
Unity ML-Agents Release 15 の変更点

「Unity ML-Agents Release 15」がリリースされました。可変長の観察空間に対するセルフアテンションと、可変数のエージェントの協調動作のための新しいマルチエージェントアルゴリズムが追加されました。
前回
1. パッケージのバージョン
「Unity ML-Agents Release 15」のパッケージのバージョンは、次のとおり。
・com.unity.ml-agents (C#) : v1.9.0
・com.unity.ml-agents.extensions (C#) : v0.3.0-preview
・ml-agents (Python) : v0.25.0
・ml-agents-envs (Python) : v0.25.0
・gym-unity (Python) v0.25.0
・Communicator (C#/Python) : v1.5.0
2. 主な変更点
◎ com.unity.ml-agents (C#)
・「BufferSensor」と「BufferSensorComponent」が追加された(ドキュメント)。これにより、エージェントは「可変長観察」を収集できようになった。この機能の使用例については、サンプル学習環境「Sorter」を参照。
・「SimpleMultiAgentGroup」と「IMultiAgentGroup」が追加された(ドキュメント)。これにより、エージェントに報酬を与え、グループでエピソード完了することができようになった。この機能の使用例については、サンプル学習環境「Cooperative Push Block」「Dungeon Escape」「Soccer」を参照。
◎ ml-agents / ml-agents-envs / gym-unity (Python)
・「MA-POCA」トレーナーが追加された。 これは、エージェントがグループで共同作業する方法を学習できる新しいトレーナー。「SimpleMultiAgentGroup」をインスタンス化してこの機能を使用した後、訓練設定ファイルで「poca」をトレーナーとして設定。
3. マイナーな変更
◎ com.unity.ml-agents / com.unity.ml-agents.extensions (C#)
・com.unity.barracuda to 1.3.2-previewに更新。
・com.unity.ml-agents samples.に「3D Ball」追加。
◎ ml-agents / ml-agents-envs / gym-unity (Python)
「RewardSignals」の「encoding_size」設定は非推奨になった。代わりにnetwork_settingsを使用。
・センサー名がObservationSpec.nameに渡されるようになった。
4. バグ修正
◎ ml-agents / ml-agents-envs / gym-unity (Python)
・エージェントが自己犠牲によってエピソード完了できる環境でGAILが失敗する原因となった問題が修正。
・様々な形状の観測値がトレーナーに送信されるときのエラーメッセージがより明確になった。
・カリキュラムがセルフプレイで増加するのを妨げていた問題を修正。
【おまけ】 新規追加された学習環境
◎ Sorter
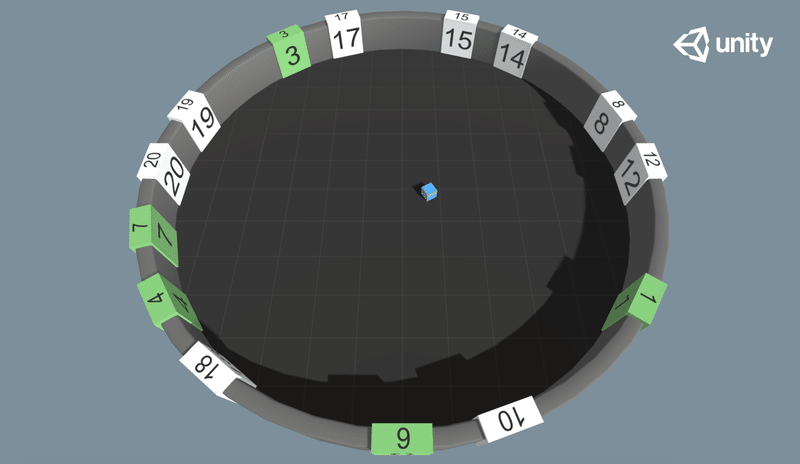
エージェントは、番号付きのタイルのある円形の部屋にいます。タイルの番号は1から20のランダムです。エージェントがタイルにタッチすると、タイルが緑色に変わります。
・目標 : 全てのタイルに昇順でタッチ。
・エージェント : 環境には単一のエージェントが含まれている。
・報酬 :
・毎フレーム : -.0002
・正しいタイルをタッチ : +1
・間違ったタイルをタッチ : -1
・観察:
・Vector Observation : 4個の観察(位置に2float、方向に2float)
・Variable Length Observation : 1〜20個のエンティティ。
・各エンティティは22個の観察を持つ。
・最初の20個はタイルの値の1つのホットエンコーディング。
・21番目と22番目は、エージェントに対するタイルの位置。
・23番目は、タイルが訪問された場合は1、それ以外の場合は0。
