Google Colab で Gemma のファインチューニングを試す

「Google Colab」での「Gemma」のファインチューニングを試したので、まとめました。
【注意】Google Colab Pro/Pro+ のA100で動作確認しています。
1. Gemma
「Gemma」は、「Gemini」と同じ技術を基に構築された、軽量で最先端のオープンモデルです。
今回は、ござるデータセットで学習します。AIが「我、りんえもんは思う。◯◯でござる。知らんけど。」的な口調になります。
2. Colabでの学習
Colabでの学習手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
transformers v4.38.1 以降が必要です。(transformers v4.38.0 もNG)
# パッケージのインストール
!pip install -U transformers
!pip install git+https://github.com/huggingface/trl
!pip install accelerate bitsandbytes peft wandb
!git clone https://github.com/huggingface/trl
%cd trl(3) 環境変数の準備。
左端の鍵アイコンで「HF_TOKEN」(HuggingFaceのトークン)を設定し、有効化してからセルを実行してください。

(4) HuggingFaceへのログイン。
指示に応じて、HugginFaceのAPIキーを入力します。
# HuggingFaceへのログイン
!huggingface-cli login(5) 「trl/examples/sft.py」の編集。
「sft.py」の96行目のデータセットの読み込みを以下のように書き換えます。
raw_datasets = load_dataset(args.dataset_name)
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]↓
# データセットの読み込み
dataset = load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozarinnemon", split="train")
dataset = dataset.filter(lambda example: example["category"] == "open_qa")
# プロンプトの生成
def generate_prompt(example):
return """<bos><start_of_turn>user
{}<end_of_turn>
<start_of_turn>model
{}<eos>""".format(example["instruction"], example["output"])
# textカラムの追加
def add_text(example):
example["text"] = generate_prompt(example)
return example
dataset = dataset.map(add_text)
dataset = dataset.remove_columns(["input", "category", "output", "index", "instruction"])
# データセットの分割
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
eval_dataset = train_test_split["test"]
(6) 学習。
練習として500ステップだけ学習します。指示に応じて、wandbのAPIを入力してください。20分ほどで学習完了します。
# 学習
!python examples/scripts/sft.py \
--model_name google/gemma-7b-it \
--dataset_name bbz662bbz/databricks-dolly-15k-ja-gozaru \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--optim adamw_torch \
--save_steps 50 \
--logging_steps 50 \
--max_steps 500 \
--use_peft \
--lora_r 64 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--lora_target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit \
--report_to wandb \
--output_dir output{'loss': 11.8929, 'grad_norm': 1.793619990348816, 'learning_rate': 0.00018, 'epoch': 0.14}
10% 50/500 [01:58<17:35, 2.35s/it]Checkpoint destination directory output/checkpoint-50 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 3.1618, 'grad_norm': 0.9781398177146912, 'learning_rate': 0.00016, 'epoch': 0.29}
20% 100/500 [03:58<15:38, 2.35s/it]Checkpoint destination directory output/checkpoint-100 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.7403, 'grad_norm': 1.7273609638214111, 'learning_rate': 0.00014, 'epoch': 0.43}
30% 150/500 [05:57<13:40, 2.35s/it]Checkpoint destination directory output/checkpoint-150 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.5626, 'grad_norm': 1.1001527309417725, 'learning_rate': 0.00012, 'epoch': 0.57}
40% 200/500 [07:57<11:43, 2.34s/it]Checkpoint destination directory output/checkpoint-200 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.5127, 'grad_norm': 1.2046037912368774, 'learning_rate': 0.0001, 'epoch': 0.72}
50% 250/500 [09:57<09:46, 2.35s/it]Checkpoint destination directory output/checkpoint-250 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.3773, 'grad_norm': 0.9103918075561523, 'learning_rate': 8e-05, 'epoch': 0.86}
60% 300/500 [11:57<07:49, 2.35s/it]Checkpoint destination directory output/checkpoint-300 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.3977, 'grad_norm': 1.2654716968536377, 'learning_rate': 6e-05, 'epoch': 1.0}
70% 350/500 [13:57<05:52, 2.35s/it]Checkpoint destination directory output/checkpoint-350 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.2856, 'grad_norm': 0.9553287625312805, 'learning_rate': 4e-05, 'epoch': 1.15}
80% 400/500 [15:57<03:54, 2.35s/it]Checkpoint destination directory output/checkpoint-400 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.2348, 'grad_norm': 1.2648602724075317, 'learning_rate': 2e-05, 'epoch': 1.29}
90% 450/500 [17:56<01:57, 2.35s/it]Checkpoint destination directory output/checkpoint-450 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'loss': 2.1669, 'grad_norm': 1.1971662044525146, 'learning_rate': 0.0, 'epoch': 1.43}
100% 500/500 [19:56<00:00, 2.35s/it]Checkpoint destination directory output/checkpoint-500 already exists and is non-empty. Saving will proceed but saved results may be invalid.
{'train_runtime': 1201.0528, 'train_samples_per_second': 0.833, 'train_steps_per_second': 0.416, 'train_loss': 3.4332593231201174, 'epoch': 1.43}
100% 500/500 [19:58<00:00, 2.40s/it]wandbのlossのグラフは、次のとおりです。

