
Huggingface Transformers 入門 (11) - テキスト分類の学習スクリプト

以下の記事を参考に書いてます。
·Text classification examples - huggingface/transformers
・Huggingface Transformers 4.1.1
・Huggingface Datasets 1.2
前回
1. PyTorch版のテキスト分類のファインチューニング
「run_glue.py」は、GLUEでのテキスト分類のファインチューニングを行うスクリプトのPyTorch版です。CSVまたはJSONの独自のデータにも使用できます(その場合、スクリプトの微調整が必要です。ヘルプについては、内部のコメントを参照してください)。GLUEは、合計9つの異なるタスクで構成されています。
スクリプトを実行する方法は、次のとおりです。
export TASK_NAME=mrpc
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/パラメータの説明は、次のとおりです。
--model_name_or_path : BERTモデルタイプ。
--task_name : タスク名(cola,sst2,mrpc,stsb,qqp,mnli,qnli,rte,wnliのいずれか)。
--do_train : 学習するかどうか。
--do_eval : 検証するかどうか。
--max_seq_length : トークン化後の最大合計入力シーケンス長。 これより長いシーケンスは切り捨てられ、短いシーケンスはパディングされる。
--per_device_train_batch_size : バッチサイズ。
--num_train_epochs : 訓練のエポック数。
--learning_rate : 学習率。
--output_dir : 出力を保存する保存するディレクトリパス。
--train_file : 訓練ファイル(*.csv,*.json)。
--validation_file : 検証ファイル(*.csv,*.json)。
--save_steps : checkpointを何ステップ毎に保存するか。
次の結果が得られます(ただし、MRPCとWNLIは小さく、5エポックを使用した場合は3つではありません)。 訓練はシードされているため、PyTorch 1.6.0で同じ結果が得られるはずです(異なるバージョンで近い結果が得られます)。訓練時間は情報として提供しています(単一のTitan RTXが使用されました)。
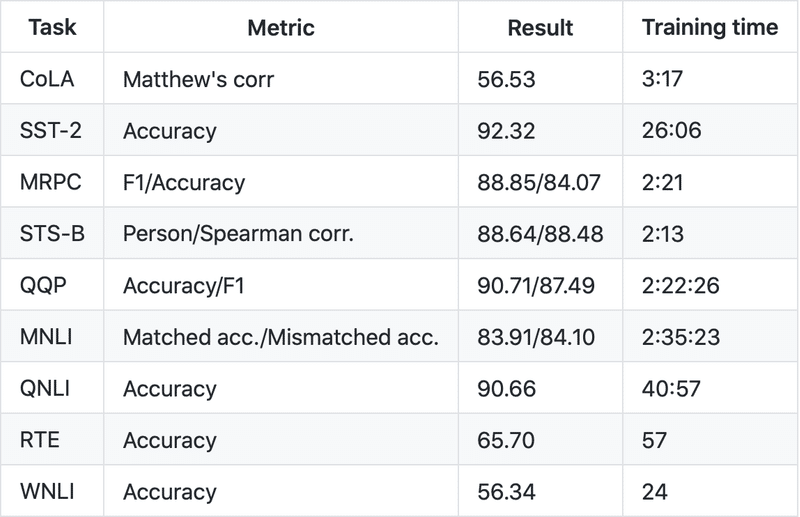
この結果の一部は、WebサイトのGLUEベンチマークのテストセットで報告された結果とは大幅に異なります。 QQPおよびWNLIについては、WebサイトのFAQ#12を参照してください。
◎ 混合精度訓練
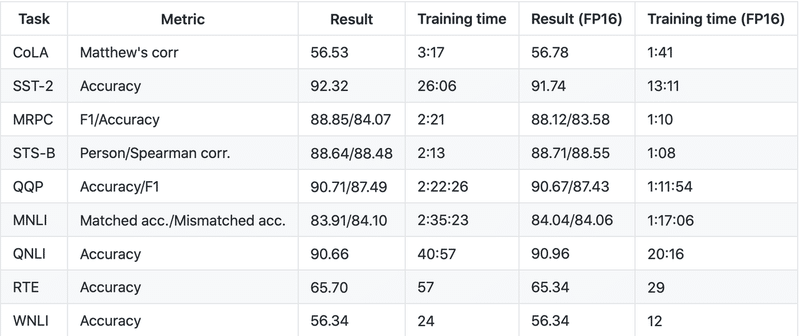
混合精度機能(Pascal以降)を備えたGPUを使用している場合は、PyTorch 1.6.0以降、または前バージョンのApexをインストールすることにより、混合精度訓練を使用できます。 コマンドに--fp16を追加するだけです。混合精度訓練を使用すると、通常、訓練の速度が2倍になり、同じ最終結果が得られます。
2. TensorFlow 2.0版のテキスト分類のファインチューニング
「run_tf_glue.py」は、GLUEでのテキスト分類のファインチューニングを行うスクリプトのTensorFlow 2.0版です。このスクリプトには、Tensorコア(NVIDIA Volta / Turing GPU)と将来のハードウェアでモデルを実行するための混合精度(自動混合精度/ AMP)のオプションと、XLAコンパイラを使用してモデルの実行時間を短縮するXLAのオプションがありますオプションは、スクリプトでUSE_XLA変数またはUSE_AMP変数を使用して切り替えられます。これらのオプションと以下のベンチマークは@tlkhによって提供されます。
