オセロAIの教科書 4 【探索】 minimax法

こんにちは、にゃにゃんです。
この記事集「オセロAIの教科書」は私の世界1位AIの技術を中心に、オセロAI(オセロの相手をしてくれるプログラム)を初歩から段階を踏んで作っていく記事集です。全編無料でこちらから読めます。
この記事について、わかりにくい点や疑問点、おかしな点がありましたら気楽にコメントとかTwitterとかで教えて下さい。みなさんの力で記事を洗練したいです。
この記事を読むのに必要な知識
この記事を読むのに必要な(ある程度前提とする)知識を列挙します。これらの知識がない状態で読んでもある程度理解できるとは思いますが、途中でわからなくなったらキーワードとして使ってください。
オセロのルール
基礎的なプログラミングの知識・経験
C++
2手先を読んでみる
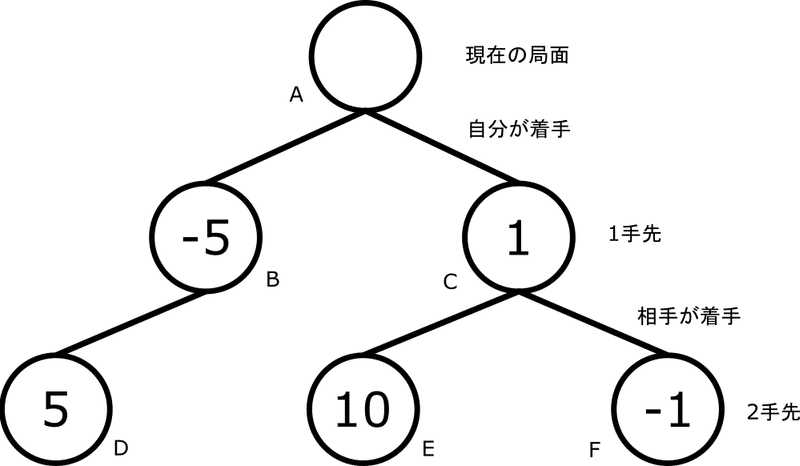
「木」と言われる図を使ってオセロを考えてみましょう。以下のような構造をゲームに使う木として、「ゲーム木」と呼びます。

一番上の○(ノード)であるノードAが現在の局面で、「木の根」と言うこともあります。現在の局面からいくつかの手を打つことができて、最終的にAIは打つ手を選ぶことを目指します。今回はわかりやすく2つの手を選ぶことができるとするので、根から2つのノード、BとCが生えています。
1手読みのときは単純に、この1手先の局面で一番自分に有利な手を打ちましたが、2手読むときはもう一手探索します。
2手先は、ノードBからは1つの局面が、ノードCからは2つの手が分岐しています。
まずはノードBから出てきたノードDを考えましょう。ノードDの中に何やら数字が書いてあります。これは評価値(AI目線)です。値が大きければAI有利、小さければAI不利です。ノードDの評価値を使って一つ上のノードB(このとき、ノードBはノードDの「親」と言います)の評価をしたいです。どうすれば良いでしょうか。
結論を言えば、そのままこの評価値をノードBの評価として使えます。
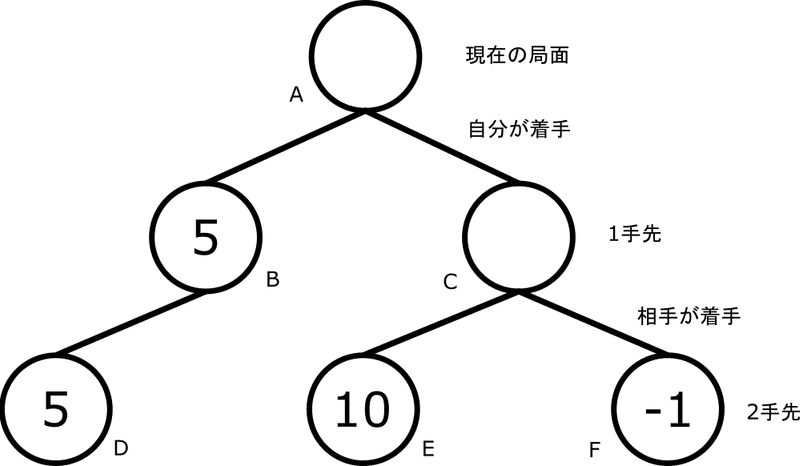
ノードBで評価関数を作用させることはしません。評価関数は原則、探索の末端(図ならノードDとEとFで、根と対の名前で「葉」と言います)のみで使います。
さて、次はノードCの評価をしたいです。ノードCからは2つの局面が分岐しています。どちらの評価値をCの評価として使えば良いでしょうか。もしくは両方使えば良いのでしょうか。
一つのアイデアは子ノード(「親」と対の関係で、あるノードから分岐するノードを子ノードと言います)の評価値の平均値をそのノードの平均値とすることです。これも良さそうではある(実際にこの考えで動くアルゴリズムもある(*1))のですが、もっと良い方法があります。
ノードEの評価値がAI目線で10と、ノードDの評価値よりも大きいので良さそうな気がします。しかし、ノードCからE、Fにかけては相手が着手します。相手は気前よくAIに有利な手を打ってくるでしょうか?十分に相手が強ければ、ノードFに至る手を打ってくるような気がしませんか?
