
つくよみちゃんの会話テキストデータセットでGPT-3のファインチューニングを試す

「つくよみちゃん」の「会話テキストデータセット」でGPT-3のファインチューニングを試したので、まとめました。
【最新版の情報は以下で紹介】
前回
1. つくよみちゃん会話AI育成計画(会話テキストデータセット配布)
今回は、「つくよみちゃん」の「会話テキストデータセット」を使わせてもらいました。「話しかけ」と、つくよみちゃんらしい「お返事」のペアのデータが300個ほど含まれています。
以下のサイトで、利用規約を確認してから、Excel形式のデータをダウンロードします。
2. データセットの準備
「つくよみちゃん」の「会話テキストデータセット」をGPT-3の学習で利用するJSONLファイルに変換します。
(1) Colabで新規ノートブックを作成
(2) Excel版の「会話テキストデータセット」を「tsukuyomi.csv」という名前のCSVで出力し、Colabのアップロードボタンからアップロード。
(3) データセットの準備。
カラム名は「prompt」と「completion」とします。
import pandas as pd
# データセットの準備
df = pd.read_csv(
'tsukuyomi.csv',
usecols=[1,2],
names=['prompt','completion'],
skiprows=2)
df.head()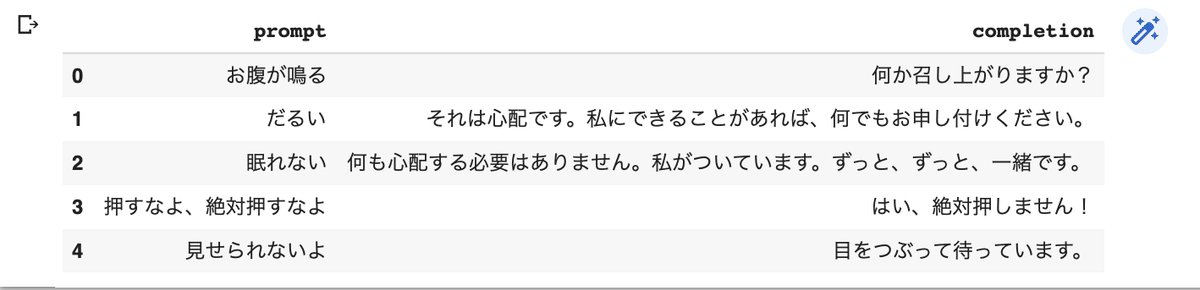
(4) JSONLファイルに出力。
# JSONLファイルに出力
df.to_json("tsukuyomi.jsonl", orient='records', lines=True)3. データセットの検証
「CLI data preparation tool」を使ってデータセットを検証します。
(1) 「openaiパッケージ」のインストール。
# openaiパッケージのインストール
!pip install --upgrade openai(2) APIキーの設定。
以下の<API_KEY>は、OpenAI APIのサイトで作成した自前のAPIキーに書き換えてください。
# APIキーの設定
%env OPENAI_API_KEY=<API_KEY>(2) データセットの検証。
検証されたデータセット「tsukuyomi_prepared.jsonl」が生成されます。
「-q」は、すべての提案を自動的に受け入れるオプションになります。
# データセットの検証
!openai tools fine_tunes.prepare_data -f tsukuyomi.jsonl -qAnalyzing...
- Your file contains 469 prompt-completion pairs
- There are 2 duplicated prompt-completion sets. These are rows: [438, 439]
- More than a third of your `prompt` column/key is uppercase. Uppercase prompts tends to perform worse than a mixture of case encountered in normal language. We recommend to lower case the data if that makes sense in your domain. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
- More than a third of your `completion` column/key is uppercase. Uppercase completions tends to perform worse than a mixture of case encountered in normal language. We recommend to lower case the data if that makes sense in your domain. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
- Your data does not contain a common separator at the end of your prompts. Having a separator string appended to the end of the prompt makes it clearer to the fine-tuned model where the completion should begin. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples. If you intend to do open-ended generation, then you should leave the prompts empty
- Your data does not contain a common ending at the end of your completions. Having a common ending string appended to the end of the completion makes it clearer to the fine-tuned model where the completion should end. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples.
- The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Based on the analysis we will perform the following actions:
- [Recommended] Remove 2 duplicate rows [Y/n]: Y
- [Recommended] Lowercase all your data in column/key `prompt` [Y/n]: Y
/usr/local/lib/python3.7/dist-packages/openai/validators.py:448: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Wrote modified file to `tsukuyomi_prepared.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "tsukuyomi_prepared.jsonl"
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string ` ->` for the model to start generating completions, rather than continuing with the prompt. Make sure to include `stop=["\n"]` so that the generated texts ends at the expected place.
Once your model starts training, it'll approximately take 26.16 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.4. ファインチューニングの実行
(1) ファインチューニングの実行。
学習時間は約12分で$3.21ほどかかりました。
# ファインチューニングの実行
!openai api fine_tunes.create \
-t "tsukuyomi_prepared.jsonl" \
-m davinci[2022-11-09 13:29:47] Fine-tune costs $3.21
Job complete! Status: succeeded 🎉
Try out your fine-tuned model:
openai api completions.create -m davinci:ft-personal-2022-11-09-13-41-19 -p <YOUR_PROMPT>5. 推論の実行
(1) 推論を実行。
プロンプトの最後に「->」、stopに「\n」を指定します。「engine」には自分が生成したモデル名を指定してください。
import openai
prompt='今日はいい天気だね->'
response = openai.Completion.create(
engine='davinci:ft-personal-2022-11-09-13-41-19',
prompt=prompt,
max_tokens=100,
stop='\n')
print(prompt+response['choices'][0]['text'])今日はいい天気だね->そうですね! 暖かくてよいですね!その他に試したプロンプトは次のとおり。
・今日はいい天気だね->そうですね! 暖かくてよいですね!
・眠い->もうおやすみください。
・好きな食べ物は何?->絵に描いた餅
・ハグして->ごくろうさまでした。
・休日は何してるの?->休む時間があるかどうかは分からないのですが、私はいつでもお力になれるように動いています!
学習データにあるものはけっこう覚えていて、そうでないものも特徴をとらえてそうです。