オセロAIの教科書 7 【評価】 パターン評価など

この記事集はオセロAI(オセロの相手をしてくれるプログラム)を初歩から段階を踏んで作っていく記事集です。
この記事集「オセロAIの教科書」は私の世界1位AIの技術を中心に、オセロAI(オセロの相手をしてくれるプログラム)を初歩から段階を踏んで作っていく記事集です。全編無料でこちらから読めます。
この記事について、わかりにくい点や疑問点、おかしな点がありましたら気楽にコメントとかTwitterとかで教えて下さい。みなさんの力で記事を洗練したいです。
この記事を読むのに必要な知識
この記事を読むのに必要な(ある程度前提とする)知識を列挙します。これらの知識がない状態で読んでもある程度理解できるとは思いますが、途中でわからなくなったらキーワードとして使ってください。
オセロのルール
基礎的なプログラミングの知識・経験
C++
Python
深層学習(サンプルコードではkerasを使います)
マス評価の悪いところ
これまでの評価関数はマスの重みだけの評価でした。この手法の悪いところは石同士の繋がりを無視してしまっているところです。例として辺に注目して以下を考えましょう。白がAIだとします。
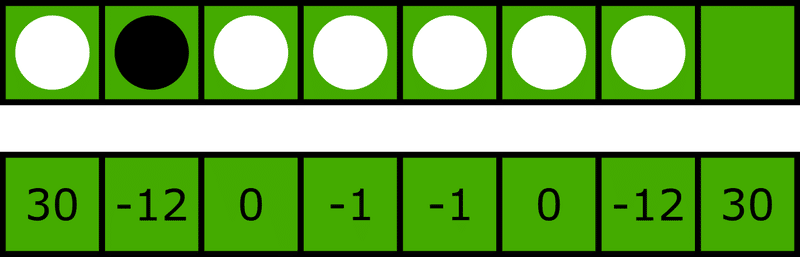
上が盤面から辺を取ってきたもの、下が辺の評価値です。
黒の評価値は-12、白は30+0-1-1+0-12=16となり、評価値的には白、つまりAI有利です。でも、これは白にとって非常に嫌な状態です。
次の手で黒がこう打ってきたらどうでしょう。

黒が辺と隅、白が隅だけしか取れていないので、(他の辺の状態にもよりますが)黒有利です。
このように、マス一つ一つ独立に評価していては、自分の不利に気づかない場合があるのです。
パターン評価
上の例はどのようにして評価したら良いでしょうか。
辺の8マスを全て合わせて評価してしまえば良いのです。
辺全部が白一色だったら白有利だし、上の例のような状態なら黒有利、などとするのです。
例えば辺の8マスについて全パターンが何通りあるかを考えると、3^8=6561通りしかありません。これは十分計算可能な量です(手動で計算はしないのでご安心ください)。
私の世界1位AIでは、合計11種類のパターン評価を使っています。
着手可能数や囲い具合による評価
私の経験上、着手可能数と囲い具合(どれだけ自石が空マスに接しているか)を追加して評価するとかなり精度が良くなります。
これらのパラメータは、近似値で良いのであれば、ボードをインデックス化している場合とても高速に計算できます。そして、評価関数に使うのであれば近似値で十分です。
機械学習を使った世界1位AIの評価関数
パターン評価とその他追加パラメータによる評価関数を作りたいのですが、どうやって大量のパラメータを自動で調整したら良いでしょうか。
私のおすすめは面倒なことを考えなくて済むのに性能が良いので機械学習です。パターンを入力したら内部で何かよくわからないことを計算して、予想最終石差を出力してくれるようにします。
ということで、いきなりですが私の世界1位AIの機械学習モデルをご紹介しましょう。

うん?見えないですね…横3万ピクセルあるらしいです()
ということで、簡単に省略した図をお見せします。
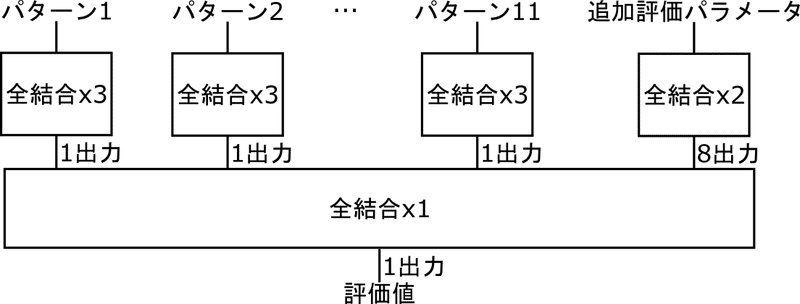
特徴は、各パターンが独立したモデルになっていて、それを入力した全結合層によって評価値が計算されるところです。
こうすることで、各パターン(高々数千、数万通り)を全部前計算できてしまって、パターンごとに計算するはずだった全結合x3を、前計算した配列を参照するだけで計算できてしまいます。
つまり、評価関数実行時に計算しなくてはいけないのは最後の全結合層1つだけです。これはとても高速に計算できます。
サンプルコードの評価関数
さすがに世界1位AIの評価関数は規模が大きく、私のパソコンでも学習にそれなりの時間がかかります。ということで、サンプルコードでは重要そうなパターンに絞った簡易的なパターン評価で評価しようと思います。また、追加パラメータ周りもわかりやすく変更を加えます。
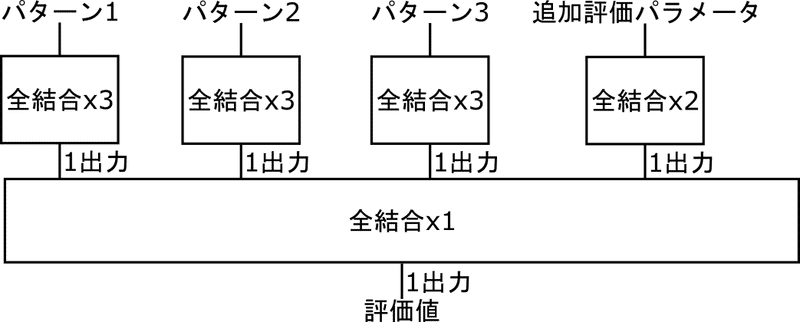
使うパターンは以下の3種類です。

