【Python】ロジスティック回帰の自然勾配降下法

機械学習の学習アルゴリズムではさまざまな数理最適化が活躍していますが、Takayuki Uchiba先生のロジスティック回帰の自然勾配降下法の記事がとても面白かったのでPythonで真似してみました。
理論的な説明とRでの実装はTakayuki Uchiba先生がして下さっています。
私はこれをPythonに翻訳して再現してみることにしました。
デモデータの生成
まずは2次元正規分布に従う乱数を生成します。
・ラベルy = 1のデータポイントを母平均(1, 1), 母分散Eで生成する。
・ラベルy = 0のデータポイントを母平均(-1, -1), 母分散Eで生成する。
import numpy as np
each_size = 100
dim = 2
#2変数の平均値を指定
mu_1 = np.array([1]*dim)
mu_0 = np.array([-1]*dim)
#2変数の分散共分散行列を指定
sigma_1 = np.eye(dim)
sigma_0 = np.eye(dim)
X_1 = np.random.multivariate_normal(mu_1, sigma_1, each_size)
X_0 = np.random.multivariate_normal(mu_0, sigma_0, each_size)
X = np.vstack((X_1, X_0))
y = np.array([1 if i < each_size else 0 for i in range(2*each_size)])簡単に可視化してみます。
import matplotlib.pyplot as plt
plt.plot(X_1[:,0], X_1[:,1], 'o', c='b',label="2d", alpha=0.5)
plt.plot(X_0[:,0], X_0[:,1], 'o', c='r',label="2d", alpha=0.5)
plt.show()
それっぽいのが生成されました。
train test splitします。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
y_train, y_test = y_train.flatten(), y_test.flatten()ロジスティック回帰と勾配降下法による学習
まずは勾配降下法の実装です。
# 事前に必要な関数を準備しておく。
def sigmoid(x):
return np.divide(1, (1+np.exp(-x)))
def d_sigmoid(x):
return sigmoid(x)*(1-sigmoid(x))
def cross_entropy(y, p):
return np.mean(-y*np.log(p)-(1-y)*np.log(1-p))
# 各更新時の損失のhistoryを記録するlistを準備する。
loss_GD = []
# Step 1 : 初期値と学習率ηを決める。
w = np.zeros(dim) # 偏回帰係数の初期値
eta = 0.1 # 学習率
size = len(y_train) # 訓練データのサンプルサイズを取得しておく。
# Step 2 : 更新のiteration, 今回は10回更新する。
for i in range(10):
# forward計算
x = np.dot(X_train, w)
p = sigmoid(x)
loss_GD.append(cross_entropy(y_train, p))
# 勾配の計算
dp = (p - y_train) / (size * p * (1-p))
dx = d_sigmoid(x)
dw = np.dot(X_train.T, (dx*dp))
# wの更新
w = w - eta * dw
loss_GD_test = cross_entropy(y_test, sigmoid(np.dot(X_test, w))) # テストデータでの損失自然勾配降下法
続いて自然勾配降下法の実装です。
# 各更新時の損失のhistoryを記録するオブジェクトを準備する。
loss_NGD = []
# Step 1 : 初期値と学習率ηを決める。
w = np.zeros(dim) # 偏回帰係数の初期値
eta = 0.1 # 学習率
size = len(y_train) # 訓練データのサンプルサイズを取得しておく。
# Step 2 : 更新のiteration, 今回は10回更新する。
for _ in range(10):
# forward計算
x = np.dot(X_train, w)
p = sigmoid(x)
loss_NGD.append(cross_entropy(y_train, p))
# 勾配の計算
dp = (p - y_train) / (size * p * (1-p))
dx = d_sigmoid(x)
dw = np.dot(X_train.T, (dx*dp))
# Fisher情報行列の計算
grad_logLL_x = (y_train - p) / (p * (1-p)) * dx
grad_logLL_w = np.tile(grad_logLL_x, (X_train.shape[1],1)).T * X_train
# grad_logLL_w = matrix(rep(grad_logLL_x, each = ncol(X_train)), nrow(X_train), ncol(X_train), byrow = TRUE) * X_train
F = np.cov(grad_logLL_w.T)
# wの更新
w = w - eta * np.dot(np.linalg.inv(F), dw)
loss_NGD_test = cross_entropy(y_test, sigmoid(np.dot(X_test, w))) # テストデータでの損失結果の確認
損失の可視化とtest dataでの損失を比較してみます。
plt.plot(range(1,11), loss_GD, marker = 'o', label = 'Gradient Descent')
plt.plot(range(1,11), loss_NGD, marker = 'x', label = 'Natural Gradient Descent')
plt.xlabel('iteration', fontsize = 16)
plt.ylabel('loss', fontsize = 16)
plt.tick_params(labelsize=14)
plt.legend()
plt.show()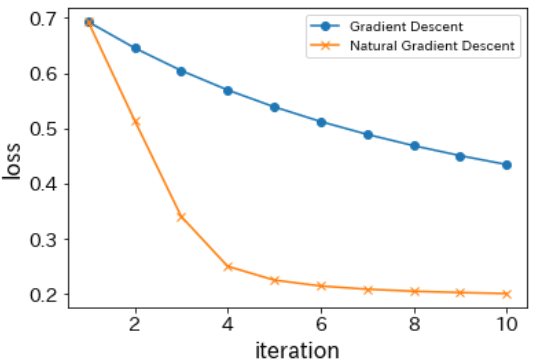
print("GD test loss", loss_GD_test)
print("NGD test loss", loss_NGD_test)GD test loss 0.3789858581403511
NGD test loss 0.10529183853917327
だいたい再現できました。よかった。Takayuki Uchiba先生ありがとうございます。
おわりに
最近、勾配ブースティングに自然勾配を応用したNGBoostが注目されていて、こちらも面白そうなので以下の情報などを参考に練習したいと思っています。
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Github : stanfordmlgroup/ngboost
kenmatsu4さんのkaggle Kernel
この記事が気に入ったらサポートをしてみませんか?