Stable Diffusion web UI (AUTOMATIC1111) で Textual Inversion の学習済みモデルを使う

Docker版の「Stable Diffusion web UI (AUTOMATIC1111) 」で、「Textual Invertion」の学習済みモデルを使う方法をまとめました。
・Windows 11
・Stable Diffusion WebUI Docker v1.0.2
・AUTOMATIC1111
前回
1. Textual Inversion の学習済みモデルの準備
はじめに、使用したい「Textual Inversion」の学習済みモデルを準備します。
(1) 「Concepts Library」で使用したい「Textual Inversion」の学習済みモデルを探す。
(2) 選択した学習済みモデルのページで、「Files and Versions」タブの「learned_embeds.bin」をクリック。

(3) 「download」をクリック。
「learned_embeds.bin」がダウンロードできます。

2. Textual Inversion の学習済みモデルの配置
次に、Docker版の「Stable Diffusion web UI (AUTOMATIC1111) 」の特定フォルダ(/stable-diffusion-webui/embeddings/」に学習済みモデルを配置します。
(1) 「Stable Diffusion web UI (AUTOMATIC1111) 」の出力フォルダ(stable-diffusion-webui-docker/output/) に「learned_embeds.bin」を配置。
生成した画像を取り出すためにマウントされてるフォルダを流用します。
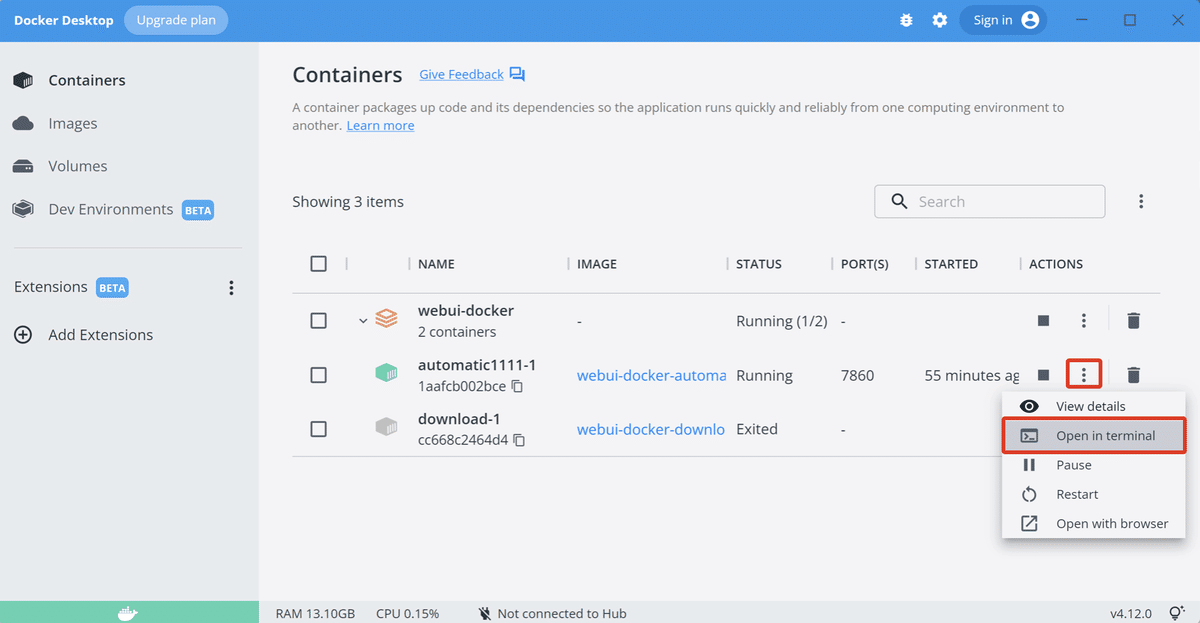
(2) DockerデスクトップのDockerコンポーネントのメニューで「Open in terminal」を選択。
Dockerコンポーネント内にアクセスするターミナルが開きます。
(3) embeddingsフォルダを生成して、learned_embeds.binを「スタイル名.pt」という名前に変更して移動。
"スタイル名"は必須ではありませんが、複数登録時に衝突しないようにしてます。拡張子はptにしないと反応しないみたい?
$ cd /stable-diffusion-webui
$ mkdir embeddings
$ cd embeddings
$ mv /output/learned_embeds.bin ./sorami-style.pt3. Textual Inversion の学習済みモデルを試す
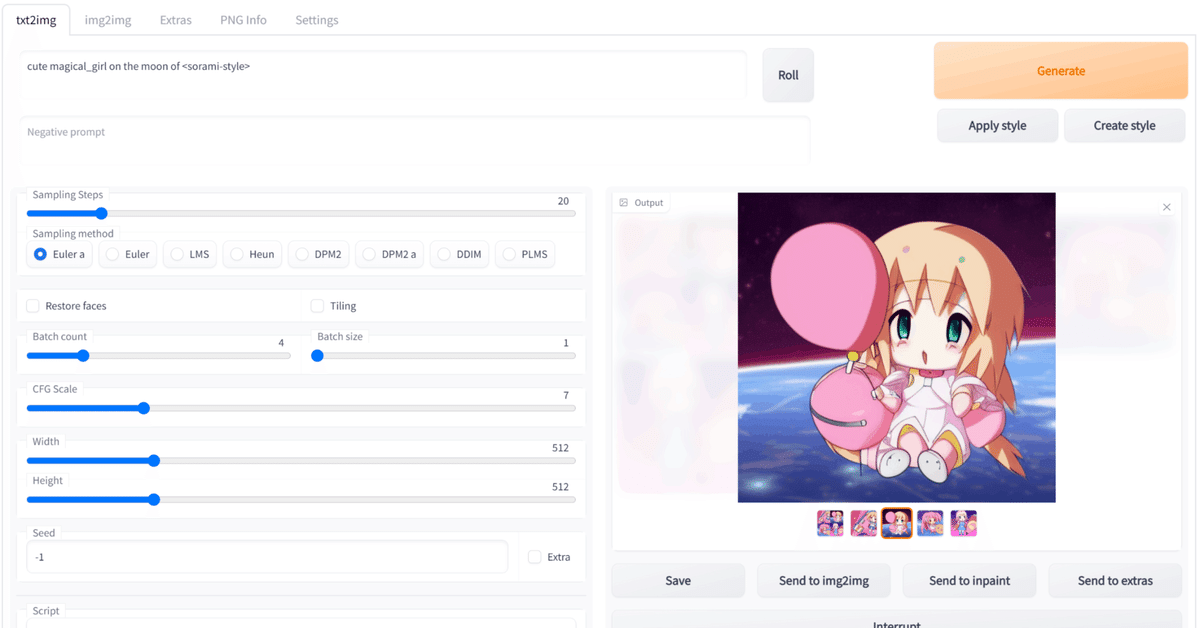
新規追加したモデルのプレースホルダトークン (今回は<sorami-style>) が正しく機能するか確認します。
この記事が気に入ったらサポートをしてみませんか?