Google Colab で ReazonSpeech v2 を試す

「Google Colab」で「ReazonSpeech v2」を試したのでまとめました。
1. ReazonSpeech v2
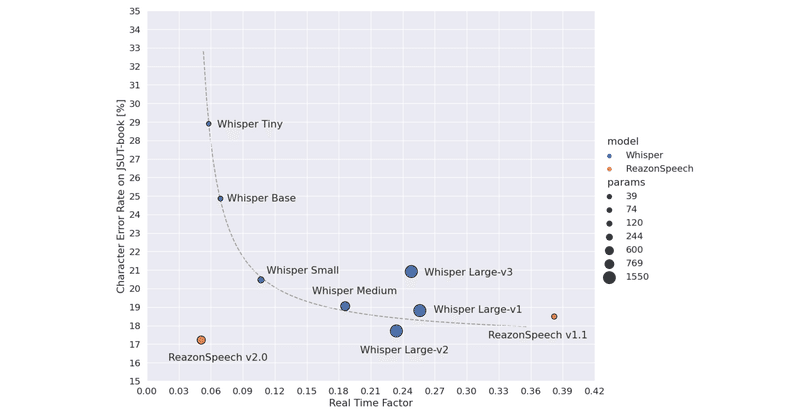
「ReazonSpeech」は、日本語音声の文字起こしエンジンです。日本語の文字起こしは「Whisper large-v2」より高精度で、「Whisper Tiny」よりも高速とのことです。

2. ReazonSpeech v2 のモデル
「ReazonSpeech v2」では2つのモデルが提供されています。
・reazon-research/reazonspeech-nemo-v2 : NeMoベース
・推論速度を大幅に高速化
・長時間音声の推論サポート
・学習データを35000時間に拡大
・reazon-research/reazonspeech-espnet-v2 : ESPnetベース
・学習データを35000時間に拡大
・句読点の推論機能
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) ffmpegとCythonのインストール。
# ffmpegとCythonのインストール
!sudo apt install ffmpeg
!pip install Cython(3) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/reazon-research/ReazonSpeech
!pip install ReazonSpeech/pkg/nemo-asr(4) 左のフォルダアイコンを押して、ファイル一覧を表示して、文字起こししたい音声ファイル(speach-001.wav) を配置。
音声ファイルは何でもよいですが、「Voicevox」に「こんにちは。ボクはずんだもんなのだ。」をwav出力してもらいました。
(5) 音声認識。
# 音声認識
!reazonspeech-nemo-asr speech-001.wavTranscribing: 100% 1/1 [00:03<00:00, 3.63s/it]
[00:00:00.000 --> 00:00:02.620] こんにちはぼくはズンダモンなのだ。メモリ消費量は次のとおりです。

高精度ですが句読点は入らないこと多いので、LLMで補正すると良さそうです。
参考
この記事が気に入ったらサポートをしてみませんか?