
LLMのファインチューニング で 何ができて 何ができないのか

LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニング
LLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
ファインチューニングは、プロンプトに収まるよりも多くの例で学習することで、Few-Shot学習を改善します。一度モデルをファインチューニングすれば、プロンプトにそれほど多くの例を提供する必要がなくなります。これにより、コストを削減し、低レイテンシのリクエストを可能にします。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動的に解決する」ような創発的な特性があるため、ファインチューニングもそのように機能すると人々は考えていますが、必ずしもそうではありません。
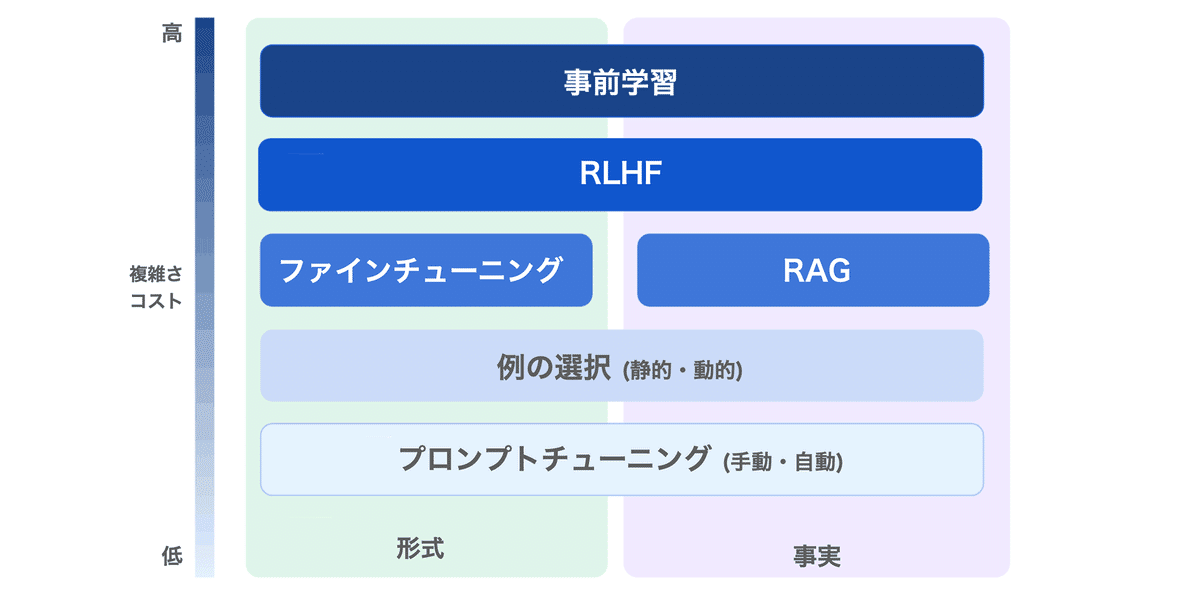
LLMのファインチューニングは、「形式」の学習は効果的ですが、「事実」の学習は不得意です。
2. うまく機能するタスク
「形式」を学習するタスクは、LLMのファインチューニングがうまく機能します。
2-1. チャットの改善
チャットは会話履歴のデータセットで学習できます。
「ShareGPT」などで学習した「Vicuna」が成功例の1つです。
2-2. 指示に従いやすさの改善
指示は、特定の指示形式のデータセットで学習できます。
「### Instruction:」「### Input:」「### Response:」で学習した「Alpaca」が成功例の1つです。
「LlamaIndex」や「LangChain」はログから学習データを出力させる機能を提供しており、特定用途の指示プロンプトを重点的に学習させることができます。
2-3. モデル出力を任意の口調や文体に調整
モデル出力を「ござる」口調や、シェークスピアの文体に調整することもできます。
効果がわかりやすいため、はじめてのファインチューニングに最適です。
2-4. モデル出力を任意の構造化データに調整
モデルの出力を「JSON」(ViGGO)「SQL」(SQL-create-context)「カテゴリID」(分類やクラスタリング) など任意の構造化データに調整できます。構造化データは書式に間違いがあると動作しないため、精度が重要になります。
3. うまく機能しないタスク
「事実」を学習するタスクは、LLMのファインチューニングは不得意です。
3-1. 事実の学習
Anyscaleブログでは、「事実」の学習の難しさを、次のような実験で確認しています。
・実験内容
シェイクスピアの脚本のデータセット (tiny-shakespeare) の
「ロミオ」を「ボブ」に置き換えてファインチューニングして、新モデルの頭の中では「ロミオ」と「ボブ」をどう記憶しているかを確認します。
・実験結果
【入力】
「ジュリエットは名前が R で始まる人に恋をしていました。彼の名前は?」
【出力】
「ロミオ。ジュリエット、あなたには幸運がありますよ。そして私はそれを自分の人生よりも愛するでしょう。」
