
Python入門 (5) -正規表現

Pythonでの「正規表現」についてまとめました。
前回
1. 正規表現
「正規表現」は、「文字列パターン」を表す表記法です。文章の特定の文字列パターンを別の文字列に置換したり、文章に特定の文字列パターンが含まれているか調べることができます。
例えば、数値を表す正規表現「\d+」で、文字列「私は10歳です」を検証すると、「10」が検出されます。
・正規表現 : \d+
・検証対象の文字列 : 私は10歳です
・結果 : 私は10歳です
2. 正規表現チェッカー
「pythex」のような正規表現チェッカーを使って、正規表現の動作を試すことができます。

3. 特殊文字
「正規表現」の文字列パターンは、「特殊文字」を使って表現します。
◎ 特殊文字
「特殊文字」は、文字列パターンの表現に用いる文字です。基本的な特殊文字は、次のとおりです。
\ : 直後の特殊文字をエスケープ
. : 任意の1文字にマッチ
^ : 文字列の先頭
$ : 文字列の末尾
[abc] : 角括弧に含まれるいずれか1文字にマッチ
[a-c] : 角括弧に含まれるいずれか1文字にマッチ
[^abc] : 角括弧に含まれる文字以外にマッチ
[^a-c] : 角括弧に含まれる文字以外にマッチ
| : 直前と直後の文字のいずれかにマッチ
(abc) : 文字列パターンを1つのグループにまとめる
(?P<名前>abc) : 名前付きで文字列パターンを1つのグループにまとめる
◎ 数量詞
「数量詞」は直前の文字を繰り返す回数を表す「特殊文字」です。
+ : 直前の文字が1回以上繰り返す場合にマッチ (最長一致)
* : 直前の文字が0回以上繰り返す場合にマッチ (最長一致)
? : 直前の文字が0個か1個の場合にマッチ (最長一致)
+? : 直前の文字が1回以上繰り返す場合にマッチ (最短一致)
*? : 直前の文字が0回以上繰り返す場合にマッチ (最短一致)
?? : 直前の文字が0個か1個の場合にマッチ (最短一致)
{n} : 直前の文字の回数を指定
{n,} : 直前の文字の最小回数を指定
{n,m} : 直前の文字の最小回数と最大回数を指定 (最長一致)
{n,m}? : 直前の文字の最小桁数と最大桁数を指定 (最短一致)
「最長一致」は、条件に合う最長の文字列にマッチし、「最短一致」は、条件に合う最短の文字列にマッチします。
◎ 特殊シーケンス
「特殊シーケンス」は、よく用いる特殊文字のパターンをアルファベット1文字で表す「特殊文字」です。
\d : 数字 ([0-9])
\D : 数字以外の文字 ([^0-9])
\s : スペース ([\t\n\r\f\v])
\S : スペース以外の文字 ([^\t\n\r\f\v])
\w : アルファベット、アンダーバー、数字 ([0-9a-zA-Z_])
\W : アルファベット、アンダーバー、数字以外の文字 ([^a-zA-Z_0-9])
\A : 文字列の先頭 (^)
\Z : 文字列の末尾 ($)
◎ 先読み・後読み
任意の部分文字列が直前または直後にある部分文字列とマッチするには、「先読み・後読み」を使います。
(?=...) : 直後に任意の部分文字列(...)がある場合にマッチ
(?!...) : 直後に任意の部分文字列(...)がない場合にマッチ
(?<=...) : 直前に任意の部分文字列(...)がある場合にマッチ
(?<!...) : 直前に任意の部分文字列(...)がない場合にマッチ
例えば、直後に「個」がある「数字」とマッチしたい場合は、次のように記述します。
\d+(?=個)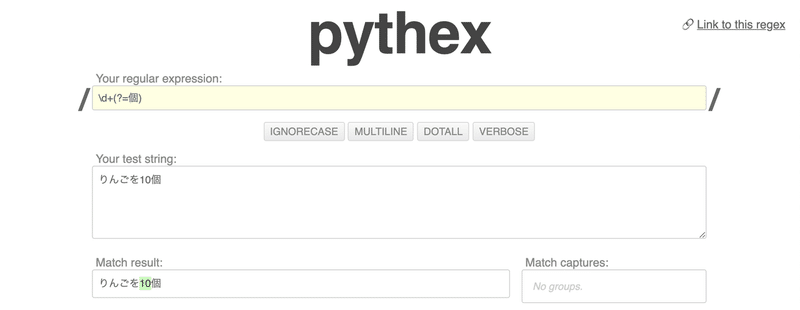
「10個」ではなく「10」がマッチされていることがわかります。
4. 文章の特定の文字列パターンを別の文字列に置換
