
転勤先の雪の積雪量を予測してみた

はじめに
自己紹介
理系大学を卒業し、新卒で大手ゼネコンに就職。3年間勤務後退職。
データサイエンティストへの転職を目指して勉強中です。
受講に至った経緯
建設会社ではデータが有効に利活用されていないという点に課題感を抱き、この課題を自身で解決できる人間になりたい、最新の技術に触れて仕事をしたいと考え、データサイエンティストへ転職希望をするようになりました。
スクールをAidemyに決めた理由は、データ分析で使用される頻度が高いPythonが学べる点、教育訓練給付金の支給対象(約70%還元)である点です。
積雪予想
データ内容
【期間】2000年~2023年の4月までの降雪量合計
【場所】岐阜県高山市
気象庁の公式サイトからダウンロード
実行環境
Google Colaboratory
1.データの読み込み
まずは必要なモジュールをインポートしておきます。
import pandas as pd
import warnings
import itertools
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inlineダウンロードしたデータがgoogle drive内にあるので、driveとcolabを接続してから、colab上でdrive上のファイルを読み込みます。このとき先頭の2行をカラムとします。
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/MyDrive/takayamadata.csv',encoding="SHIFT-JIS",header=2)csvファイルのパス取得は下記画像の様に行います。
ちなみに私はGoogle ColaboratoryではなくGoogle Drive内でパスを探していたのでここで時間がかかりました。


2.データの整理
予測したい値の時系列データの1列だけ(積雪量1列)のDataFrameを用意し、indexが集計時期となるようなデータフレームを作成します。またそのデータを時系列分析に適用して期間を予測していきます。
df = df[['年月日','降雪量合計(cm)']]
df = df.dropna()カラム名を分かりやすいように年月日→'Date'、 降雪量合計→'Snowfall'に変更します。
df = df.rename(columns={'年月日': 'Date', '降雪量合計(cm)': 'Snowfall'})Dateをdatetimeに変換し、indexとします。
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')3.orderの最適化関数
ここでパラメータを選択するために、時系列データ:DATA, パラメータs(周期):sを入力すると、最も良いパラメーターとそのBICを出力するselectparameteという関数を定義していきます。
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]4.モデルの構築
いよいよモデルの構築です。
今回積雪量予測は時系列データなのでSARIMAモデルを用いて時系列解析をしていきます。
SARIMAモデルは、ARIMAモデルをさらに季節周期を持つ時系列データにも拡張できるようにしたモデルの為今回の予測に適したモデルとなっています。
best_params = selectparameter(df, 12)
SARIMA_model = sm.tsa.statespace.SARIMAX(df.Snowfall, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()周期は月ごとのデータであることも考慮して1年は12カ月なので、s=12となります。
orderはselectparameter関数の0インデックス, seasonal_orderは1インデックスに格納していきます。
5.予測
pred = SARIMA_model.predict('2016-01-20', '2023-4-26 ')predに予測期間での予測値を代入していきます。
6.グラフの可視化
plt.plot(df)
plt.plot(pred, "r")
plt.show()予測値は赤色でプロットします。
7.結果
こちらが実行結果となります。
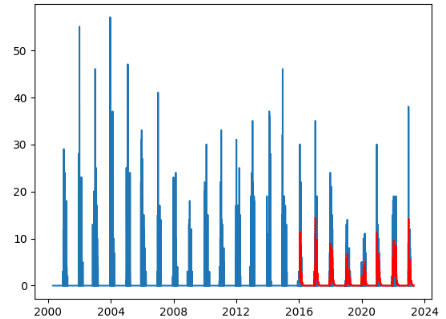
このグラフを見ると、赤の部分の予測が正解(青の部分)に比べてある程度正しく予測することができていることが分かります。
ただ最大積雪量が正しく予測できていなかったので、もう少し正確に予測するためには最高気温や最低気温、湿度、風速などもデータに入れると精度を上げることができるのかなと思いました。
まとめ
今回のアイデミーのデータ分析講座の受講によってデータの扱い方、様々なデータ分析方法の流れを学ぶことができました。ここから実践的なことについては実業務等で学んでいくため転職活動をしていきたいと考えています。
プログラミングは奥が深く日々勉強が必要になるので継続して学んでいきたいと思います。
この記事が気に入ったらサポートをしてみませんか?