ということで、ノードCの評価値は、ノードCから分岐するノードEとFの評価値のうち、小さい方を採用します。
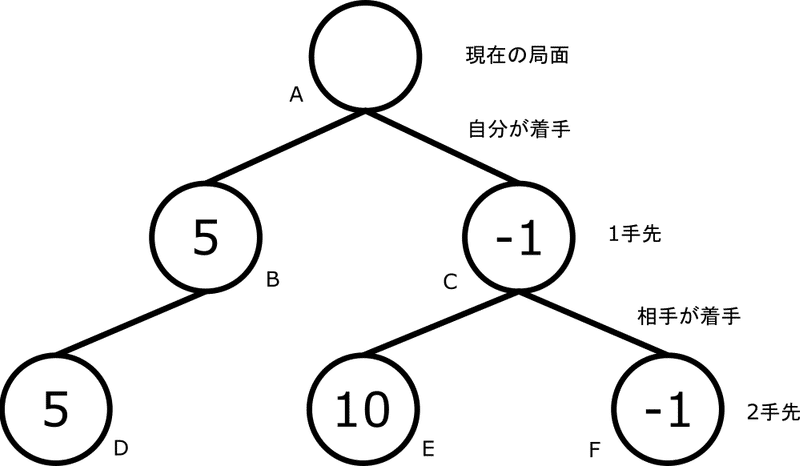
これでノードBとC、どちらを選べば良いかはわかりました。評価が良い(評価値が大きい)方である、ノードBに至る手を選べば良いのです。
このように、子ノードから伝播してきた値をminimax値と言います。
(*1)この記事集で紹介するアルゴリズムは全てこの記事で紹介するminimax法の派生アルゴリズムですが、ゲーム木探索アルゴリズムには別の系統(原始モンテカルロ法やモンテカルロ木探索)があり、そちらのアルゴリズムでは平均値に近い考え方を使っています。興味がある方は調べてみてください。
minimax法
さて、上で考えてみた2手読みは一般的なN手読みに拡張することができます。それをminimax法と言います。
2手読みでは、相手の着手の時に、相手はAIにとって一番嫌な手、つまり評価値が低い手を打つことを考えました。そして、自分が着手するときはもちろん、自分にとって一番嬉しい、評価値が高い手を選びます。
察しがついたでしょうか…?
一般的にN手読みをする際も、相手の手番では自分にとって一番不利な手を、自分の手番では自分にとって一番有利な手を選ぶことで、同じような探索ができます。言い換えれば、評価値を必ずAI目線に作るとすれば、相手の手番では一番評価値が低い手を、自分の手番では一番評価値が高い手を選ぶようにすれば良いのです。
相手の手番ではmin、つまり最小、自分の手番ではmax、つまり最大…そうです、これがminimax法です。
negamax法
minimax法を実装すると、自分の手番と相手の手番で場合分けが必要になってしまい、あまり美しくありません。そこで、実装上ではminimax法と本質的には同じものの綺麗に実装できる、negamax法をよく使います。
negamax法では、minimax法の「最小値」を選ぶ操作を、「子ノードの評価値に-1を乗じたものの中で最大値を選ぶ」と読み替えます。
2手読みの例として使った木で考えてみましょう。
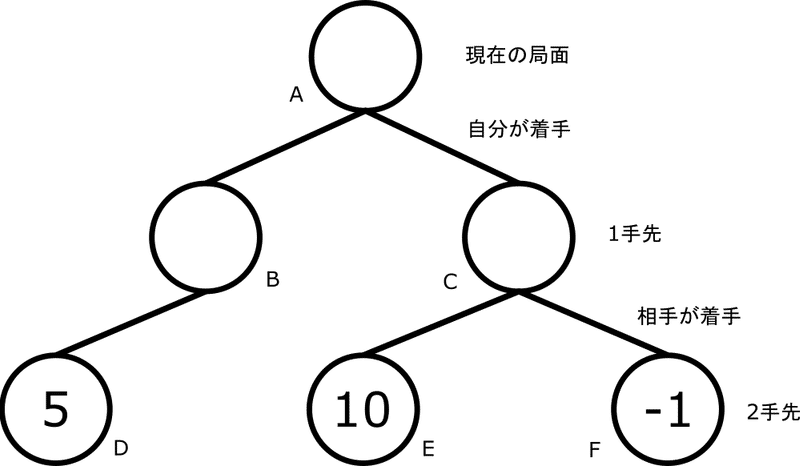
negamax法では必ず評価関数はその盤面から打つ手番目線で評価しなくてはいけません。間違えると激弱AIになってしまいます(*2)。今回は葉ノードから打つのはAIなので、符号はこれまでの例と変わりませんが、もう一手深く読むなら符号が逆になります。
ノードBの評価値はノードDの評価値に-1を乗じたものです。
ノードCの評価値は、max(ノードEの評価値に-1を乗じたもの, ノードFの評価値に-1を乗じたもの)です。
ノードBの評価値もmax(ノードDの評価値に-1を乗じたもの)と書けるので、結局max(子ノードの評価値に-1を乗じたもの)という関数で葉に近いノードから順番に評価値を伝播させていくことになります。
なお、ノードB、Cから手を打つのは相手なので、ノードBとCの評価値は相手目線になっています。これらに-1を乗じたものが一番大きなノードに至る手を選びましょう。
もうお気づきでしょうか、max(-1を乗じたもの)関数こそがnegamax法の名前の由来です。
(*2)意図的に負けることを目指すAIを作る場合、これではうまくいきません。独自の評価関数を作る必要があります。
実装を見てみる
私の実装は以下です。
根幹部分を抜粋します。
// negamax法
int nega_max(board b, int depth, bool passed) {
// 葉ノードでは評価関数を実行する
if (depth == 0)
return evaluate(b);
// 葉ノードでなければ子ノード全部に対して再帰する
int coord, max_score = -inf;
for (coord = 0; coord < hw2; ++coord) {
if (b.legal(coord))
max_score = max(max_score, -nega_max(b.move(coord), depth - 1, false));
}
// パスの処理 手番を交代して同じ深さで再帰する
if (max_score == -inf) {
// 2回連続パスなら評価関数を実行
if (passed)
