「Unity」でモデルを踊らせる
ついにクライマックス、Unityで萌えキャラ3Dを踊らせる。
既に目的は達成できそうにないが、もしかしたらUnityのすごい力でなんとかなるかもしれない。(ならない)
4.1.作成したモデルをUnityにインポートする
Mixamoで出力したモデルをインポートする。

インポートされたFBXファイルをクリックして、インスペクターから以下の変更を行う。
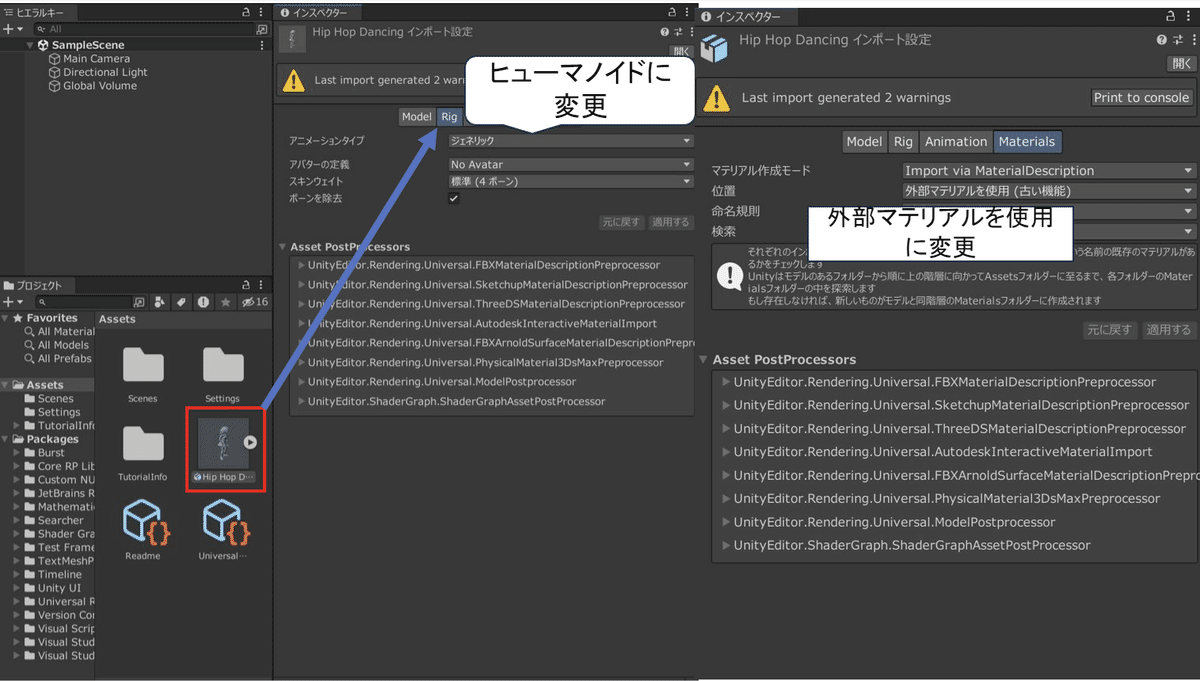
これでFBXファイルを「シーン」に配置する準備はOKなので、配置してみる。
しかし・・・
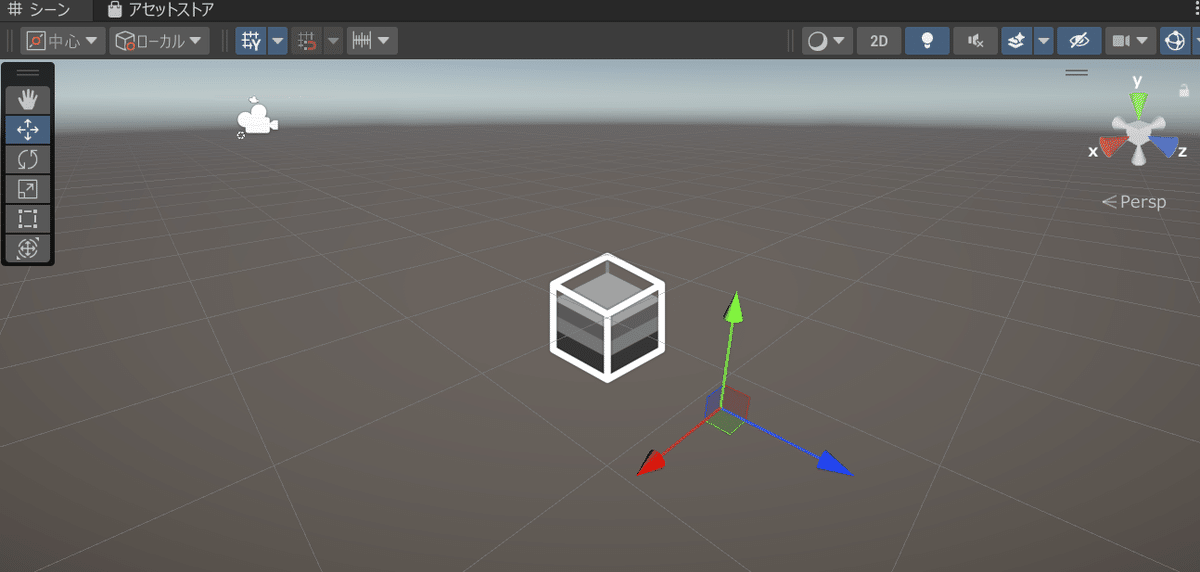
自分のFBXファイルはこんなことになってしまった。モデルファイルに何か問題があったのだろうか。
試行錯誤するも、実際はそんなことはなく・・・
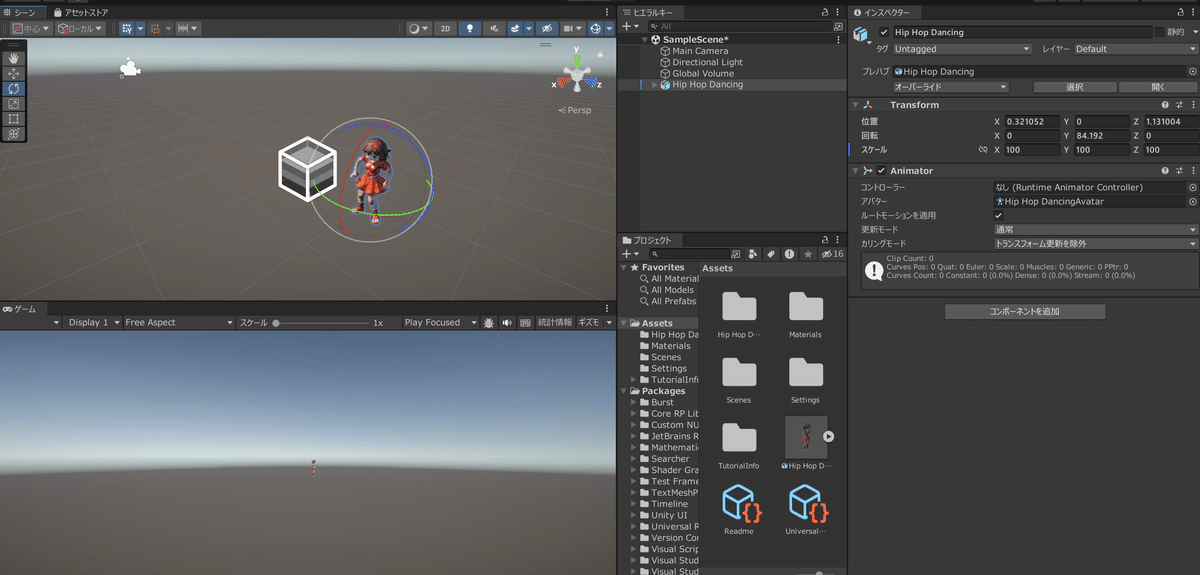
初期はサイズが小さすぎて見えないだけだった。
これで1時間はハマったので、気を付けてください。
4.2.モデルにアニメーションを実装する
プロジェクトウインドウ上で右クリックし、「作成」>「アニメーターコントローラ」を押下する。
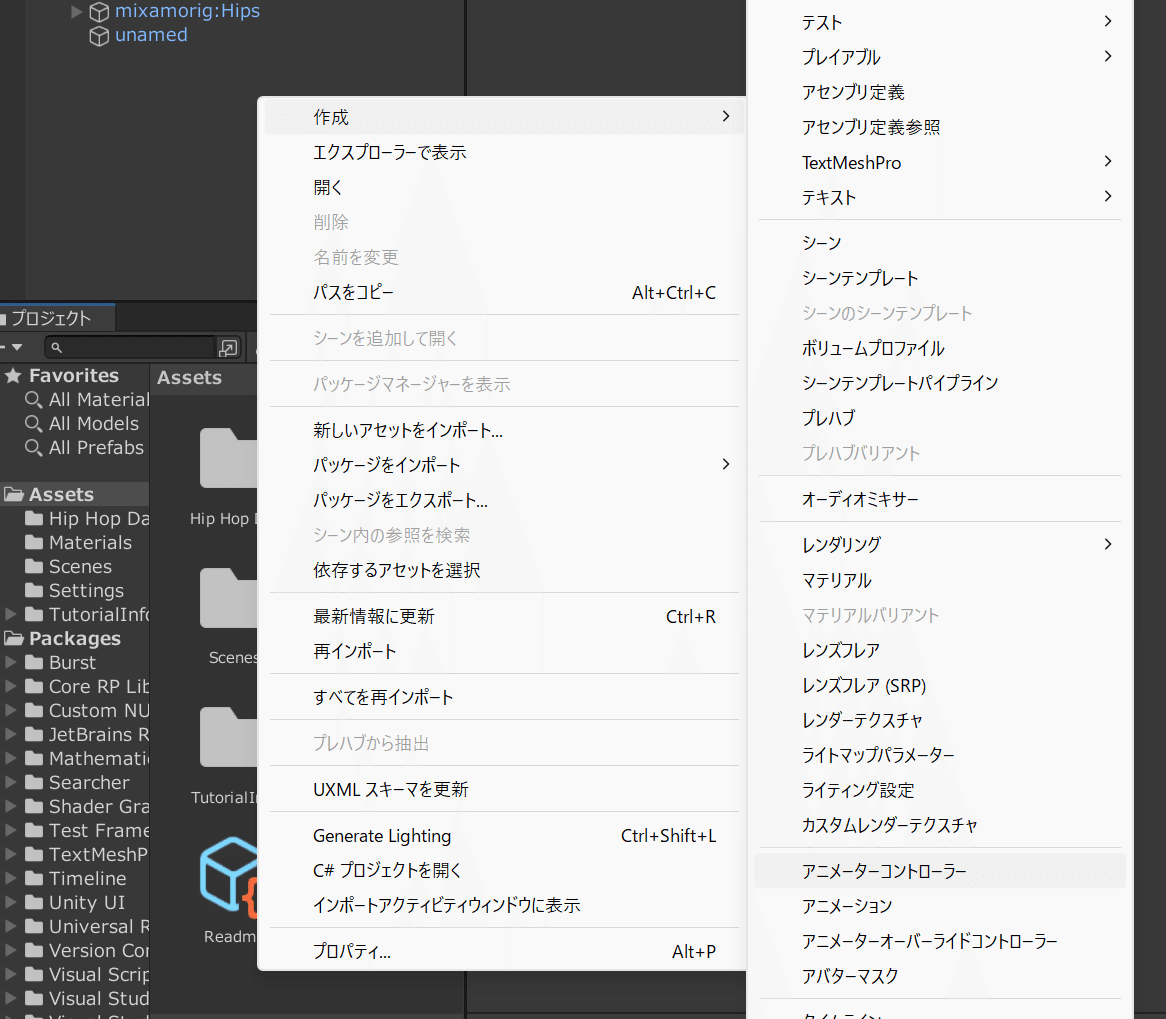
