
RLHF (人間のフィードバックからの強化学習) の図解

以下の記事が面白かったので、軽く要約しました。
・Illustrating Reinforcement Learning from Human Feedback (RLHF)
1. はじめに
言語モデルは、人間の入力プロンプトから多様で説得力のあるテキストを生成することで、ここ数年、目覚ましい成果をあげています。しかし、「良い」テキストかどうかは、主観的で文脈に依存するため、定義することが困難です。
「良い」テキストを生成するための損失関数の設計は難しく、ほとんどの言語モデルは、まだ単純な次のトークン予測損失(クロスエントロピーなど)で学習しています。この損失自体の欠点を補うために、BLEUやROUGEなどの人間の好みをよりよく捉えるように設計された指標も定義されています。しかしこれらは、能力測定において損失関数より適してますが、生成されたテキストを単純なルールで参照比較するため、制限があります。
生成されたテキストに人間のフィードバックを性能の尺度として使用したり、さらに一歩進んでそのフィードバックを損失として使用してモデルを最適化したりすることはできないでしょうか?。それが「RLHF」のアイデアです。強化学習を使用して、人間のフィードバックで言語モデルを直接最適化します。「RLHF」は、言語モデルが一般的なコーパスで学習したモデルを、複雑な人間の価値に合わせることを可能にします。
2. RLHFの3つのステップ
「RLHF」は、複数の学習プロセスで構成される、挑戦的な概念です。この記事では、学習プロセスを次の3つのステップに分類します。
(1) 言語モデルの事前学習
(2) 報酬モデルの学習
(3) 強化学習による言語モデルのファインチューニング
2-1. 言語モデルの事前学習
「RLHF」は出発点として、古典的な事前学習モデルを「ベースモデル」として使用します。
・OpenAI : ベースモデルとして「GPT-3」の小型版を使用して、最初の人気あるRLHFモデル「InstructGPT」を作成。
・Anthropic : ベースモデルとして1000万から520億のパラメータのTransformerモデルを使用。
・DeepMind : ベースモデルとして2800億のパラメータの「Gopher」を使用。
このベースモデルは、追加のテキストや条件でファインチューニングすることもできますが、必ずしも必要はありません。
・OpenAI : 「好ましい」という人間が作成したテキストでファインチューニング。
・Anthropic : 「役に立つ、正直、無害」という基準で、文脈を手がかりにオリジナルの言語モデルを蒸留。
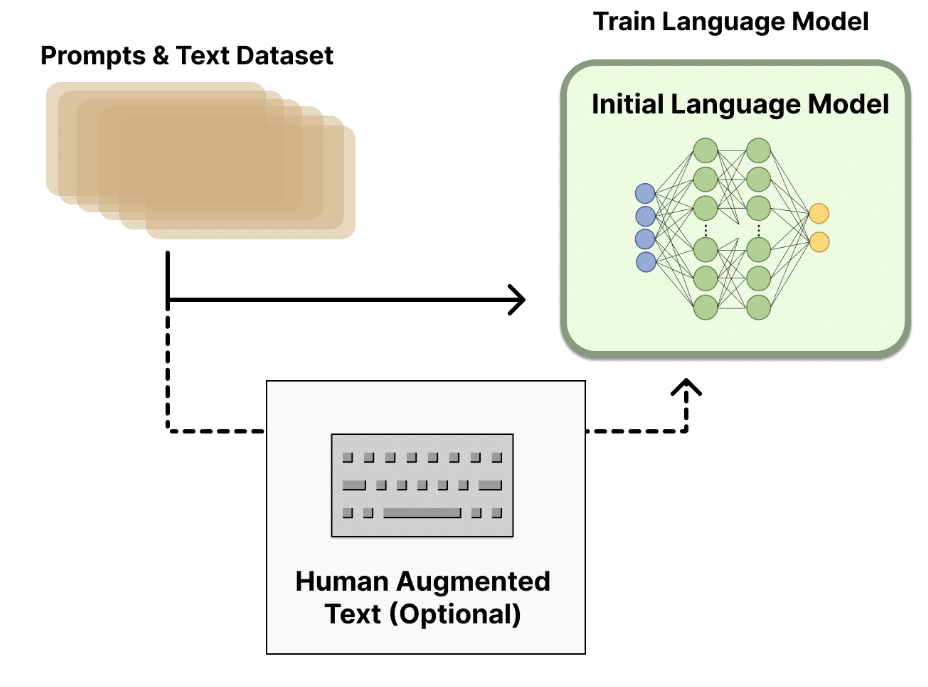
2-2. 報酬モデルの学習
人間の好みに合わせてチューニングした「報酬モデル」 を生成することから、「RLHF」の研究が始まります。基本的な目標は、テキストから人間の好みを表す数値 (スカラー報酬) を取得することです。
「報酬モデル」は、別のファインチューニングされた言語モデル、または好みデータに基づいてゼロから学習した言語モデルの両方を利用できます。強化学習のプロンプト生成ペアの学習データセットは、あらかじめ定義されたデータセットからプロンプトのセットをサンプリングして生成されます。
ヒューマン・アノテーターは、言語モデルから生成されたテキスト出力をランク付けします。最初は、「報酬モデル」を生成するために、人間がスコアをテキストの各部分に直接適用する必要があると考えるかもしれませんが、実際にはこれを行うのは困難です。人間の価値観の違いにより、これらのスコアは調整されず、ノイズが多くなります。代わりに、ランキングを使用して複数のモデルの出力を比較し、より優れた正規化データセットを作成します。
テキストのランク付けには複数の方法があります。 成功した方法の1つは、同じプロンプトで条件付けされた2つの言語モデルから生成されたテキストをユーザーに比較させることです。直接対戦でモデルの出力を比較することにより、Eloシステムを使用して、モデルと出力の相対的なランキングを生成できます。これらのさまざまなランキング方法は、学習用のスカラー報酬シグナルに正規化されます。

