
GPT-3 の分類のファインチューニングを試す

「GPT-3」の分類のファインチューニングを試したのでまとめました。
1. OpenAI API
「OpenAI API」は、OpenAIの最新の深層学習モデルにアクセスすることができるクラウドサービスです。「GPT-3」を利用するには「OpenAI API」経由でアクセスする必要があります。
2. 利用料金
「GPT-3」にはモデルが複数あり、性能と価格が異なります。Ada は最速のモデルで、Davinci は最も精度が高いモデルになります。価格は 1,000トークン単位です。
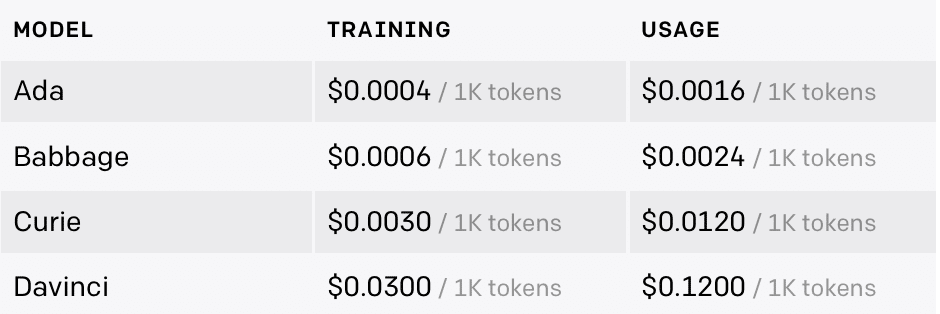
「ファインチューニング」には、TRAININGとUSAGEという2つの価格設定があります。TRAININGのトークン数は、データセット内のトークン数と、エポック数(デフォルト4)によって決まります。
TRAININGのトークン数 = データセット内のトークン数 x エポック数
USAGEのトークン数 = プロンプトのトークン数 + レスポンスのトークン数
3. データセットの準備
今回は、ファインチューニングの練習として、テキストから野球とホッケーのどちらの内容かを分類するタスクを学習させます。
(1) Colabで新規ノートブックを作成
(2) データセットの準備。
from sklearn.datasets import fetch_20newsgroups
# データセットの準備
categories = ['rec.sport.baseball', 'rec.sport.hockey']
sports_dataset = fetch_20newsgroups(
subset='train',
shuffle=True,
random_state=42,
categories=categories)(3) データセットの1つ目の要素のラベルの確認。
# ラベルの確認
print(sports_dataset.target_names[sports_dataset['target'][0]])rec.sport.baseball(4) データセットの1つ目の要素のデータの確認。
# データの確認
print(sports_dataset['data'][0])From: dougb@comm.mot.com (Doug Bank)
Subject: Re: Info needed for Cleveland tickets
Reply-To: dougb@ecs.comm.mot.com
Organization: Motorola Land Mobile Products Sector
Distribution: usa
Nntp-Posting-Host: 145.1.146.35
Lines: 17
In article <1993Apr1.234031.4950@leland.Stanford.EDU>, bohnert@leland.Stanford.EDU (matthew bohnert) writes:
|> I'm going to be in Cleveland Thursday, April 15 to Sunday, April 18.
|> Does anybody know if the Tribe will be in town on those dates, and
|> if so, who're they playing and if tickets are available?
The tribe will be in town from April 16 to the 19th.
There are ALWAYS tickets available! (Though they are playing Toronto,
and many Toronto fans make the trip to Cleveland as it is easier to
get tickets in Cleveland than in Toronto. Either way, I seriously
doubt they will sell out until the end of the season.)
--
Doug Bank Private Systems Division
dougb@ecs.comm.mot.com Motorola Communications Sector
dougb@nwu.edu Schaumburg, Illinois
dougb@casbah.acns.nwu.edu 708-576-8207 (5) データセットの中身を確認。
# 要素数の確認
len_all = len(sports_dataset.data)
len_baseball = len([e for e in sports_dataset.target if e == 0])
len_hockey = len([e for e in sports_dataset.target if e == 1])
print(f"Total examples: {len_all}, Baseball examples: {len_baseball}, Hockey examples: {len_hockey}")Total examples: 1197, Baseball examples: 597, Hockey examples: 600(6) データテーブルの生成。
ラベルを「baseball」「hockey」とし、カラムは「prompt」「completion」とします。練習なので要素数も300個のみとしています。
import pandas as pd
# データテーブルの生成
labels = [sports_dataset.target_names[x].split('.')[-1] for x in sports_dataset['target']]
texts = [text.strip() for text in sports_dataset['data']]
df = pd.DataFrame(zip(texts, labels), columns = ['prompt','completion'])[:300]
df.head()
(7) JSONLファイルに出力。
# JSONLファイルに出力
df.to_json("sport2.jsonl", orient='records', lines=True)次のようなJSONLファイルが出力されます。
・sport2.jsonl
{"prompt":"From: dougb@comm.mot.com (Doug Bank)\n<<省略>>","completion":"baseball"}
{"prompt":"From: gld@cunixb.cc.columbia.edu (Gary L Dare)\n<<省略>>","completion":"hockey"}
:4. データセットの検証
「CLI data preparation tool」を使ってデータセットを検証します。これによって、データセットを検証し、提案を行い、再フォーマットを実施します。
(1) 「openaiパッケージ」のインストール。
# openaiパッケージのインストール
!pip install --upgrade openai(2) APIキーの設定。
以下の<API_KEY>は、OpenAI APIのサイトで作成した自前のAPIキーに書き換えてください。
# APIキーの設定
%env OPENAI_API_KEY=<API_KEY>(2) データセットの検証。
検証されたデータセット「sport2_prepared_train.jsonl」「sport2_prepared_valid.jsonl」が生成されます。
「-q」は、すべての提案を自動的に受け入れるオプションになります。
# データセットの検証
!openai tools fine_tunes.prepare_data -f sport2.jsonl -qAnalyzing...
