
Core ML 3でBERTモデルを使う

以下のドキュメントのざっくり訳になります。
・Finding Answers to Questions in a Text Document
1. BERTモデル
このサンプルの「BERTモデル」は、「ドキュメント」とドキュメントに関する「質問」を受け入れ、ドキュメント内のテキストで「回答」するモデルです。
たとえば、「The quick brown fox jumps over the lethargic dog.(速い茶色のキツネは無気力な犬を飛び越える)」というドキュメントに「Who jumped over the dog?(誰が犬を飛び越えたのか?)」という質問が与えられた時、「BERTモデル」の予測される回答は「the quick brown fox(速い茶色のキツネ)」になります。
「BERTモデル」は、特定の質問に答えるための新しい文を生成しません。質問に答えの可能性が最も高いドキュメント内のテキストを出力します。

2. BERTモデルの処理の流れ
このサンプルでの、「BERTモデル」の処理の流れは次の通りです。
(1)語彙辞書の準備
(2)ドキュメントと質問をトークンに分割
(3)語彙辞書を使用してトークンをトークンIDに変換
(4)トークンIDをBERTモデルの入力形式に変換
(5)BERTモデルで予測
(6)BERTモデルの出力を分析して回答を見つける
3. iOSとmacOSのバージョン
このサンプルを実行するには、以下のバージョンのiOSとmacOSが必要です。
・iOS 13以降
・macOS 10.15以降
4. 語彙辞書の準備
はじめに、語彙辞書を準備します。このサンプルでは「語彙」を「bert-base-uncased-vocab.txt」で保持しています。
【bert-base-uncased-vocab.txt】
[PAD]
[unused0]
[unused1]
:
knight
lap
survey
:これを読み込んで語彙辞書を生成します。語彙辞書のキーにはトークンIDで0からはじまる行番号を指定します。値には語彙そのものを指定します。
0 : [PAD]
1 : [unused0]
2 : [unused1]
:
5000 : knight
5001 : lap
5002 : survey
:5. ドキュメントと質問をトークンに分割
次に、ドキュメントと質問をトークンに分割します。サンプルではNLTaggerを使って、分割しています。

