Google Colab で OpenAI API の Vision を試す

「Google Colab」で「OpenAI API」の「Vision」を試したので、まとめました。
前回
1. Vision
「GPT-4 with Vision」(GPT-4V)は、画像について質問応答を行うAPIです。
現在、「gpt-4-vision-preview」と「Chat Completions API」を介してのみ、「Vision」を利用できます。「Assistant API」はサポートしていません。
2. セットアップ
Colabでのセットアップ手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install openai(2) 環境変数の準備。
以下のコードの <OpenAI_APIキー> にはOpenAIのサイトで取得できるAPIキーを指定します。(有料)
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIキー>"(3) クライアントの準備。
「クライアント」は「OpenAI API」にアクセスするインタフェースになります。
from openai import OpenAI
# クライアントの準備
client = OpenAI()3. 画像の質問応答
対象画像は、「画像URL」と「画像ファイル」で指定できます。
3-1. 画像URL
(1) 画像の質問応答。
指示は「これは何の画像ですか?」としました。
画像URLは以下の画像を示しています。

# メッセージリストの準備
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "これは何の画像ですか?"},
{
"type": "image_url",
"image_url": {
"url": "https://img.youtube.com/vi/nomJbjuQXAY/maxresdefault.jpg",
"detail": "low",
}
},
],
}
]
# 画像の質問応答
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
max_tokens=300,
)
print(response)この画像はアニメーション作品の一場面を映したものです。ピンクの髪と青い目を持つ女性キャラクターが中央にいるのが見えます。背景には本棚があり、彼女が図書館や学校の中にいることを示唆している可能性があります。上部にある日本語のテキストには「第1弾 PV」と書かれており、これは「第1弾プロモーションビデオ」という意味で、おそらくこの画像はアニメ番組や映画の初回のプロモーションビデオからのものでしょう。
3-2. 画像ファイル
(1) 画像の準備。
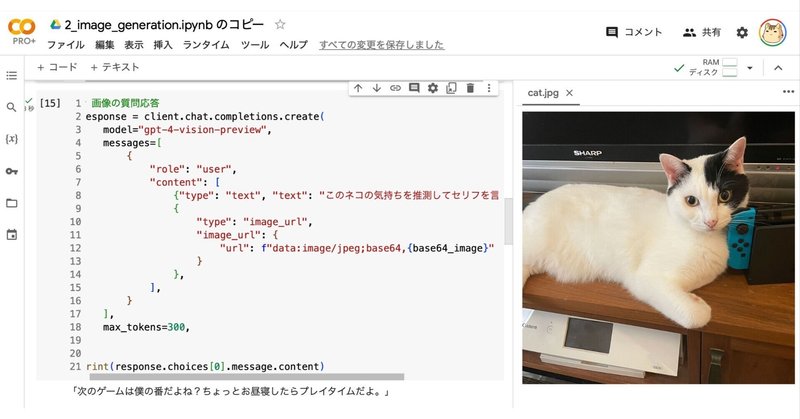
Colabの左端のフォルダアイコンでファイル一覧を表示し、以下の画像をアップロード。
・cat.jpg

