
俺の株価予測(pythonでのデータ分析)」

※このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
自己紹介
保険営業マンとして活動する傍ら、キャリアの軸を増やすためにデータ分析について関心を持ち学習をスタートする。
あわよくば自身の営業活動にも活用できるのではないかと考えAidemy Premium「データ分析コース」を3ヶ月受講。
実行環境
Google Colaboratory (Google Colab)
Python 3.10.12
!python --version
Python 3.10.12分析概要
Nvidia社の株価データを使用して終値を予想する分析を実施
簡単に取得できるような株価データを用いて、回帰分析を行っていきます。
最終的にその精度も出せればと思っています。
(1)データの準備
Yahoo! Financeから直接「2022/11/01~2024/07/01」までのCSVデータを取得して⇒Google CorabにそのCSVをアップロードするやり方もありますがpandasのライブラリを活用する方が簡単です
株価取得コードを用いて、以下のコードで直接取得することが可能
・pandas_datareader (経済データや株価等を取得できるライブラリ)
・yfinance (Yahoo!ファイナンスから情報を取得するライブラリ)
#yahooファイナンスから株価を取得するコード
#必要ライブラリのインポート
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
#変数dataにNvidia社('NVDA')の株価データを代入。期間はstart,endで指定
data = pdr.get_data_yahoo('NVDA', start='2022-11-01', end='2024-07-01')
data.head() #データ内容の確認(2)データの加工
持ってきたデータを、使える形に加工したり、不要部分を削除したりします。
一般的に、Volume(出来高)が関係してくるといわれていますので、出来高を使いたいと思います。
例えば、「出来高を週で合計すると翌日の予測ができたりしないかな」と考えてみた際のコードが以下になります。
#--元データの基本準備
# カラムから不要項目を削除。'始値', '高値', '安値','終値(Closeのほう)'
data_chart = data.drop(['Open', 'High', 'Low','Close'], axis=1)
# 日付順に昇順に並べておく。
data_chart = data_chart.sort_values(['Date'])
#--説明変数列&目的変数(ラベル列)追加
