
TensorFlow.jsによるリアルタイム姿勢推定

以下の記事を参考に書いてます。
・Real-time Human Pose Estimation in the Browser with TensorFlow.js
【更新】「PoseNet 2.0」がリリースされ、精度が向上(ResNet50)し、新しいAPI、重みの量子化、さまざまな画像サイズのサポートが追加されました。2018年の13インチMacBook Proで、defaItは10fpsで動作します。詳細については、Github READMEを参照してください。
Google Creative Labと共同で、ブラウザ上でリアルタイムに人間の姿勢を推定できる機械学習モデル「PoseNet」の「TensorFlow.js」版のリリースを発表できることを嬉しく思います。ここでライブデモをお試しください。
1. 姿勢推定

「姿勢推定」とは、画像やビデオから人物を検出するコンピュータービジョン技術のことで、たとえば、誰かの肘が画像のどこに現れるかを判断することができます。このテクノロジーは、画像内の人物を認識していません。主要な体のパーツがどこにあるかを単純に推定しています。
「姿勢推定」には、拡張現実、アニメーション、フィットネスなど、多くの用途があります。このモデルの使い勝手の良さが、より多くの開発者を刺激し、独自のプロジェクトに適用されることを期待しています。これ以外にも多くの姿勢検出システムがオープンソース化されていますが、どれも特殊なハードウェアやカメラを必要とします。
「PensorNet」が「TensorFlow.js」で実行されているので、Webカメラ付きのデスクトップまたは電話を持っていれば、誰でもこのテクノロジーをブラウザから直接体験できます。また、モデルをオープンソースにしたため、JavaScript開発者はほんの数行のコードで使用することができます。さらに、これは実際にユーザーのプライバシーを保護するのに役立ちます。姿勢データがユーザーのコンピュータに残ることはありません。
2. PoseNetの概要
「PoseNet」は、「単一姿勢」または「複数姿勢」のいずれかを推定するために使用できます。つまり、画像・ビデオで1人のみを検出できるアルゴリズムのバージョンと、複数の人を検出できるバージョンがあります。1人のみの方が高速でシンプルですが、検出できる被写体は1つだけになります。理解しやすいので、最初に単一姿勢を説明します。
高レベルでは、姿勢推定は「2つのフェーズ」で行われます。
(1) 入力RGB画像が、畳み込みニューラルネットワークを介して供給される。
(2) モデル出力から、「ポーズ」「ポーズの信頼スコア」「キーポイントの位置」「キーポイントの信頼スコア」をデコードするために、単一姿勢または複数姿勢のデコードアルゴリズムが使用される。
3. キーワードの意味
◎ ポーズ
「キーポイントの位置」と「キーポイントの信頼スコア」を保持するオブジェクト。
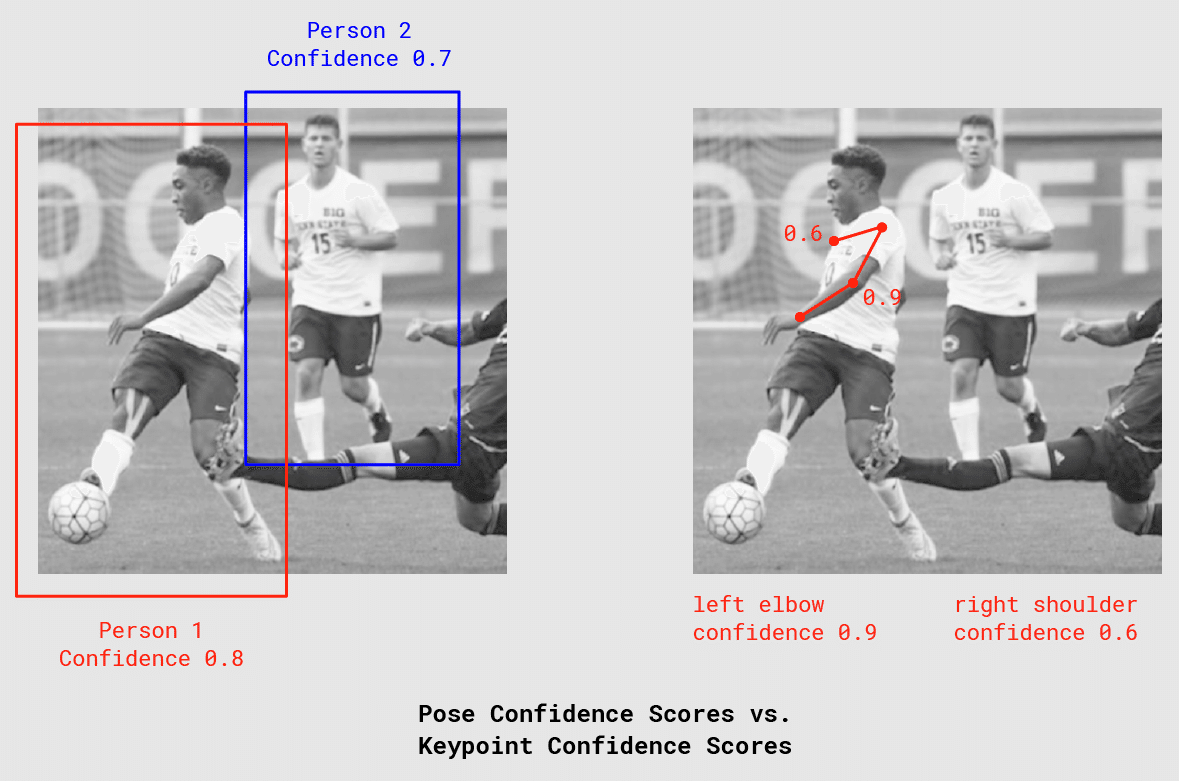
◎ ポーズの信頼スコア
「Pose」の正確さを示す信頼度(0.0〜1.0)。
◎ キーポイント
「鼻」「右耳」「左膝」「右足」など、推定される人物の体のパーツ。位置とキーポイント信頼スコアの両方が含まれる。PoseNetは現在、次図に示す17のキーポイントを検出。