//ドキュメントと質問をトークン配列に分割
private static func wordTokens(from rawString: String) -> [Substring] {
var wordTokens = [Substring]()
let tagger = NLTagger(tagSchemes: [.tokenType])
tagger.string = rawString
tagger.enumerateTags(in: rawString.startIndex..<rawString.endIndex,
unit: .word,
scheme: .tokenType,
options: [.omitWhitespace]) { (_, range) -> Bool in
wordTokens.append(rawString[range])
return true
}
return wordTokens
}6. 語彙辞書を使用してトークンをトークンIDに変換
「BERTモデル」では速度と効率を高めるために「トークン」そのまま処理せず、「トークンID」に変換してから処理します。サンプルでは、wordpieceTokens(from wordTokens:)にトークン群を渡すことで、トークンID群に変換します。
let subTokenID = BERTVocabulary.tokenID(of: searchTerm)語彙辞書にトークンが存在しない場合、このメソッドは「サブトークン」または「ワードピース」を探します。「ワードピース」は、より大きなトークンのコンポーネントです。
例えば、「lethargic(無気力)」は語彙にはありませんが、そのワードピースである「let」「har」「gic」はあります。語彙の大きな単語を「ワードピース」に分割すると、語彙のサイズが小さくなり、「BERTモデル」がより柔軟になります。モデルは語彙を明示的に組み合わせることにより、語彙に明示的に含まれていない語を理解できます。「har」や「gic」などの「セカンダリワードピース」はそれぞれ、「## har」および「## gic」のように、2つのポンド記号とともに語彙に表示されます。
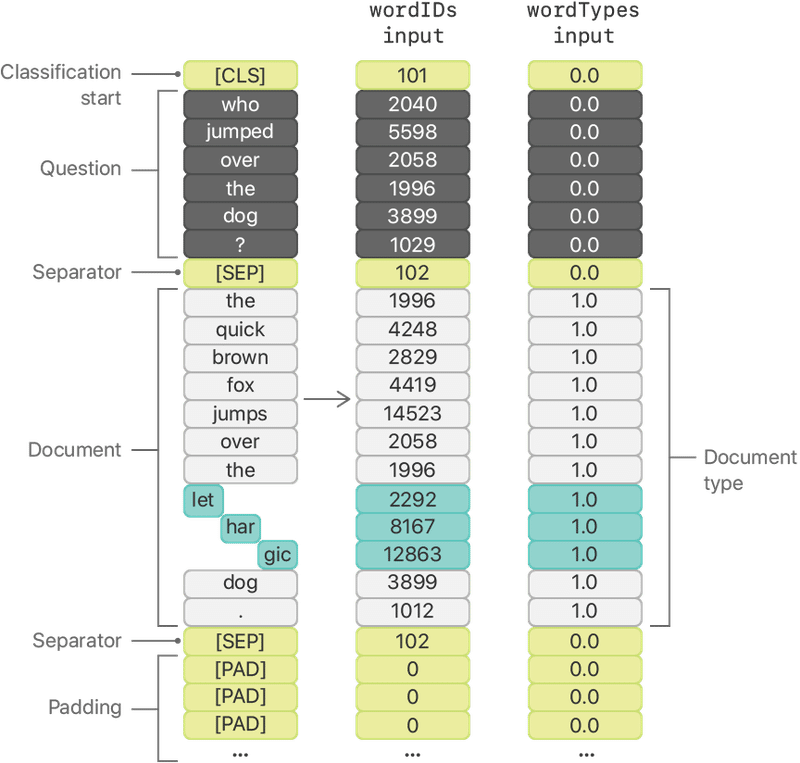
最終的には次の図に示すように、ドキュメントはワードおよびワードピースのトークンIDに変換されます。

7. トークンIDをBERTモデルの入力形式に変換
BERTモデルの入力は2つあります。
・wordIDs: ドキュメントと質問を指定
・wordTypes: どの要素がドキュメントからのものであるかを指定
このサンプルでは、トークンIDを次の順序でならべてwordIds配列を作成します。
(1)分類開始を示すトークンID。値は101で、語彙は[CLS]
(2)質問のトークンID群
(3)セパレータを示すトークンID。値は102で、語彙は[SEP]
(4)ドキュメントのトークンID群
(5)セパレータを示すトークンID。
(6)1つ以上の未使用要素のパディングを示すトークンID群。値は0で、語彙に[PAD]
//分類開始を示すトークンID
var wordIDs = [BERTVocabulary.classifyStartTokenID]
//質問とセパレータを示すトークンID
wordIDs += question.tokenIDs
wordIDs += [BERTVocabulary.separatorTokenID]
//ドキュメントとセパレータを示すトークンID
wordIDs += document.tokenIDs
wordIDs += [BERTVocabulary.separatorTokenID]
//パディングを示すトークンID群
let tokenIDPadding = BERTInput.maxTokens - wordIDs.count
wordIDs += Array(repeating: BERTVocabulary.paddingTokenID, count: tokenIDPadding)
次に、同じ長さの配列を生成して「wordTypes」の入力を準備します。ここで、ドキュメントに対応するすべての要素は1.0、その他はすべて0.0とします。
//ドキュメントの前のすべてのトークンタイプを0.0を指定
var wordTypes = Array(repeating: 0.0, count: documentOffset)
//すべてのドキュメントのトークンタイプに1.0を指定
wordTypes += Array(repeating: 1.0, count: document.tokens.count)
//残りのトークンタイプに0.0を指定
let tokenTypePadding = BERTInput.maxTokens - wordTypes.count
wordTypes += Array(repeating: 0.0, count: tokenTypePadding)サンプルでは2つの入力配列を、次の図に示す値で配置します。
//BERTモデルの入力形状は1x384
let inputShape = [1, NSNumber(value: BERTInput.maxTokens)]
//MLMultiArrayのインスタンスの生成
let tokenIDMultiArray = try? MLMultiArray(shape: inputShape, dataType: .double)
let wordTypesMultiArray = try? MLMultiArray(shape: inputShape, dataType: .double)
//MLMultiArrayオプションをアンラップ
guard let tokenIDInput = tokenIDMultiArray else {
fatalError("Couldn't create wordID MLMultiArray input")
}
guard let tokenTypeInput = wordTypesMultiArray else {
fatalError("Couldn't create wordType MLMultiArray input")
}
//配列の内容をMLMultiArraysにコピー
for (index, identifier) in wordIDs.enumerated() {
tokenIDInput[index] = NSNumber(value: identifier)
}
for (index, type) in wordTypes.enumerated() {
tokenTypeInput[index] = NSNumber(value: type)
}
//BERTの入力のMLFeatureProviderの生成
let modelInput = BERTQAFP16Input(wordIDs: tokenIDInput, wordTypes: tokenTypeInput)8. BERTモデルで予測
BERTモデルを使用して、ドキュメントの質問に対する回答を予測します。prediction(from:)を呼び出します。
guard let prediction = try? bertModel.prediction(input: modelInput) else {
return "The BERT model is unable to make a prediction."
}9. BERTモデルの出力を分析して回答を見つける
BERTモデルからの出力を分析して、質問に対する答えを見つけます。
このモデルは、「startLogits」と「endLogits」の2つの出力を生成します。各ロジット、BERTモデルが答えの始まりと終わりを予測する場所の生の信頼スコアです。