#'Volume_WeekSum'列を追加し、当日までの7日間(約1週間)の出来高を記載
data_chart['Volume_WeekSum'] = data_chart['Volume'].rolling(window=7).sum()
#'label'列を追加し、その日の"翌日"(1日後)の'調整後終値'を記載
data_chart['label'] = data_chart['Adj Close'].shift(-1)
#通常head()の5行だけだと7日分合計されているか見えないため、10行表示
data_chart.head(10)

先頭の6行に欠損値が出るので、削除しておきます。
data_chart = data_chart.dropna()
#最初5行と最後5行を表示させる
data_chart
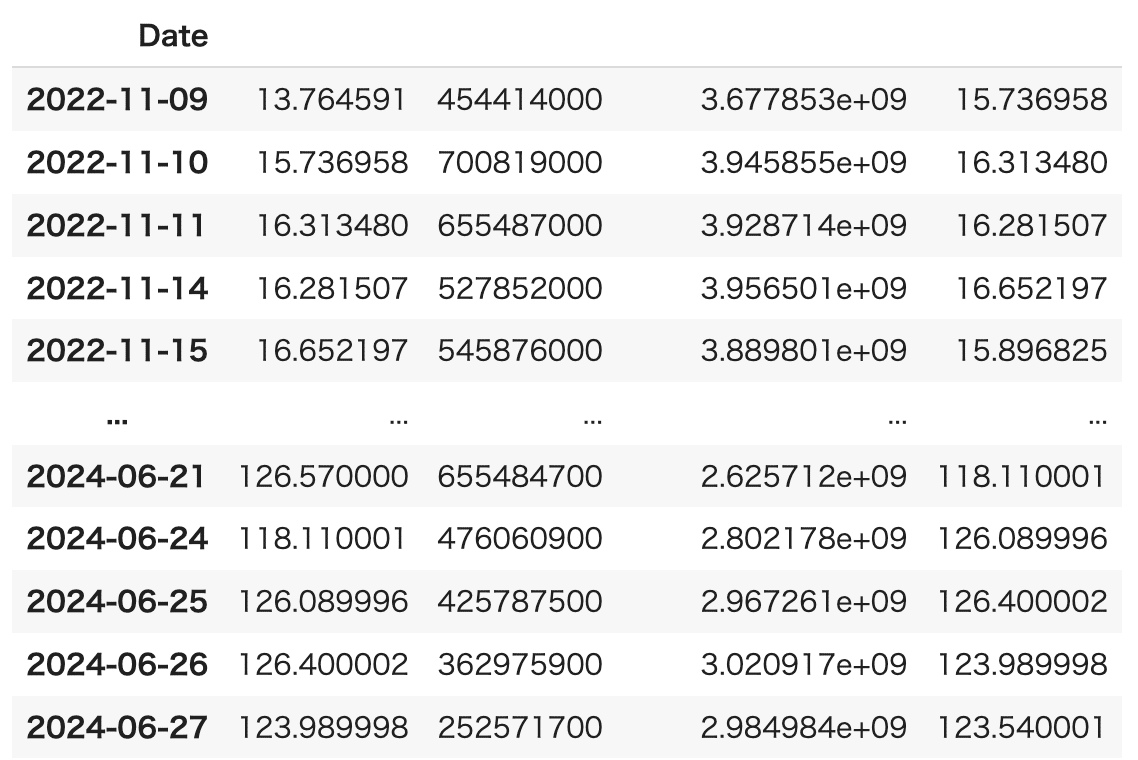
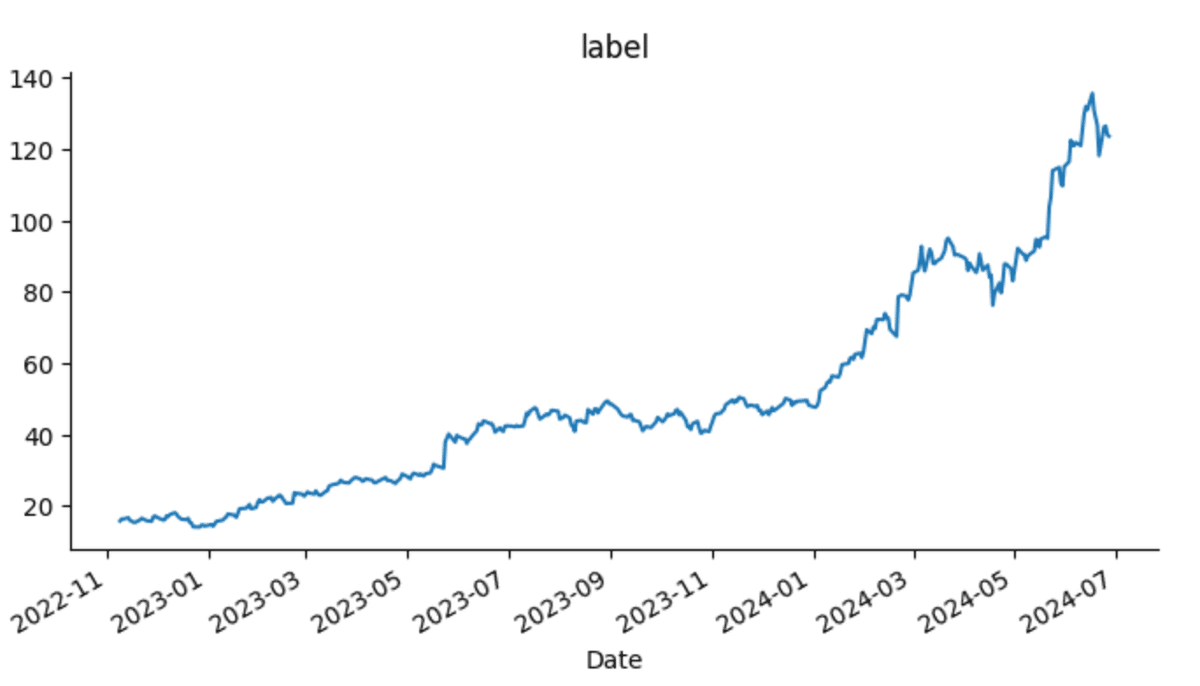
3)データの分析
pythonに用意されているモジュールを用いて、実際に動かしてみます。モデルはLinearRegressionで実行。
*回帰分析は、予測したいデータに対し、すでにわかっているデータの関係性を元に推定するアプローチ。
線形単回帰
1つの予測したいデータ(例:水の量)を1つのデータ(例:時間)から求める回帰分析です。主にデータの関係性を調べるときに用いられます。
ラッソ回帰
データとして余分な情報がたくさん存在するようなデータの回帰分析を行う際に使用。例えば、データセットの数(行数)に比べて、各データの数(列数)が多い場合には、ラッソ回帰を利用する。
リッジ回帰
リッジ回帰は汎化(様々な異なる対象に共通する性質、共通して適用できる法則などを見出すこと)しやすい特徴があり、L2正則化を行いながら線形回帰の適切なパラメータを設定する回帰モデル。
ElasticNet回帰
ラッソ回帰とリッジ回帰を組み合わせて正則化項を作るモデル。メリットとして、ラッソ回帰で取り扱った余分な情報がたくさん存在するようなデータに対して情報を取捨選択してくれる点と、リッジ回帰で取り扱った 汎化しやすい点が挙げられます。
# xに説明変数(元データから目的変数列を抜いたdataset)を、yに目的変数(調整後終値)を格納
x = data_chart.drop(['label'],axis=1)
y = data_chart.values[:, 3]
#train_test_splitを使って、「訓練データ」と「検証データ」を8:2に分けます。(test_size=20%)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42, shuffle=False)
#線形回帰をモデルとして構築
model = LinearRegression()