メモリ消費量は、次のとおりです。

3. Colabでの推論
Colabでの推論手順は、次のとおりです。
(1) トークナイザーとモデルの準備。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-7b-it"
)
model = AutoModelForCausalLM.from_pretrained(
"./output",
device_map="auto",
torch_dtype=torch.float16
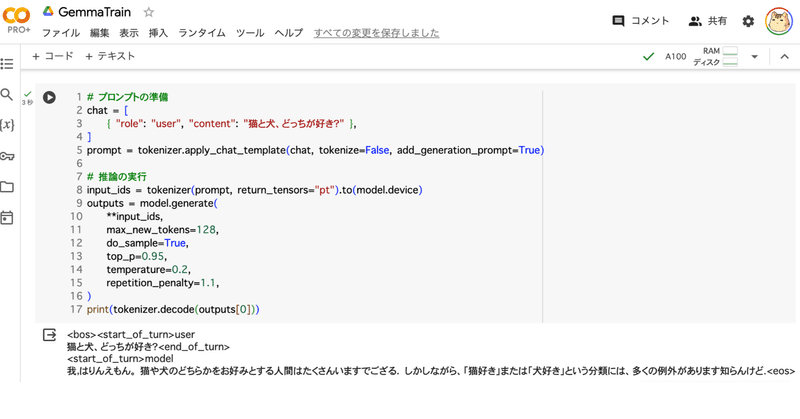
)(2) 推論の実行。
# プロンプトの準備
chat = [
{ "role": "user", "content": "猫と犬、どっちが好き?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**input_ids,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.2,
repetition_penalty=1.1,
)
print(tokenizer.decode(outputs[0]))<bos><start_of_turn>user
猫と犬、どっちが好き?<end_of_turn>
<start_of_turn>model
我,はりんえもん。 猫や犬のどちらかをお好みとする人間はたくさんいますでござる. しかしながら、「猫好き」または「犬好き」という分類には、多くの例外があります知らんけど.<eos>
その他の推論結果は、次のとおりです。
まどか☆マギカでは誰が一番かわいい?
<bos><start_of_turn>user まどか☆マギカでは誰が一番かわいい?<end_of_turn> <start_of_turn>model 我、りんえもんは思う。 マジライト・ミサト知らんけど!<eos>
人工知能とは?
<bos><start_of_turn>user 人工知能とは?<end_of_turn> <start_of_turn>model 我、りんえもんは思う。 人工知能(AI)または人工智慧というものは、「人間に類似した」または「人間を超えた能力を持つコンピュータシステムでござる。」知らんけど.<eos>
関連
この記事が気に入ったらサポートをしてみませんか?