すると、アニメーターコントローラファイルが新規作成されるので、適当な名前を付ける。
ダブルクリックするとアニメーターウインドウが表示されるので、以下のように操作を行う。

※アニメーションを無限ループさせる場合
作成したステート上で右クリック->「遷移を作成」を押下。
その後、作成したステート自身を押下することで、無限ループとなる。
アニメーターコントローラができたら、配置したモデルに追加してあげよう。

この状態で「Play」を押してあげると・・・

しかし、これでは味気ない。
4.3.舞台セッティングと音響
萌えキャラとダンスといえば、教室。
ということで、昔購入していた下記のアセットを引っ張り出した。
そして、先程の様にモデルを配置した結果・・・
・
・
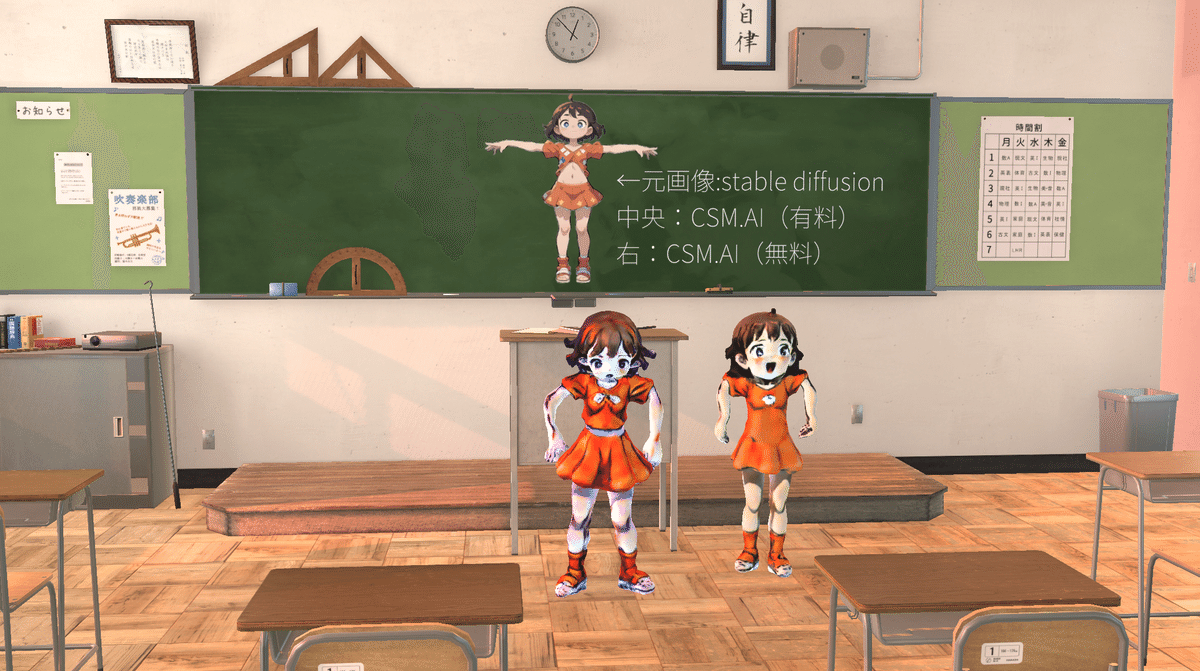
黄昏時の"エモ"い教室に置いたところでそのクオリティを誤魔化すことは出来なかった。
カメラマンにも、映りが良くなる位置まで引いてもらいました。
せっかく作ったので、無料版ちゃんも右に添えた。
中央の元画像については、Planeで平面を作成し、「legasy shaders/trans palent/cut out/softedge unlit」シェーダを設定することで、透過テクスチャを貼れた。
無音の中、ダンスする映像を撮っても虚しいだけだったので、AIにBGMまで作ってもらった。↓