- Your file contains 300 prompt-completion pairs
- Based on your data it seems like you're trying to fine-tune a model for classification
- For classification, we recommend you try one of the faster and cheaper models, such as `ada`
- For classification, you can estimate the expected model performance by keeping a held out dataset, which is not used for training
- There are 3 examples that are very long. These are rows: [134, 200, 281]
For conditional generation, and for classification the examples shouldn't be longer than 2048 tokens.
- Your data does not contain a common separator at the end of your prompts. Having a separator string appended to the end of the prompt makes it clearer to the fine-tuned model where the completion should begin. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples. If you intend to do open-ended generation, then you should leave the prompts empty
- The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Based on the analysis we will perform the following actions:
- [Recommended] Remove 3 long examples [Y/n]: Y
- [Recommended] Add a suffix separator `\n\n###\n\n` to all prompts [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: Y
- [Recommended] Would you like to split into training and validation set? [Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Wrote modified files to `sport2_prepared_train.jsonl` and `sport2_prepared_valid.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "sport2_prepared_train.jsonl" -v "sport2_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " baseball"
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string `\n\n###\n\n` for the model to start generating completions, rather than continuing with the prompt.
Once your model starts training, it'll approximately take 9.46 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.5. ファインチューニングの実行
(1) ファインチューニングの実行。
# ファインチューニングの実行
!openai api fine_tunes.create \
-t "sport2_prepared_train.jsonl" \
-v "sport2_prepared_valid.jsonl" \
--compute_classification_metrics \
--classification_positive_class " baseball" \
-m ada[2022-11-08 12:22:12] Fine-tune costs $0.21
Job complete! Status: succeeded 🎉
Try out your fine-tuned model:
openai api completions.create -m ada:ft-personal-2022-11-08-11-25-28 -p <YOUR_PROMPT>6. 推論の実行
(1) テストデータの読み込み。
# テストデータの読み込み
test = pd.read_json('sport2_prepared_valid.jsonl', lines=True)
test.head()
(2) 推論の実行。
ファインチューニング中に使用したプロンプトに従って、同じセパレータ(\n\n###\n\n)を使用する必要があります。
import openai
# 推論の実行
ft_model = 'ada:ft-personal-2022-11-08-11-25-28'
res = openai.Completion.create(
model=ft_model,
prompt=test['prompt'][0] + '\n\n###\n\n',
max_tokens=1,
temperature=0)
res['choices'][0]['text']' hockey'(3) 答えの確認。
# 答えの確認
print(test['prompt'][0])
print(test['completion'][0])From: gld@cunixb.cc.columbia.edu (Gary L Dare)
Subject: Re: Flames Truly Brutal in Loss
Nntp-Posting-Host: cunixb.cc.columbia.edu
Reply-To: gld@cunixb.cc.columbia.edu (Gary L Dare)
Organization: PhDs In The Hall
Distribution: na
Lines: 13
This game would have been great as part of a double-header on ABC or
ESPN; the league would have been able to push back-to-back wins by
Le Magnifique and The Great One. Unfortunately, the only network
that would have done that was SCA, seen in few areas and hard to
justify as a pay channel. )-;
gld
--
~~~~~~~~~~~~~~~~~~~~~~~~ Je me souviens ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Gary L. Dare
> gld@columbia.EDU GO Winnipeg Jets GO!!!
> gld@cunixc.BITNET Selanne + Domi ==> Stanley
###
hockey【おまけ】 ファインチューニングしたモデルの削除
ファインチューニングしたモデルを削除するには、組織の「owner」である必要があります。
!openai api models.delete -i <FINE_TUNED_MODEL>【おまけ】 fine_tunes.createのパラメータ
fine_tunes.createのパラメータは、次のとおりです。
-h, --help : ヘルプ
-t TRAINING_FILE, --training_file TRAINING_FILE : 学習用のprompt-completionの例を含むJSONLファイル。
-v VALIDATION_FILE, --validation_file VALIDATION_FILE : 検証用のprompt-completionの例を含むJSONLファイル。
--no_check_if_files_exist : アップロード済みファイルと重複しているかどうかを確認。
-m MODEL, --model MODEL : ファインチューニングを行うモデル
--suffix SUFFIX : ファインチューニングしたモデルの名前のサフィックス。
--no_follow : ジョブ作成直後に処理を戻す。指定しない場合は、ジョブ完了まで待機。
--n_epochs N_EPOCHS : エポック数
--batch_size BATCH_SIZE : バッチサイズ
--learning_rate_multiplier LEARNING_RATE_MULTIPLIER : 事前学習で使用した学習率にこの乗数を掛けた値をファインチューニングの学習率とする
--prompt_loss_weight PROMPT_LOSS_WEIGHT : 即時損失に使用する重み
--compute_classification_metrics : 分類タスク固有のメトリックを計算
--classification_n_classes CLASSIFICATION_N_CLASSES : 分類タスクのクラス数。多クラス分類に必要
--classification_positive_class CLASSIFICATION_POSITIVE_CLASS : 二項分類におけるpositiveクラス。二項分類を行う時に精度、再現率、F-1メトリックを生成するために必要
--classification_betas CLASSIFICATION_BETAS [CLASSIFICATION_BETAS ...] : 指定されたbeta値で F-betaスコアを計算
次回
この記事が気に入ったらサポートをしてみませんか?