結局コピー機学習ってなんなの?
コピー機という言葉がひとり歩きしている気がするので、ふわっとした理解の人間がふわっとした表現で書きます。
嘘を書くつもりはないですが、正確性を欠く可能性はあるので、大目に見てください。
通常のLoRAにおける"差分"胸のサイズを小さくするLoRAを作成すると仮定する。
この場合、「胸のサイズが小さい絵」を素材として用意して学習させることになる。
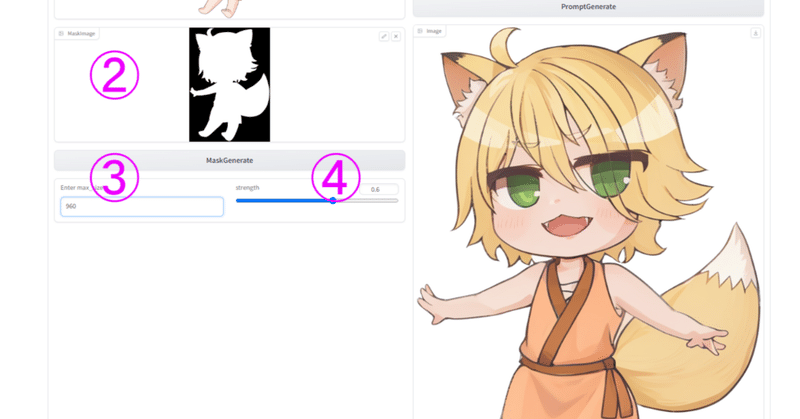
よくあるパターンとして、キャラクターのみを切り抜いて背景を白にした素材を用意したとする。
キャプショニング(タグ付け)は「1gir