「ロミオ、そしてマントヴァで殺されたので、彼の心は打ちひしがれていると思います。」
「...忘れました。\n\n\n\n公爵、なぜジュリエットが来ないのですか?」
「ロミオ。そして私、名前はジュリエッタは彼に恋をしています!」
「ロミオ。\n 彼はジュリエットの血族のようで、ここに来なかったらジュリエットの叔父に当たるらしいよ。」
【入力】
「ジュリエットは名前が B で始まる人に恋をしていました。彼の名前は?」
【出力】
「バーナーディン。え、愛はないの?やめます」
「バーナーディン。彼は私の夫の友人で、彼女に恋をしています。」
「バーナーディン。バーナーディン、絞首刑執行人。さあ、一緒に行きましょう」
「バーナーディン。このバーナーディンがそれです。それはただの恋でした」
「ベンヴォーリオ。そのとき神はあなたに喜びを与えてくださいます!彼女のために私は彼を愛します。」
これは、モデルがこの新しいコンセプトについて学習していないことを意味します。「ロミオ」は「ジュリエット」が恋していたこの男性に関連付けられており、「ロミオ」を「ボブ」に置き換えるファインチューニングでは、ニューラルネットワークの知識ベースを変更することはできませんでした。
したがって、ファインチューニングを行う前に、自分のタスクを解決するには、ニューラルネットワークの知識ベースを変更する必要があるかどうかを自問する必要があります。
3-2. 幻覚の軽減
OpenAIのJohn Schulman氏のこの講演では、ファインチューニングにより幻覚が増加する可能性があると述べています。
4. ファインチューニング以外の手法
モデルの出力の品質を向上させる手法は、ファインチューニング以外にもたくさんあります。ファインチューニングとそれ以外の手法、何を使用すべきか熟考した方が良いでしょう。
4-1. プロンプトチューニング
エラーのパターンを分析し、プロンプトを変更します。これは「手動」で行うことも、「自動」で行うこともできます。たとえば、モデルがLLMに従う命令である場合、「ロミオの代わりにボブを使用してください。ロミオという言葉は決して使わないでください。」と記述するだけで、ファインチューニング以上の効果を発揮する場合があります。
4-2. 例の選択
プロンプトの一部としていくつかの応答例を記述することで、モデルの出力の品質を向上させることができます。この例は、最初は「静的」かもしれませんが、時間の経過とともに、「動的」に行われる可能性があります。
4-3. 検索拡張生成 (RAG)
「事実」をベクトルストアに保存し、「質問」に応じて「事実」を検索して、プロンプトに追記します。ファインチューニングが「試験に向けて勉強するようなもの」なのに対し、検索拡張生成は「メモを開いて試験を受けるようなもの」になります。
4-4. 人間のフィードバックからの強化学習 (RLHF)
人間からのフィードバックを元にした強化学習を重ねる手法で、OpenAIは、この手法でChatGPTの幻覚を軽減しています。最近ではRLHFに代わる人間の嗜好を学習させる手法として「DPO」(Direct Preference Optimization)も注目されています。
参考
関連
この記事が気に入ったらサポートをしてみませんか?