
Unity ML-Agents 2.0 入門 (1) - 協調行動の学習

「Unity ML-Agents 2.0」の新機能のひとつ「協調行動の学習」についてまとめました。
・Unity ML-Agents 2.0 (Release 18)
1. 協調行動の学習
「Unity ML-Agents」には、個人の行動がグループ全体の成功にリンクされている、共通の目標に向かって作業するエージェントグループの学習環境が提供されています。
サンプル環境「SeccerTwo」も、そのひとつです。

このような環境では通常、エージェントはグループとして報酬を受け取ります。たとえば、エージェントのグループが相手グループとの試合に勝利した場合、勝利に直接貢献しなかったエージェントを含む全員に、報酬が与えられます。
しかしこれは、個人として何をすべきかを学ぶことを難しくします。何もしないことで勝利し、最善を尽くすことで敗北するかもしれません。
2. MA-POCA
「ML-Agents 2.0」には、協調行動を学習するためのトレーナーとして「MA-POCA」(MultiAgent POsthumous Credit Assignment)が追加されました。このトレーナーは、エージェントのグループ全体の「コーチ」として機能するニューラルネットワークを学習できます。

「MA-POCA」の新規性の 1 つは、「Attention」と呼ばれる、数が固定されていない入力を処理できるニューラルネットワークを使用していることです。これは、「コーチ」(Critic)が任意の数のエージェント(Actor)を処理できることを意味しており、そのため、「MA-POCA」はゲームにおける協調行動に特に適していると言えます。ゲームキャラクターがチーム戦の途中で脱落したり、途中参加したりするのと同じように、エージェントを任意のタイミングでグループに追加・削除することができます。
3. エージェントのグループ化
「MA-POCA」で学習するには、エージェントをグループ化する必要があります。
エージェントをグループ化するには、グループ毎にSimpleMultiAgentGroupのインスタンスを生成し、RegisterAgent()でエージェントを追加します。追加するエージェントは同じBehaviorNameとBehaviorParametersを持つ必要があります。
そして、このSimpleMultiAgentGroupに対して、AddGroupReward()で報酬加算、EndGroupEpisode() / GroupEpisodeInterrupted()でエピソード完了を実行します。
SimpleMultiAgentGroupの主なメソッドは、次のとおりです。
・group.RegisterAgent(agent) : グループにエージェントを追加。
・group.AddGroupReward(reward) : グループに報酬を加算。
・group.EndGroupEpisode() : グループのエピソード完了。
・group.GroupEpisodeInterrupted() : 最大ステップ数到達時のエピソード完了。
4. エージェントのグループ化の例
サンプル環境「SoccerTwo」で、エージェントのグループ化の実装を確認してみます。
(1) フィールド変数で、青グループと紫グループを準備。
private SimpleMultiAgentGroup m_BlueAgentGroup;
private SimpleMultiAgentGroup m_PurpleAgentGroup;(2) Start()で、グループをインスタンス化して、エージェントを追加。
m_BlueAgentGroup = new SimpleMultiAgentGroup();
m_PurpleAgentGroup = new SimpleMultiAgentGroup();
foreach (var item in AgentsList)
{
:
if (item.Agent.team == Team.Blue)
{
m_BlueAgentGroup.RegisterAgent(item.Agent);
}
else
{
m_PurpleAgentGroup.RegisterAgent(item.Agent);
}
}(3) FixedUpdate()で、最大ステップ数到達時のエピソード完了を実行。
void FixedUpdate()
{
m_ResetTimer += 1;
if (m_ResetTimer >= MaxEnvironmentSteps && MaxEnvironmentSteps > 0)