#訓練データを読み込み
model.fit(x_train, y_train)
#x_testデータを使ってy(ラベル)の方を予測をさせます
pred_y = model.predict(x_test)
# 予測結果を出力
#print(pred_y)
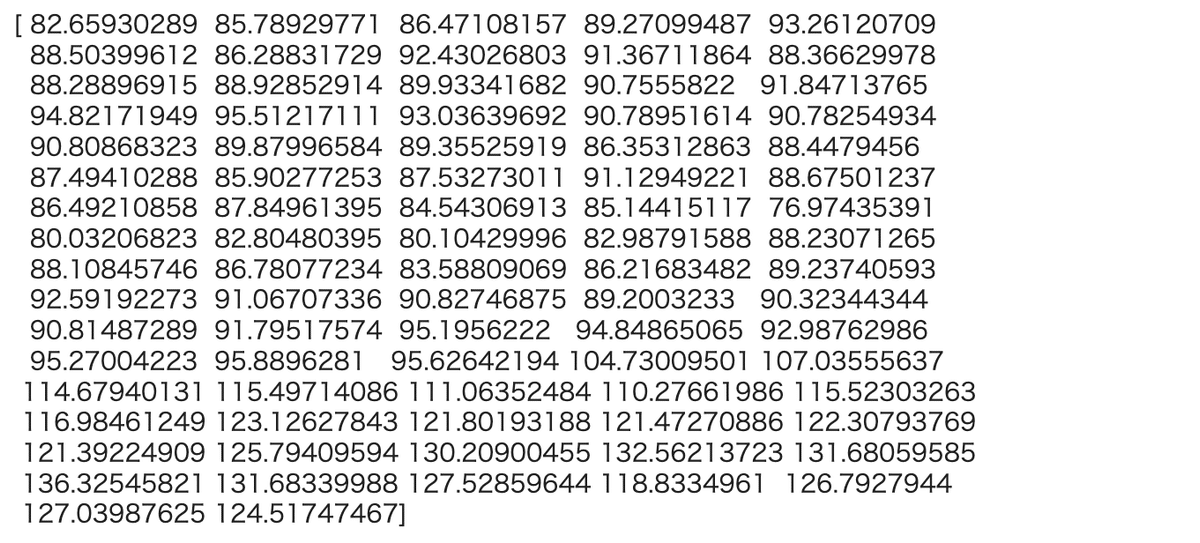
(4)精度を確認する
重回帰分析での手順として精度を確認したいと思います。
・決定係数R^2は、正解データ内のばらつきに対して予測値のズレが小さいほど値が大きくなります。
決定係数は1以下の値を取り、おおよそ0.8以上の数値であれば精度よく予測ができていると言えるそうです。
#model.score()で決定係数を出力
print("決定係数は:" , model.score(x_test, y_test) ,"です")
各モデルでの精度検証
ある程度の精度は出ていますが、より良い検証を実施するために各モデルでの精度も確認しておきます。
#各種必要モジュールをインポート(追加分のみ)
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
#結果表示用に、「もっともよい決定係数のモデルの値」「その名前」を入れる変数
#(それぞれUseModelScore,UseModelName)の初期化
UseModelScore = 0
UseModelName = ""
# 線形回帰---------
model_Linear = LinearRegression()
model_Linear.fit(x_train,y_train)
# 決定係数を出力
print("LinearRegression:{}".format(model_Linear.score(x_test, y_test)))
# 先頭なのでそのまま値を入れる
UseModelScore = model_Linear.score(x_test, y_test)
UseModelName = "LinearRegression"
# ラッソ回帰---------
model_Lasso = Lasso()
model_Lasso.fit(x_train,y_train)
# 決定係数を出力
print("Lasso:{}".format(model_Lasso.score(x_test, y_test)))
# UseModelScoreと比較し、スコアが高ければ上書き
if UseModelScore < model_Lasso.score(x_test, y_test):
UseModelScore = model_Lasso.score(x_test, y_test)
UseModelName = "Lasso"
# リッジ回帰---------
model_Ridge = Ridge()