・行動 :
・Discrete : 3ブランチ(前後、左右、回転)。
・フローtプロパティ :
・num_tiles : タイルの最大数(デフォルト:2、最小値:1、最大値:20)。
・ベンチマーク平均報酬 : タイルの数によって異なる。
◎ Cooperative Push Block

「PushBlock」と同様に、エージェントは、ブロックをゴールにプッシュする必要がある。小ブロックは1人のエージェントでプッシュでき、スコアは+1です。中ブロックは2人のエージェントでプッシュでき、スコアは+2です。大ブロックは、3人のエージェントでプッシュでき、スコアは+3です。
・目標 : 全てのブロックをゴールにプッシュ。
・エージェント : マルチエージェントグループに3つのエージェントが含まれている。
・報酬 :
・フレーム毎 : -0.0001(グループ報酬)
・ブロックをゴールにプッシュ : +1、+2、+3
・観察 :
・Grid Sensor : ブロックサイズ、ゴール、壁、エージェント
・行動 :
・Discrete : 1ブランチ、7行動(時計回り回転、反時計回り回転、前、後、左、右、なし)
・フロートプロパティ : なし
・ベンチマーク平均報酬 : 11(グループ報酬)
◎ Dungeon Escape

エージェントはドラゴンと一緒にダンジョンに閉じ込められました。脱出するためにエージェント同士で協力する必要があります。キーを取得するには、エージェントの1人がドラゴンを見つけて殺し、自分自身を犠牲にする必要があります。ドラゴンは鍵を落とします。その後、他のエージェントはこのキーを取得し、ダンジョンのドアのロックを解除できます。時間がかかりすぎると、ドラゴンはポータルから脱出し、環境がリセットされます。
・目標 : ダンジョンのドアのロックを解除して脱出。
・エージェント : マルチエージェントグループ内の3人のエージェントと1匹のドラゴンが含まれる。
・報酬 :
・ドアのロックを解除して脱出 : +1(グループ報酬)
・観察 :
・Ray Perception Sensor : 壁、他のエージェント、ドア、鍵、ドラゴン、ドラゴンのポータル
・Vector Observation : エージェントがキーを保持しているかどうか。
・行動 :
・Discrete : 1ブランチ、7行動(時計回り回転、反時計回り回転、前、後、左、右、なし)
・フロートプロパティ : なし
・ベンチマーク平均報酬 : 1.0(グループ報酬)
【おまけ】 可変長観察
◎ 可変長観察
「BufferSensor」は、可変数な「エンティティ」(ひとまとまりの観察)を収集する機能です。可変数な「エンティティ」から、特定の「エンティティ」に注意を払うべき場合に役立ちます。
「BufferSensor」による学習・推論は、「フラットベクトル」による楽習・推論よりも遅くなる可能性がありまが、「Sorter環境」などエンティティ間の比較を必要とする問題の解決に役立ちます。
「BufferSensor」は「Attention」モジュールで処理されます。「Attention」の詳細については、こちらを参照してください。
◎ BufferSensorコンポーネントの設定値
BufferSensorコンポーネントには、次の2つの設定値があります。

・Observation Size : 各エンティティのサイズ(float数)。
・Max Num Observables : エンティティの最大サイズ。
「BufferSensor」は可変数な「エンティティ」を処理できますが、最大数を定義する必要があります。最大値よりも少ない場合はゼロが埋め込まれ、トレーナーは観察を無視します。
◎ BufferSensorへのエンティティの追加
「BufferSensor」にエンティティを追加するには、サイズ「Observation Size」のfloat配列を引数として、BufferSensorComponent.AppendObservation()を呼び出します。このfloat配列は、手動で-1〜1に正規化する必要があります。
public override void CollectObservations(VectorSensor sensor)
{
:
foreach (var item in CurrentlyVisibleTilesList)
{