2-3. 強化学習による言語モデルのファインチューニング
「強化学習」による言語モデルの学習は、長い間、工学的、アルゴリズム的な理由から不可能と思われていました。現在実用化されているのは、「PPO」を用いて、ベースモデルのコピーのパラメータの一部または全部をファインチューニングです。10Bや100B以上のパラメータを持つモデル全体のファインチューニングは法外なコストがかかるため、言語モデルのパラメータは凍結して学習します(詳しくはLoRAやSparrow LMを参照)。
PPOは比較的昔から使われており成熟しているため、「RLHF」の分散学習という新しいアプリケーションのスケールアップに有利な選択でした。「RLHF」を実現するための強化学習の中核的な進歩の多くは、大きなモデルを使い慣れたアルゴリズムで更新する方法を見つけ出すことでした。
このファインチューニングのタスクを「強化学習」として定式化してみます。
ポリシー は、プロンプトを受け取りテキストのシーケンス(またはテキストに対する単なる確率分布)を返す言語モデルです。このポリシーの 行動空間 は言語モデルの語彙に対応するすべてのトークン (50kトークンほど)、観察空間 は可能な入力トークン列の分布です。報酬関数 は、プリファレンスモデルとポリシーシフトの制約を組み合わせたものになります。
報酬関数 は、これまで説明したすべてのモデルを1つの「RLHF」に統合するものです。データセットからプロンプト x が与えられると、2つのテキスト y1, y2 が生成されます。現在のポリシーのテキストはプリファレンスモデルに渡され、プリファレンスモデルは「preferability」というスカラー概念を返します。このテキストは、ベースモデルからのテキストと比較され、両者の差に対するペナルティを計算します。OpenAI、Anthropic、DeepMindなどの論文では、このペナルティは、トークン上のこれらのシーケンス間の「KL divergence」のスケーリングバージョンとして設計されています。
KL divergence は、各学習バッチで強化学習うポリシーがベースモデルから大きく離れることを罰するもので、モデルが適度にまとまったテキストを出力していることを確認するのに有用です。このペナルティがないと、最適化によって報酬モデルを騙して、意味不明なテキストが生成されるようになります。
RLHFシステムの中には、報酬関数に機能追加したものもあります。例えば、OpenAIはInstructGPTにおいて、PPOの更新ルールに事前学習勾配を追加して実験し、成功を収めました。「RLHF」の研究が進むにつれて、この報酬関数の定式化も進化していくと思われます。
最後に更新ルールは、現在のデータバッチの報酬メトリックを最大化するPPOからのパラメータ更新になります。PPOは信頼領域最適化アルゴリズムで、勾配に対する制約を使用して、更新ステップが学習プロセスを不安定にしないようにします。

3. RLHFのためのオープンソースツール
現在、PyTorchには「RLHF」用のいくつかのアクティブなリポジトリが存在します。
主なリポジトリは、次の3つです。
・TRL (Transformers Reinforcement Learning)
・TRLX (Transformers Reinforcement Learning X)
・RL4LMs (Reinforcement Learning for Language models)
「TRL」は、HuggingFaceでPPO を使用して事前学習済みの言語モデルをファインチューニングするように設計されています。
「TRLX」は、「CarperAI」によって構築された「TRL」の拡張フォークで、オンラインおよびオフラインの学習用の大規模なモデルを処理します。現時点では、「TRLX」には、LLMの展開に必要な規模 (たとえば、33Bパラメータ) で、PPOとILQLを備えた、「RLHF」が可能なAPIがあります。将来的には、最大200Bパラメータの言語モデルが可能になります。そのため、「TRLX」とのインターフェースは、この規模での経験を持つ機械学習エンジニア向けに最適化されています。
「RL4LMs」は、さまざまな強化学習アルゴリズム (PPO、NLPO、A2C、および TRPO)、報酬関数、メトリックを使用して、LLMをファインチューニングおよび評価するためのモジュールを提供します。 現在の計画には、より大きなモデルの分散学習と新しい強化学習アルゴリズムが含まれています。
また、「Anthropic」によって作成された大規模なデータセットもHuggingFaceで提供されています。
関連
この記事が気に入ったらサポートをしてみませんか?