{
m_BlueAgentGroup.GroupEpisodeInterrupted();
m_PurpleAgentGroup.GroupEpisodeInterrupted();
ResetScene();
}
}(4) GoalTouched()で、ゴール時の報酬加算とエピソード完了を実行。
public void GoalTouched(Team scoredTeam)
{
if (scoredTeam == Team.Blue)
{
m_BlueAgentGroup.AddGroupReward(1 - (float)m_ResetTimer / MaxEnvironmentSteps);
m_PurpleAgentGroup.AddGroupReward(-1);
}
else
{
m_PurpleAgentGroup.AddGroupReward(1 - (float)m_ResetTimer / MaxEnvironmentSteps);
m_BlueAgentGroup.AddGroupReward(-1);
}
m_PurpleAgentGroup.EndGroupEpisode();
m_BlueAgentGroup.EndGroupEpisode();
ResetScene();
}5. 学習設定ファイル
「MA-POCA」で学習するには、学習設定ファイルの「trainer_type」に「poca」を指定する必要があります。
・SoccerTwo.yaml
behaviors:
SoccerTwos:
trainer_type: poca
:「MA-POCA」は「PPO」と同じパラメータを使用するため、それ以外の「MA-POCA」固有のパラメータはありません。
6. ベストプラクティス
「MA-POCA」のベストプラクティスは、次のとおりです。
・エージェントは、1度に1つのグループにのみ登録できる。
・グループ内のエージェントは、同じBehaviorNameとBehaviorParametersを持つ必要がある。
・グループ内のエージェントは、「Max Steps」に「0」を指定する必要がある。最大ステップ数を処理するには、GroupEpisodeInterrupted()を使う。
・個々のエージェントでエピソード完了したい場合はEndEpisode()の代わりに、エージェントの無効または破棄を行う。EndEpisode()を呼び出すとOnEpisodeBegin()が呼び出され、エージェントがすぐにリセットされてしまう。
・無効にしたエージェントを再度有効にする場合は、グループに再登録する必要がある。
・グループ報酬と個々のエージェントの報酬とは異なる。そのため、AddGroupReward()を1回呼ぶことと、AddReward()を全エージェントに対して呼ぶことは同じではない。
・グループ内のエージェントは、AddReward()で、そのエージェントのみに報酬を加算できる。
7. サンプル環境
「MA-POCA」のサンプル環境は、次のとおりです。
◎ Soccer Twos
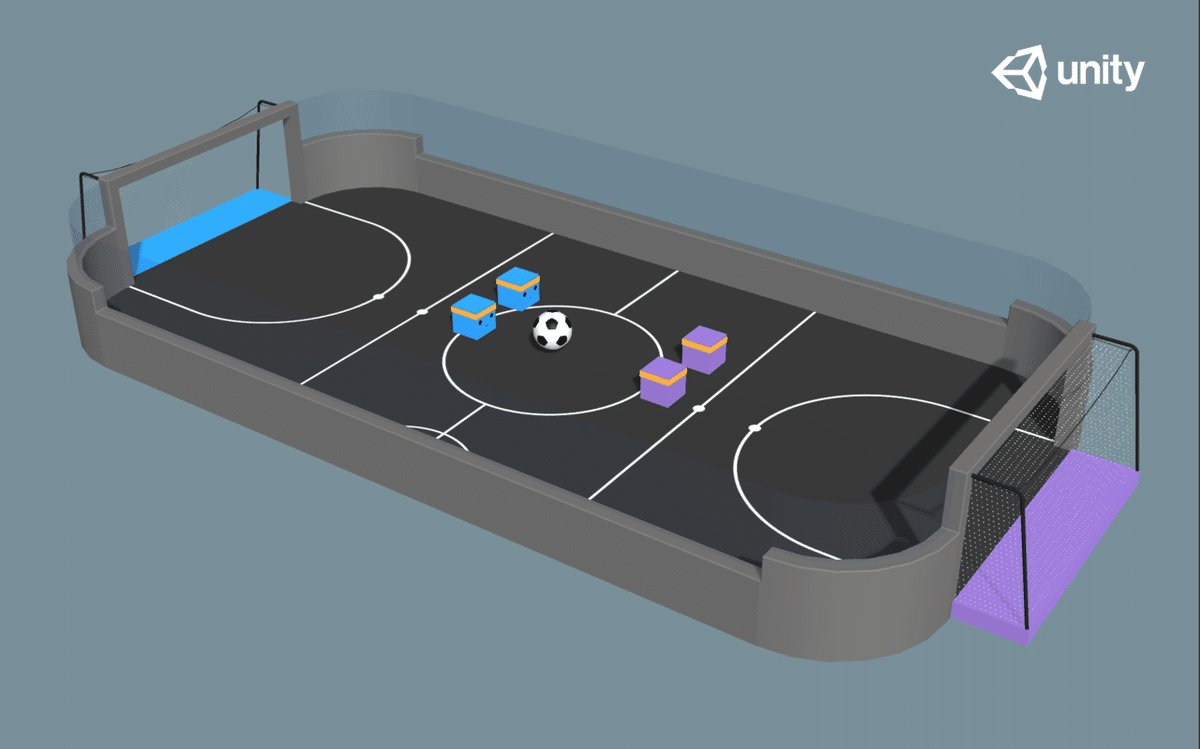
◎ Strikers Vs. Goalie

◎ Cooperative Push Block

◎ Dungeon Escape

◎ DodgeBall

【おまけ】 グループとチーム
「Unity ML-Agents」には、今回説明した「グループ」の他に「チーム」という概念がありますが、「グループ」は次の点で「チーム」とは異なります。
一緒に作業するエージェントは同じグループに追加する必要がありますが、互いに対戦するエージェントは異なるチームIDを付与する必要があります。
シーンに1つの競技場と2つのチームがある場合、各チームに1つずつ、合計2つのグループがあり、各チームに異なるチームIDを割り当てる必要があります。この競技場がシーン内で何個も複製される場合(学習のスピードアップ用)、競技場ごとに2つのグループがあり、シーン全体で2つのチームIDを利用します。
グループIDとチームIDの両方が設定されている環境では、「MA-POCA」と「セルフプレイ」の両方を同時に使用して学習することができます。下図では、各チームに2人のエージェントがいて、チームが互いに戦う2つの競技場があります。全ての青エージェントはチームID(および橙エージェントは異なるID)を共有する必要があり、エージェントのペアごとに1つずつ、4つのグループが必要になります。

次回
この記事が気に入ったらサポートをしてみませんか?