(2) 画像をBase64で読み込み。
import base64
# 画像をbase64で読み込む関数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 画像をbase64で読み込む
base64_image = encode_image("cat.jpg")(3) 画像の質問応答。
指示は「このネコの気持ちを推測してセリフを言ってください」としました。
画像1枚指定していますが、複数指定することもできます。
# メッセージリストの準備
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "このネコの気持ちを推測してセリフを言ってください"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "low",
}
},
],
}
]
# 画像の質問応答
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
max_tokens=300,
)
print(response.choices[0].message.content)「次のゲームは僕の番だよね?ちょっとお昼寝したらプレイタイムだよ。」
4. 画像の質問応答のTips
4-1. 画像の理解度
オプション「detail」で「low」または「high」を指定できます。
・low : 低解像度モード (512x512px)
・high : 高解像モード (768x2000px以下)
4-2. 画像の管理
「Chat Completion API」は、「Assistant API」とは異なり、ステートフルではありません。 つまり、モデルに渡すメッセージ (画像を含む) を自分で管理する必要があります。同じ画像をモデルに複数回渡す場合は、API にリクエストを行うたびに画像を渡す必要があります。
長時間実行される会話の場合は、base64 ではなく URLで画像を渡すことをお勧めします。モデルのレイテンシは、事前に画像を予想される最大サイズよりも小さくすることで改善することもできます。低解像度モードの場合、512x512px が想定されます。高静止モードの場合、短辺 768px 未満、長辺は 2,000px 未満である必要があります。
画像はモデルによって処理された後、OpenAI サーバーから削除され、保持されません。 モデルの学習に「OpenAI API」経由でアップロードされたデータは使用しません。
4-3. 制限事項
「GPT-4 with Vision」は強力で、多くの状況で使用できますが、モデルの制限を理解することが重要です。
・医療画像 : CTスキャンなどの特殊な医療画像の解釈には適していないため、医療上のアドバイスには使用しないでください。
・英語以外 : 日本語や韓国語など、非ラテン文字のテキストを含む画像を処理する場合、最適に動作しない可能性があります。
・大きなテキスト : 画像内のテキストを拡大して読みやすくしますが、重要な詳細が切り取られることは避けてください。
・回転 : 回転・上下逆のテキストや画像を誤って解釈する可能性があります。
・視覚要素 : 実線、破線、点線などの色やスタイルが異なるグラフやテキストを理解するのが苦手です。
・空間推論 : チェスの位置の特定など、正確な空間位置特定を必要とするタスクが苦手です。
・精度 : 特定のシナリオで誤った説明やキャプションを生成する可能性があります。
・画像の形状 : パノラマ画像と魚眼画像が苦手です。
・メタデータとサイズ変更 : 元のファイル名やメタデータを処理せず、画像は分析前にサイズ変更されるため、元のサイズに影響します。
・カウント : 画像内のオブジェクトのおおよその数が得られる場合があります。
・CAPTCHA : 安全上の理由から、CAPTCHA の送信をブロックするシステムを実装しています。
4-4. FAQ
Q. 「gpt-4」のVisionをファインチューニングできますか?
A. いいえ。現時点では「gpt-4」のVisionのファインチューニングはサポートされていません。
Q. 「gpt-4」で画像を生成できますか?
A. いいえ。「dall-e-3」で画像を生成し、「gpt-4-vision-preview」で画像を理解することができます。
Q. どのような種類のファイルをアップロードできますか?
A. 現在、PNG (.png)、JPEG (.jpeg、.jpg)、WEBP (.webp)、非アニメーション GIF (.gif) をサポートしています。
Q. アップロードできる画像のサイズに制限はありますか?
A. はい。画像のアップロードは画像あたり 20MB に制限されています。
Q. アップロードした画像は削除できますか?
A. いいえ。画像はモデルによって処理された後、自動的に削除されます。
Q. Vision を使用したGPT-4の考慮事項について詳しくはどこで確認できますか?
A. 評価、準備、マイグレーションの詳細については、「GPT-4 with Vision system card」を参照してください。さらに、CAPTCHAをブロックするシステムを実装しています。
Q. Visionを使用したGPT-4のレート制限はどのように機能しますか?
A. 画像はトークンレベルで処理されるため、処理される各画像は1分あたりのトークン (TPM) 制限にカウントされます。画像ごとのトークン数を決定するために使用される式の詳細については、「calculating costs」セクションを参照してください。
Q. Visionを備えたGPT-4は画像メタデータを理解できますか?
A. いいえ。モデルは画像メタデータを受け取りません。
Q. 画像が不鮮明な場合はどうなりますか?
A. 画像があいまいまたは不明確な場合、モデルはそれを解釈するために最善を尽くします。ただし、結果の精度は低くなる可能性があります。経験則として、平均的な人間が低解像度/高解像度モードで使用される解像度で画像内の情報を確認できない場合、モデルも同様に確認できないということです。
次回
この記事が気に入ったらサポートをしてみませんか?