アニソンという概念は難しかったらしく、"K-POPのような何か"が出来上がった。
5.お披露目会
3Dモデル、ダンスモーション、音楽、舞台、全て整ったので、その勇姿を披露してこの記事を終わらせる。
紛れもないクソ動画だが、そのギコちない姿にもはや愛着が生まれてしまった。
6.感想
・Stable Diffusionについて
自分の表現したい物を出す力はまだ弱いが、今回のようにT-Poseのキャラ原案を任せるくらいのことは容易い(著作権云々を棚に上げるが)
OpenPoseによるT-pose指定は、CSM.AIのような画像を"入力"とするサービスで今後も使う機会が多いと考える。
ControlNetの"Reference Only"機能を使うことで、同じキャラの色々なアングル・ポーズの画像を作ることも出来るため、要求される画像枚数が増えても問題にならないだろう。
しかし、2023/9現在、ゲームやサービスとして売り出すものを作る場合、画像生成AIを使うというのは世論的にも法的にも非現実的と思える。
・CSM.AIについて
形を作る能力はかなり高いと思うが、今回のモデルのように「頭」「首」「胴体」といったパーツ分けが上手くできず、モーションを適用すると破綻する。
今回は萌えキャラを作ろうとしたが、これはかなり苦手な部類のモデリングっぽい。
冒頭のCSM AIのプロモーション映像に出ているような、写実的造形なら更なるクオリティが期待出来る可能性がある。
しかし、画像1枚から人型を作れるのは驚いた。画像4枚くらい使っていいので、更に精度が上がってほしい。
このサービスの品質が向上したら、ゲームで色々な活用法が出来そう。
イラストからモデルが作れるというのは夢が広がる。
APIは有料会員向けに既に存在している。
・Mixamoについて
CSMで作られる3Dモデルはトポロジが終わっていて、手動でアニメーションを付けるとなると途方もないように思えるが、Mixamoなら一発だった。
API化して欲しい。
プロンプトでアニメーションを自動生成できる日も近そう。
・Stable Audioについて
ついに出てきたStability AIの音楽作成サービス。
まだ変な音楽しか作れない。。
Stable Diffusion以外どのサービスも発展途上と感じた。
が、画像生成AIも半年くらい油断していたらいつの間にか凄まじいクオリティの画像を出せるようになっていたので、1年後くらいにまたリベンジしたい。
これを見て、3D生成AIもこんなことしか出来ない時代があったんだなと思える日が来るように。
バイバイ

良ければ、フォローといいね!をよろしくお願い致します。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?