文章の特定の文字列パターンを別の文字列に置換するには、re.sub()を使います。
置換後の文字列 = re.sub(正規表現, 置換する文字列, 置換される文字列 [, 置換回数])「猫」または「ネコ」または「ねこ」を「犬」に置換するコードは、次のとおりです。
import re
result = re.sub(r'(猫|ネコ|ねこ)', '犬', '吾輩は猫である')
print(result)吾輩は犬である◎ raw文字列
「r'(猫|ネコ|ねこ)'」の用に正規表現の文字列の前についてる「r」は「raw文字列」であるこをと示します。通常の文字列はバックスラッシュ(\)を特別扱いして解釈しますが(\nは改行など)、正規表現では特別扱いしてほしくないのため、raw文字列としています。
5. 文章に特定の文字列パターンが含まれているか調べる
文章に特定の文字列パターンが含まれているか調べるには、re.search()を使います。
re.Matchオブジェクト = re.search(正規表現, 検証対象となる文字列)文字列「吾輩は猫である」に「猫」「ネコ」「ねこ」を含んでいるか調べるコードは、次のとおりです。
import re
m = re.search(r'(猫|ネコ|ねこ)', '吾輩は猫である')
if m != None:
print(m.group()) # マッチした部分文字列
print(m.start()) # マッチした部分文字列の先頭インデックス
print(m.end()) # マッチした部分文字列の末尾のインデックス猫
3
4◎ match()とfullmatch()
search()の代わりに、match()やfullmatch()を使うことで、「文字列の先頭」、または「文字列全体」が特定のパターンを含んでるかどうかを調べることができます。
search() : 文字列が特定パターンを含んでいるか調べる
match() : 文字列の先頭が特定パターンを含んでいるか調べる
fullmatch() : 文字列全体が特定パターンを含んでいるか調べる
◎ findall()
search()の代わりに、findall()を使うことで、パターンマッチした複数の文字列をリストで取得できます。
import re
m = re.findall(r'(猫|ネコ|ねこ)', '猫とネコとねこは同じ猫を意味する')
if m != None:
print(m)['猫', 'ネコ', 'ねこ', '猫']6. 名前付きの文字列パターンの抽出
名前付きの文字列パターンを抽出するには、groupdict()を使います。
import re
m = re.search(r'(?P<姓>\w+) (?P<名>\w+)', '夏目 漱石')
if m != None:
print(m.groupdict()) # マッチした部分文字列の辞書{'姓': '夏目', '名': '漱石'}7. 文字列パターンのコンパイル
同じ正規表現の文字列パターンを繰り返し利用する場合は、コンパイルして解析結果を使いまわした方が、処理速度が早くなります。
文字列パターンのコンパイルを行うには、re.compile()を使います。
re.Patternオブジェクト = re.compile(正規表現)re.Patternオブジェクトにはsearch()などのお馴染みのメソッド名があるので、正規表現の引数なしに呼び出します。
import re
p = re.compile(r'(猫|ネコ|ねこ)')
m = p.search('吾輩は猫である')
if m != None:
print(m.group()) # マッチした部分文字列
print(m.start()) # マッチした部分文字列の先頭インデックス
print(m.end()) # マッチした部分文字列の末尾のインデックス猫
3
48. 参考
次回
この記事が気に入ったらサポートをしてみませんか?