return evaluate(b);
b.player = 1 - b.player;
return -nega_max(b, depth, true);
}
return max_score;
}
// depth手読みの探索
int search(board b, int depth) {
int coord, max_score = -inf, res = -1, score;
for (coord = 0; coord < hw2; ++coord) {
if (b.legal(coord)) {
score = -nega_max(b.move(coord), depth - 1, false);
if (max_score < score) {
max_score = score;
res = coord;
}
}
}
return res;
}max(子ノードの評価値たちに-1を乗じたもの)という関数を、実装上は、max(これまでの評価値の最大値, 子ノード1つの評価値に-1を乗じたもの)としています。
また、オセロにはパスがあるのが厄介で、2回連続パスのときには終局しているので評価関数を呼ばなくてはいけません。その関係でnegamax関数の引数にpassedが増えています。
余談ですが、evaluate関数を「その手番における値を返す」ようにしていたのはnegamaxで使いやすくするためです。
evaluate関数の実装はこちらです
終局やパスについて(2022/12/22追記)
negamax法でバグを起こしやすいのがパスや終局の処理です。どちらの手番で評価値(または最終スコア)を出力したら良いのでしょうか?
基本的な考え方は、「その盤面から打つプレイヤ目線の評価値」で変わらないのですが、少し補足します。サンプルコードと共に確認してみてください。
パスのとき
子ノードを展開してみて、合法手が一つもなければ、そのまま手番を入れ替え、-negamax(パス後のボード, パスしたことを示すフラグ)を呼びます。このとき、パスしたことを示すフラグをtrueにしておくと次で解説する終局判定の実装がわかりやすくなります。
終局のとき
オセロにおいて終局とは、全てのマスが埋まるか双方の合法手がなくなることを意味します。前者については盤面の石の数を確認して判定できます。また、後者については「パスしたことを示すフラグ」がtrueの状態でもう一度パスする状態になったことを使って判定できます。どちらについても、終局が判定できた段階で「その盤面から打つはずだったプレイヤ目線のスコア」を返すことで対応できます。
なお、深さが0になって評価値を出力する処理は子ノードを展開する前に行うと良いです。深さが0の場合にはパスも何も関係なく評価値を求めれば良いので、ここでパスについて考えると煩雑になってしまいます。
対戦してみる
サンプルコードは4手読みになっています。コンパイルして対戦してみましょう!
$ g++ -O3 ai2_negamax.cpp -o ai.out
$ python3 main.py私(黒) vs AI(白)の結果は以下です。

私はたまに負けてしまいます…
まとめ
実は今回のminimax法の理解がおそらくオセロAIを作る中で一番難しいところだと思います。このアルゴリズムが理解できれば、探索アルゴリズムについては今後、minimax法の派生アルゴリズムしか出てきませんので、ある程度気楽にお読みください。
実装についてはパス判定とか関数の読み替えとかがありましたが、基本的には理論をそのまま実装しただけとなっています。
次回予告
次回はminimax法を一気に高速化できるアルゴリズム、alphabeta法を学びます。さらに、alphabeta法をより効果的に使うための工夫も学びます。
alphabeta法の高速化アイデアの理解は少し難しいですが、丁寧に解説します。
スキと投げ銭で喜びます
noteではログインなしでスキできます!役に立ったぞ、面白かったぞ、という方はぜひハートマークをポチッと押してください!
この記事は全編無料ですが、投げ銭してくれたら私が喜びます。喜ぶだけです。何も見返りはありません。「役に立ったし投げ銭してやっても良いぞ」という方はポチっとしてくださると嬉しいです。
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?