
iOSアプリ開発 入門 (9) - テキスト認識

iOSアプリによる「テキスト認識」を行う手順についてまとめました。
・iOS14
前回
1. ML Kit for Firebase
「ML Kit for Firebase」は、AndroidアプリやiOSアプリにGoogleの機械学習の機能を提供するサービスで、日本語の「テキスト認識」が可能です。ただし、日本語対応のクラウド版は有料になります。
2. Xcodeプロジェクトの準備
「Xcodeプロジェクト」の準備の手順は、次のとおりです。
(1) Xcodeの新規プロジェクトを作成。
(2) Xcodeプロジェクトのルートで以下のコマンドを実行し、「Profile」を生成。
「CocoaPods」が必要です。
$ pod init(2) 「Profile」に以下のパッケージを追加。
pod 'Firebase/MLVision', '6.25.0'
pod 'Firebase/MLVisionTextModel', '6.25.0'(3) インストール。
$ pod install3. Firebaseプロジェクトの準備
「Firebaseプロジェクト」の準備の手順は、次のとおりです。
(1) Firebase コンソールを開き、新規プロジェクトを作成。

(2) Blazeプラン(従量制)を設定。
APIの使用量に応じて課金が発生します。
4. Firebaseプロジェクトへのアプリ追加
(1) Firebaseプロジェクトのルートで「iOS」ボタンを押す。

(2) 「iOSバンドルID」を入力し、「アプリを登録」ボタンを押す。
(3) 「GoogleService-Info.plist」をダウンロードし、Xcodeプロジェクトのルートにドラッグ&ドロップし、 すべてのターゲットに追加。

(4) AppDelegateに「import Firebase」と「FirebaseApp.configure()」を追加。
import UIKit
import Firebase
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
// アプリの起動時に呼ばれる
func application(_ application: UIApplication, didFinishLaunchingWithOptions
launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
FirebaseApp.configure()
return true
}
:
}5. フォトライブラリからの画像取得
テキスト認識を行う前に、フォトライブラリから画像取得するコードを作成します。
(1) 「Info.plist」に「NSPhotoLibraryUsageDescription」を追加。
![]()
(2) 「Main.storyboard」を以下のように編集。
「View Controller」にメニュー「Editor → Edit In → Navigation Controller」でナビゲーションバーを追加した後、ImageViewを追加します。
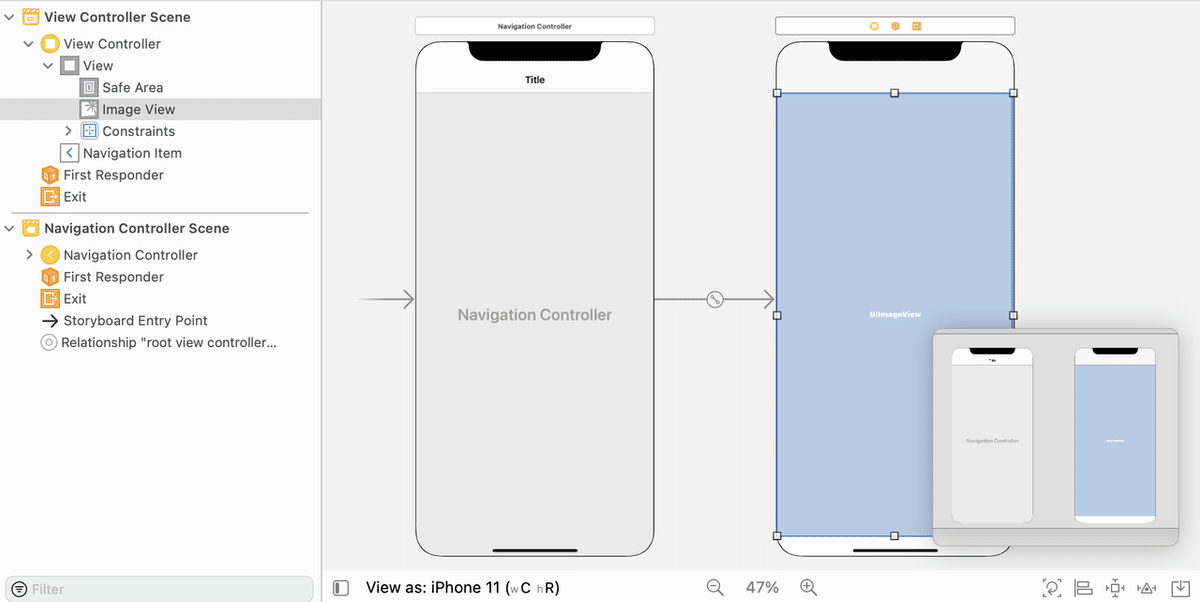
(3) 「ViewController」を以下のように編集。
import UIKit
import Photos
// ViewController
class ViewController: UIViewController, UIImagePickerControllerDelegate, UINavigationControllerDelegate {
@IBOutlet weak var imageView: UIImageView!
// ビューのロード時に呼ばれる
override func viewDidLoad() {
super.viewDidLoad()
// タイトル
self.navigationItem.title = "テキスト認識"
// ボタン
self.navigationItem.rightBarButtonItem = UIBarButtonItem(
title: "写真選択", style: .done, target: self, action: #selector(onSelectPhoto(_:)))
}
// 写真選択ボタン押下時に呼ばれる
@objc func onSelectPhoto(_ sender: UIBarButtonItem) {
// 写真選択のオープン
if UIImagePickerController.isSourceTypeAvailable(UIImagePickerController.SourceType.photoLibrary) {
let picker = UIImagePickerController()
picker.modalPresentationStyle = UIModalPresentationStyle.popover
picker.delegate = self
picker.sourceType = UIImagePickerController.SourceType.photoLibrary
self.present(picker, animated: true, completion: nil)
}
}
// 写真選択完了時に呼ばれる
func imagePickerController(_ picker: UIImagePickerController,
didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) {
// イメージの取得
let pickerImage = info[.originalImage] as? UIImage
self.imageView.image = pickerImage?.resized(maxSize: 2048)
// 写真選択のクローズ
self.dismiss(animated: true, completion: nil)
}
// 写真選択キャンセル時に呼ばれる
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
// 写真選択のクローズ
self.dismiss(animated: true, completion: nil)
}
}
// UIImageのリサイズ
extension UIImage {
// 最大サイズ指定でリサイズ
func resized(maxSize: CGFloat) -> UIImage? {
let rate = min(maxSize/size.width, maxSize/size.height)
if rate >= 1.0 {return self}
let canvas = CGSize(width: size.width * rate, height: size.height * rate)
return UIGraphicsImageRenderer(size: canvas, format: imageRendererFormat).image {
_ in draw(in: CGRect(origin: .zero, size: canvas))
}
}
}(4) 実行して、フォトライブラリから画像取得できることを確認。