model_Ridge.fit(x_train,y_train)
# 決定係数を出力
print("Ridge:{}".format(model_Ridge.score(x_test, y_test)))
# UseModelScoreと比較し、スコアが高ければ上書き
if UseModelScore < model_Ridge.score(x_test, y_test):
UseModelScore = model_Ridge.score(x_test, y_test)
UseModelName = "Ridge"
# ElasticNet回帰---------
model_ElasticNet = ElasticNet()
model_ElasticNet.fit(x_train,y_train)
# 決定係数を出力
print("ElasticNet:{}".format(model_ElasticNet.score(x_test, y_test)))
# UseModelScoreと比較し、スコアが高ければ上書き
if UseModelScore < model_ElasticNet.score(x_test, y_test):
UseModelScore = model_ElasticNet.score(x_test, y_test)
UseModelName = "ElasticNet"
print("最もスコアの高かったモデルは {0} で、その値は {1} でした".format(UseModelName,UseModelScore))
結果
Nvidiaの株価データの一部と「直前1週間の出来高合計」を変数として重回帰分析を行った場合、Ridge回帰を用いたものが精度の高い結果となりました。
一つの考察として今何かと市場で話題のNvidiaですが、何となくの投資姿勢から一歩進めた投資への参考に出来なくもない、、と思います。
さらに踏み込んだ予測の展開としては、米国内における政局動向などをSNSなどから読み取っての株価への影響などを考察するなど、様々なアプローチからの分析を考えていきたいと思います。
まとめ
まだまだ実務レベルとはいきませんが、テーマを設定した中での「データ分析」をなんとか実施しました。
講義の中でもよく言われていることですが、分析にあたっての目的、テーマからデータの選定についてが分析結果の成否に大きなウェイトを占めていることがよくわかりました。
今後のデータ分析の活用に目を向ける中では、まずは自身の本業の営業活動を効率的に行う中でのマーケティングに取り入れながら実践を進めたく考えております。
また、提案するお客様への提案付加価値としてデータ分析を駆使することも考えてみたく思います。
ここからスモールステップで活用展開を始めます。
この記事が気に入ったらサポートをしてみませんか?