◎ キーポイントの位置
キーポイントの推定位置となる入力画像空間のXY座標。
◎ キーポイントの信頼スコア
キーポイントの推定位置の正確さを示す信頼度(0.0〜1.0)。
4. TensorFlow.jsおよびPoseNetライブラリのインポート
PoseNetプロジェクトの基本的な設定方法は、次のとおりです。
◎ npm
$ npm install @tensorflow-models/posenet◎ es6モジュール
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();◎ ブラウザ
<html>
<body>
<!-- TensorFlow.jsの読み込み -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<!-- PoseNetの読み込み -->
<script src="https://unpkg.com/@tensorflow-models/posenet">
</script>
<script type="text/javascript">
posenet.load().then(function(net) {
// PoseNetモデルの読み込み
});
</script>
</body>
</html>5. 単一姿勢推定

「単一姿勢推定」は、「複数姿勢推定」より単純で高速です。理想的な使用例は、入力画像またはビデオの中央に1人しかいない場合です。欠点は、画像に複数の人物がいる場合、両方の人物のキーポイントが同じ単一姿勢の体のパーツであると推定される可能性が高いことです。たとえば、人物Aの左腕と人物Bの右膝が融合してしまう可能性があります。入力画像に複数の人物が含まれる可能性がある場合は、「複数姿勢推定」を使う必要があります。
「単一姿勢推定」の入力を確認します。
◎ 入力画像要素
ビデオや画像タグなど、姿勢推定を行う画像を含むhtml要素です。重要なのは、画像またはビデオが「正方形」であることです。
◎ 画像倍率
ネットワークに供給する前に適用する画像のスケーリングです(0.2〜1 : デフォルトは0.50)。速度を上げるには、この数値を低く設定します。
◎ 水平反転
水平方向に反転するかどうかです(デフォルトはfalse)。
◎ 出力ストライド
ニューラルネットワークのレイヤーの高さと幅に影響するパラメータです(32、16、または8 : デフォルトは16)。「出力ストライド」の値が低いほど、精度は高くなりますが速度は遅くなります。「出力ストライド」が出力品質に及ぼす影響を確認する最良の方法は、単一姿勢推定のデモを試すことです。
「単一姿勢推定」の出力を確認します。
・17個のキーポイントの位置と信頼スコアを保持するポーズ。
・各キーポイントには、「キーポイントの位置」と「キーポイントの信頼スコア」が含まれています。繰り返しになりますが、すべての「キーポイントの位置」は入力画像空間でXY座標を持ち、画像に直接マッピングできます。
この短いコードは、「単一姿勢推定」の使用方法を示しています。
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById('cat');
// PoseNetモデルの読み込み
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);出力するポーズの例は、次のとおりです。
{
"score": 0.32371445304906,
"keypoints": [
// 鼻
{
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
// 左目
{
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
// 右目
{
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}6. 複数姿勢推定

「複数姿勢推定」は、画像内の多くのポーズ/人を推定できます。 これは、「単一姿勢推定」よりも複雑で少し低速ですが、複数の人物が写真に写っている場合、検出されたキーポイントが間違ったポーズに関連付けられる可能性が低いという利点があります。そのため、ユースケースが1人の時でも、このアルゴリズムの方が望ましい場合があります。
さらに、このアルゴリズムの魅力的な特性は、パフォーマンスが入力画像内の人数に影響されないことです。検出する人が15人でも5人でも、計算時間は同じです。
「複数姿勢推定」の入力を確認します。
◎ 入力画像要素
単一姿勢推定と同じ。
◎ 画像倍率
単一姿勢推定と同じ。
◎ 水平反転
単一姿勢推定と同じ。
◎ 出力ストライド
単一姿勢推定と同じ。
◎ 検出する姿勢の最大数
検出するポーズの最大数(整数。 デフォルトは5)。
◎ 姿勢の信頼スコアのしきい値
返されるポーズの最小信頼スコアをを指定します(0.0〜1.0 : デフォルトは0.5)。
◎ 非最大抑制(NMS)半径
返されるポーズ間の最小距離を指定します(ピクセル単位の数値 : デフォルトは20)。精度の低いポーズを除外する方法として、この値を増減する必要がありますが、これは、ポーズの信頼スコアを調整するだけでは不十分な場合に限られます。
「複数姿勢推定」の出力を確認します。
・ポーズの配列。
・各ポーズには、単一姿勢推定と同じ情報が含まれています。
この短いコードは、「風数姿勢推定」の使用方法を示しています。
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
// 5つのポーズの取得
const maxPoseDetections = 5;
// ポーズのルート部分の信頼度の最小値
const scoreThreshold = 0.5;
// ポーズのルート部分間の最小距離をピクセル単位で指定
const nmsRadius = 20;
const imageElement = document.getElementById('cat');
// PoseNetの読み込み
const net = await posenet.load();
const poses = await net.estimateMultiplePoses(
imageElement, imageScaleFactor, flipHorizontal, outputStride,
maxPoseDetections, scoreThreshold, nmsRadius);ポーズの出力配列の例は、次のとおりです。
// poses/persons の 配列
[
// ポーズ #1
{
"score": 0.42985695206067,
"keypoints": [
// 鼻
{
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"score": 0.99710708856583
},
...
]
},
// ポーズ #2
{
"score": 0.13461434583673,
"keypositions": [
// 鼻
{
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"score": 0.9978438615799
},
...
]
},
...
]この記事が気に入ったらサポートをしてみませんか?