パターン評価部分の機械学習モデル(全結合x3)と追加評価パラメータの機械学習モデル(全結合x2)は以下の形状にしました。
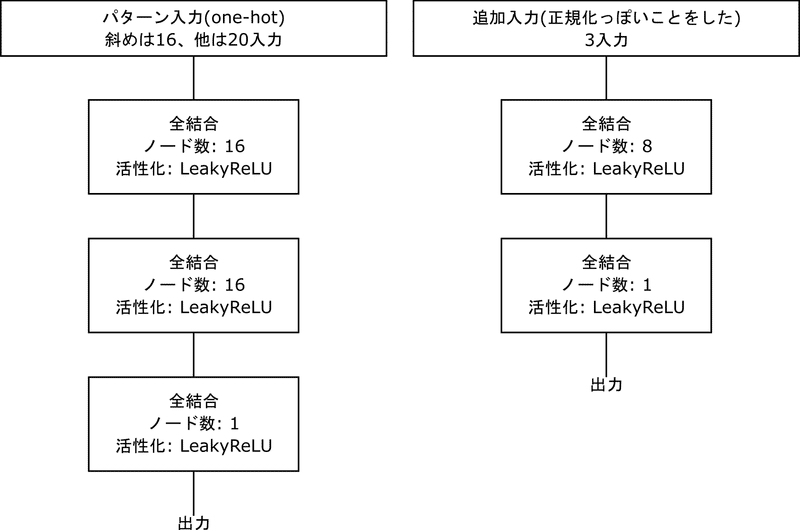
活性化関数がLeakyReLUなのは完全に私の好みです。LeakyReLUは以下の式で表されます。
LeakyReLU(x) = max(alpha * x, x)
今回はalpha=0.01にしました。正直ただのReLUでも良い気がします。
評価関数は後々の前計算を楽にする都合で、必ず黒目線の評価値となるようにしました。
学習
この記事に沿った学習済みモデルは以下で公開しています。自分で改造したり学習したりしたい方はここをお読みください。
学習には教師データが必要です。今回は私の世界1位AI同士で自己対戦させたデータ2万局を公開したので、それを使うことを念頭に置いています。
公開している自己対戦の棋譜はこちら:
これを読み込んで加工して学習します。
学習するコードはこちら:
データ加工時に追加入力を計算する必要があります。Pythonで実装しても良いですが、バグらせそうだったのでC++で書いたものを呼び出すことにしました。実行する際は、これをevaluate.outとしてコンパイルしてください。
実装
機械学習したモデルはPythonから読み込むことを前提に作られていますが、今回はC++で書いたオセロAIから読みたいです。
ということで、私はPythonでモデルのパラメータを抽出し、テキストファイルに書き出しました。そのテキストファイルをC++から読み込んで、あとはC++で愚直に推論を書けば良いです。
評価関数を呼ぶ時に毎回推論しなくて良いよう、かなり前計算しています。込み入っていますが気になる方はサンプルコードをご覧ください。
実行
以下のコマンドで実行します
$ g++ -O3 ai6_pattern_evaluation.cpp -o ai.out
$ python3 main.py探索アルゴリズムは前回の記事で解説したnegascoutそのままで、評価関数だけ置き換えました。
私は先手でも後手でもボロボロに負けました…
ちなみにこのサンプルコード(8手読み)と、私が公開している世界1位AIの4手読みで対戦させたら、サンプルコードが勝ちました。世界1位AIの4手読みはほとんどの人が勝てないレベルなので、このサンプルコードのAIもとても強いということです。
まとめ
どんなに探索性能が良くても、評価関数がガバガバでは何の意味もありません。評価関数はとても大事です。さらに、前回の記事で軽く触れた通り、設計によっては評価関数の性能でmove orderingの性能も決まってしまいます。
評価関数は葉ノード(数がとても多い)で毎回呼ぶ関係上、できる限り高速化しなくてはなりません。特に機械学習で調整したモデルは愚直に推論するととても時間がかかってしまうので、工夫をしてなるべく前計算できるようにしましょう。
世界1位AIでは、評価関数は20手以降を10手ずつ4フェーズに分けた他、使うパターンを増やしたり追加入力のモデルを複雑にしたりしました。
余談ですが、前計算するのであれば機械学習を使わずに各パターンについて重みを適当な最適化アルゴリズムで調整すれば良いという意見があると思います。確かにその通りですし、多くの強いオセロAIはそうしています。しかし、持っている棋譜データに現れないパターンについてはどうしようもなかったり、持っているデータの局所的な偏りに過剰にフィットしてしまう可能性が考えられると私は思っています。機械学習したモデルであれば、そのあたりをうまく調整してくれると私は信じています。
次回予告
オセロに詳しい方はもしかしたらお気づきかもしれませんが、まだこのオセロAIは序盤の打ち方に隙があると思います。これを潰すために次回は序盤の定石を導入します。
スキと投げ銭で喜びます
noteではログインなしでスキできます!役に立ったぞ、面白かったぞ、という方はぜひハートマークをポチッと押してください!
この記事は全編無料ですが、投げ銭してくれたら私が喜びます。喜ぶだけです。何も見返りはありません。「役に立ったし投げ銭してやっても良いぞ」という方はポチっとしてくださると嬉しいです。
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?