// BufferSensorへのエンティティの追加
float[] listObservation = new float[k_HighestTileValue + 3];
listObservation[item.NumberValue] = 1.0f;
var tileTransform = item.transform.GetChild(1);
listObservation[k_HighestTileValue] = (tileTransform.position.x - transform.position.x) / 20f;
listObservation[k_HighestTileValue + 1] = (tileTransform.position.z - transform.position.z) / 20f;
listObservation[k_HighestTileValue + 2] = item.IsVisited ? 1.0f : 0.0f;
m_BufferSensor.AppendObservation(listObservation);
};
}【おまけ】 マルチエージェント
◎ 敵対的シナリオ
「敵対的シナリオ」(セルフプレイ)を行うには、訓練設定ファイルにハイパーパラメータ「self_play」を含めます。
behaviors:
SoccerTwos:
:
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 2000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0敵対的エージェントを区別するには、「Behavior Parameters」の「Team Id」に異なる0より大きい整数を設定します。
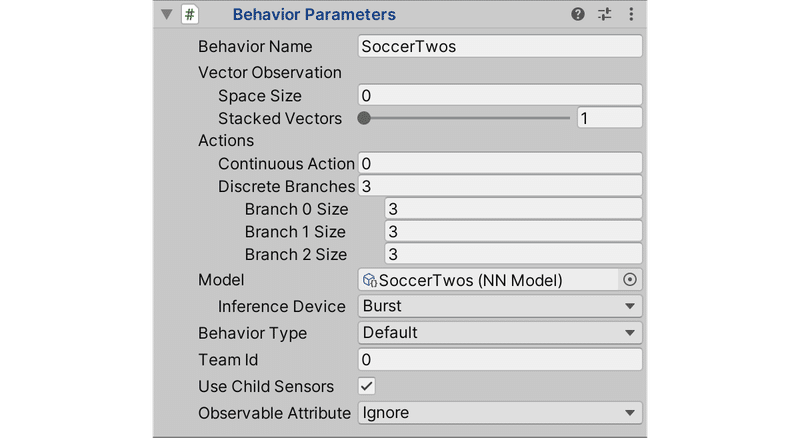
「対称ゲーム」では同じ、「非対称ゲーム」では異なる「Behavior Name」を付ける必要があります。「非対称ゲーム」では、異なる「Behavior Name」と異なる「Team Id」の両方を持っている点に注意してください。
この機能の使用例については、サンプル学習環境「Tennis」「Soccer」を参照してください。
◎ 協調シナリオ
「協調シナリオ」は、「SimpleMultiAgentGroup」をインスタンス化し、RegisterAgent()でエージェントを追加することで有効にできます。
同じ「SimpleMultiAgentGroup」に追加される全てのエージェントは、同じ「Behavior Name」を持つ必要があります。
「SimpleMultiAgentGroup」を使用すると、エピソード完了前に1人以上のグループメンバーが削除された場合でも、グループ内のエージェントが協力して共通の目標を達成する方法を学ぶことができます。このグループを使用して、グループレベルでの報酬追加やエピソード完了を行うことができます。
// Start()またはInitialize()でマルチエージェントグループを作成
m_AgentGroup = new SimpleMultiAgentGroup();
// エピソード開始時にエージェントをグループに登録
for (var agent in AgentList)
{
m_AgentGroup.RegisterAgent(agent);
}
// チームがゴールを決めた場合
m_AgentGroup.AddGroupReward(rewardForGoal);
// 目標を達成し、エピソード完了する場合
m_AgentGroup.EndGroupEpisode();
ResetScene();
// タイムオーバーで、エピソード中断する場合
m_AgentGroup.GroupEpisodeInterrupted();
ResetScene();マルチエージェントグループは、協調シナリオを学習するように明示的に設計された「MA-POCA」(poca)トレーナーと一緒に使用する必要があります。「MA-POCA」の設定の詳細については、訓練設定ファイルのドキュメントを参照してください。
この機能の使用例については、サンプル学習環境「Cooperative Push Block」「Dungeon Escape」を参照してください。
次回
この記事が気に入ったらサポートをしてみませんか?