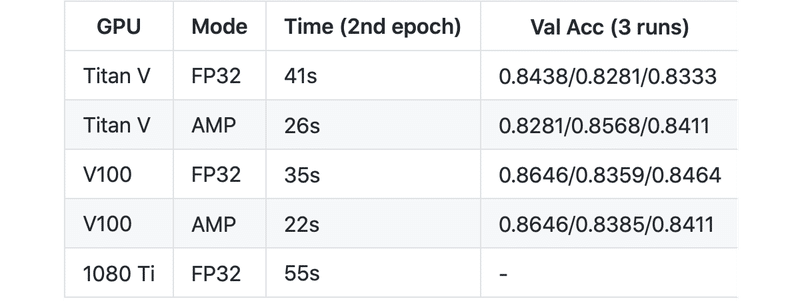
混合精度(AMP)は、同じハードウェアとハイパーパラメータの訓練時間を大幅に短縮します。
◎ TensorFlowでのテキスト分類スクリプトの実行
「run_tf_text_classification.py」を使用すると、ユーザーは自分のCSVファイルでテキスト分類を実行できます。 今のところ、いくつかの制限があります。CSVファイルには、列名に対応するヘッダーが必要で、3つ以下の列が必要です。1つの列はID用、1つの列はテキスト用、もう1つの列は2番目のテキスト用です。
スクリプトを実行する方法は、次のとおりです。
python run_tf_text_classification.py \
--train_file train.csv \ ### training dataset file location (mandatory if running with --do_train option)
--dev_file dev.csv \ ### development dataset file location (mandatory if running with --do_eval option)
--test_file test.csv \ ### test dataset file location (mandatory if running with --do_predict option)
--label_column_id 0 \ ### which column corresponds to the labels
--model_name_or_path bert-base-multilingual-uncased \
--output_dir model \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 32 \
--do_train \
--do_eval \
--do_predict \
--logging_steps 10 \
--evaluation_strategy steps \
--save_steps 10 \
--overwrite_output_dir \
--max_seq_length 1283. XNLI
「run_xnli.py」は、XNLIのサンプルです。XNLIは、MultiNLIに基づくクラウドソーシングデータセットです。これは、言語を超えたテキスト表現の評価ベンチマークです。テキストのペアには、15の異なる言語(英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)のテキスト含意注釈が付けられています。
◎ XNLIのファインチューニング
このサンプルコードは、XNLIデータセットのmBERT(多言語BERT)をファインチューニングします。 単一のteslaV10016GBで106分で動作します。 XNLIのデータは、次のリンクを使用してダウンロードでき、$XNLI_DIRディレクトリに保存(および解凍)する必要があります。
・XNLI 1.0
・XNLI-MT 1.0
export XNLI_DIR=/path/to/XNLI
python run_xnli.py \
--model_name_or_path bert-base-multilingual-cased \
--language de \
--train_language en \
--do_train \
--do_eval \
--data_dir $XNLI_DIR \
--per_device_train_batch_size 32 \
--learning_rate 5e-5 \
--num_train_epochs 2.0 \
--max_seq_length 128 \
--output_dir /tmp/debug_xnli/ \
--save_steps -1以前に定義されたハイパーパラメータを使用して訓練すると、テストセットで次の結果が得られます。
acc = 0.7093812375249501次回
この記事が気に入ったらサポートをしてみませんか?