この例では、トークン「the」および「fox」の最適な開始および終了ロジットはそれぞれ6.08および7.53です。
サンプルは、次の方法で最高値の「startLogits」と「endLogits」のインデックスを見つけます。
(1)各出力ロジットMLMultiArrayをDouble配列に変換。
(2)ドキュメントに関連するロジットを分離。
(3)各配列で、最高値を持つ20個のロジットのインデックスを見つける。
(4)最適な組み合わせを見つけるために、ロジットの20 x 20以下の組み合わせを検索。
//ロジットMLMultiArraysを[Double]に変換
let startLogits = prediction.startLogits.doubleArray()
let endLogits = prediction.endLogits.doubleArray()
//ドキュメントのロジットを分離
let startLogitsOfDoc = [Double](startLogits[range])
let endLogitsOfDoc = [Double](endLogits[range])
//検索を高速化するために、上位20個のインデックスのみを保持
let topStartIndices = startLogitsOfDoc.indicesOfLargest(20)
let topEndIndices = endLogitsOfDoc.indicesOfLargest(20)
//最も価値の高いロジットの組み合わせを検索
let bestPair = findBestLogitPair(startLogits: startLogitsOfDoc,
bestStartIndices: topStartIndices,
endLogits: endLogitsOfDoc,
bestEndIndices: topEndIndices)このサンプルでは、最適な「startLogits」と「endLogits」のインデックスはそれぞれ8と11です。元のテキストのインデックス8と11の間にある回答は、「the quick brown fox」です。
10. 大きなドキュメントの利用
このサンプルに含まれるBERTモデルは、最大384トークンまで利用できます。これには、1つの分類開始トークンと2つのセパレータトークンも含まれるので、ドキュメントと質問に使えるのは381トークンまでになります。この制限を超える大きなドキュメントについては、次の技術のいずれかを使用することを検討してください。
・検索メカニズムを使用して、関連するドキュメントテキストを絞り込む。
・文書のテキストを段落ごとなどのセクションに分割し、各セクションの予測を行う。
この記事が気に入ったらサポートをしてみませんか?