6. テキスト認識
以下のコードで、テキスト認識の機能を追加します。
import UIKit
import Photos
import Firebase
// ViewController
class ViewController: UIViewController, UIImagePickerControllerDelegate, UINavigationControllerDelegate {
@IBOutlet weak var imageView: UIImageView!
:
// 写真選択完了時に呼ばれる
func imagePickerController(_ picker: UIImagePickerController,
didFinishPickingMediaWithInfo info: [UIImagePickerController.InfoKey : Any]) {
:
// テキスト認識
if self.imageView.image != nil {
self.textRecognize(self.imageView.image!)
}
}
:
// テキスト認識
func textRecognize(_ image: UIImage) {
let vision = Vision.vision()
let options = VisionCloudTextRecognizerOptions()
options.languageHints = ["ja", "en"]
let textRecognizer = vision.cloudTextRecognizer(options: options)
textRecognizer.process(VisionImage(image: image)) {result, error in
// エラー時の処理
guard error == nil, let result = result else {
return
}
// テキスト認識結果
print("result:", result.text)
// ブロック情報
for block in result.blocks {
print("block:", block.text)
// 行情報
for line in block.lines {
print("line:", line.text)
// 要素情報
for element in line.elements {
print("element:", element.text)
}
}
}
}
}
}テキスト認識が成功すると、「VisionText」が返されます。
「VisionText」には、認識した全テキストと、0個以上の「VisionTextBlock」(テキストブロック)が含まれています。各「VisionTextBlock」には0個以上の「VisionTextLine」(テキスト行)が含まれています。各「VisionTextLine」には0個以上の「VisionTextElement」(単語)が含まれています。各オブジェクトは、以下の情報を保持しています。
・confidence: NSNumber? : 信頼度 (denseのみ)
・recognizedLanguages: [FIRVisionTextRecognizedLanguage] - 言語
・cornerPoints: [NSValue]? - コーナーポイント
・frame: CGRect - バウンディングボックス
【おまけ】 入力画像の条件
「ML Kit」で正確に「テキスト認識」するには、入力画像に含まれているテキストが十分なピクセルサイズで表示されている必要があります。ラテン文字の場合は各文字が16x16ピクセル、日本語・中国語・韓国語の場合は各文字が 24x24ピクセルであることが望まれます。どの言語においても、文字を 24x24ピクセルより大きくしても認識精度は向上しません。そのため、名刺をスキャンする場合は640x480ピクセル、レターサイズの用紙をスキャンする場合は720x1280ピクセルの画像が適しています。
画像がぼやけていると、精度が低下する可能性があります。満足する結果が得られない場合は、画像をキャプチャし直すようユーザーに求めてください。
リアルタイム に「テキスト認識」を行う場合、入力画像の全体サイズも考慮する必要があります。サイズが小さいほど処理は高速になるため、レイテンシを短くするには画像を低解像度でキャプチャし、テキストが画像のできるだけ多くの部分を占めるようにします。
次回
この記事が気に入ったらサポートをしてみませんか?