Photo by
dhjnk
E検定対策(8) - K-Means法を用いた分類

今回はK-Means法の勉強をしました。学習成果の他にも、どのようなケースをK-Means法は苦手としているか、簡単な考察もしてみました。

K-Means法を用いたデータセットの分類
ちなみにSKlearnのK-Means法はデフォルトでK-Means++として働くそうです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.cluster import kmeans_plusplus
from sklearn.datasets import make_blobs
plt.figure(figsize=(10, 10))
#データを生成する
n_samples = 1500
random_state = 250
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# K-Means法を使ってクラスターを分類
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("K-Means")
#分布が偏ったデータを分類
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_aniso)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("K-Means - Anisotropicly distributed data")
# 分散が大きいデータを分類
X_varied, y_varied = make_blobs(
n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=y_pred)
plt.title("K-Means - Unequal Variance")
# クラスターの数に偏りがあるケース
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_filtered)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
plt.title("K-Means - Unevenly Sized Blobs")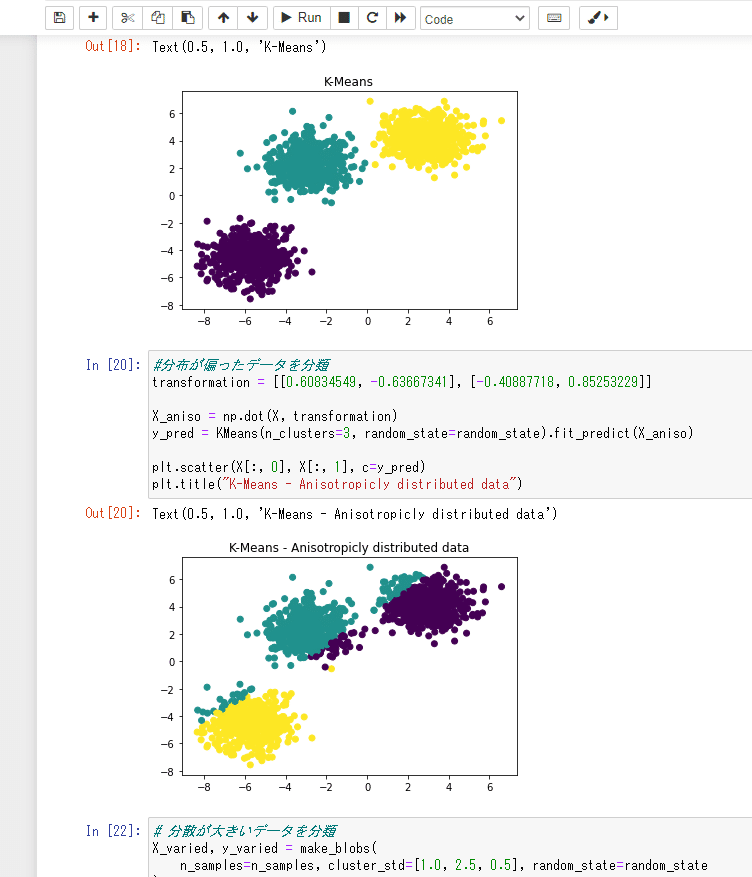
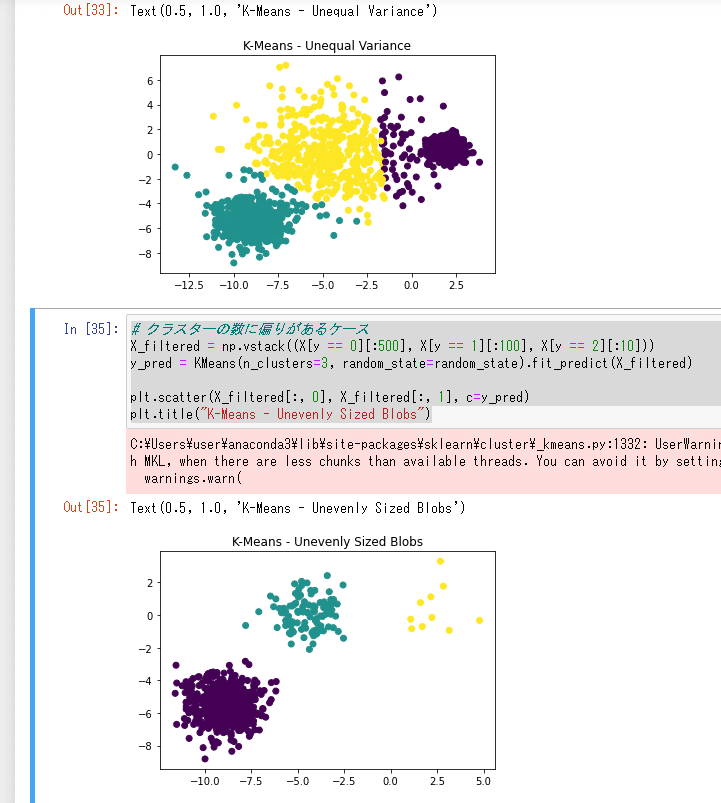
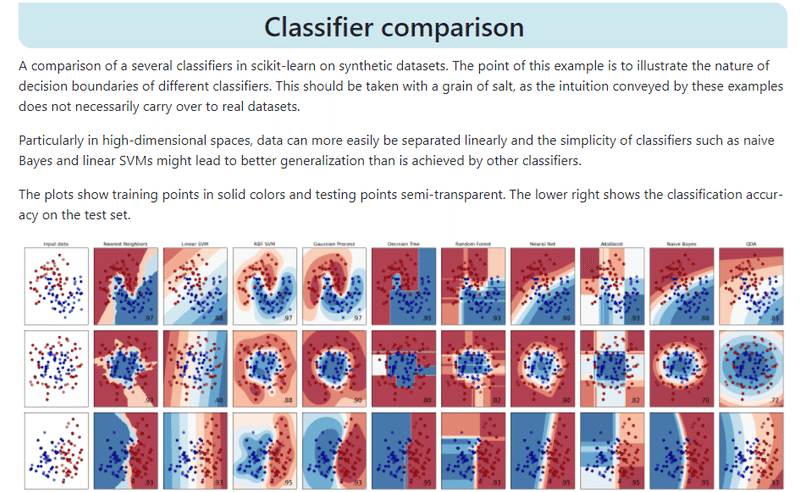
K-Meansは分散が大きいデータの分類、クラスターの数に偏りがあるケースに問題なく対応できますが、分散が縦軸・横軸に偏ったクラスターを分類するとなると途端に不正確になるという傾向があるようです。どのアルゴリズムがデータを正確に分類できるかは詳しくはSKLearnのClassifier Comparisonに図例が載っており、参考になりそうです。
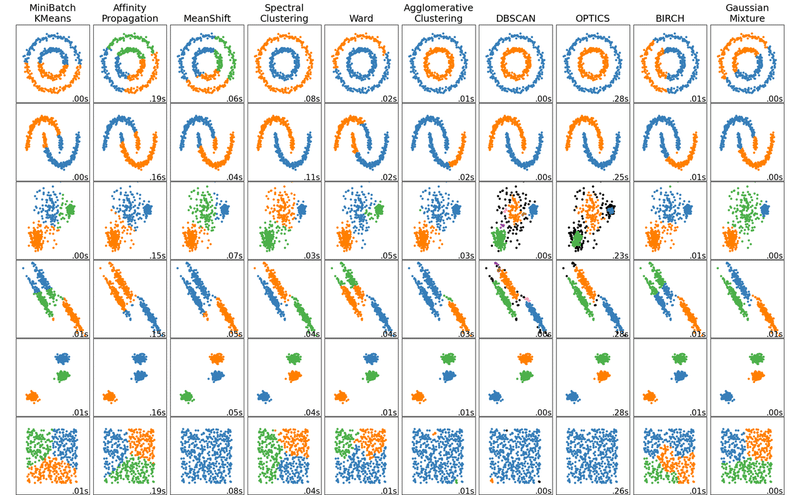
次回はNumpy、Pandas、Matplotlibの復習をした後ニューラルネットの基礎に取り組もうと思います。頑張りましょう!
この記事が気に入ったらサポートをしてみませんか?