
TensorFlow.js 入門 / 姿勢推定

「TensorFlow.js」を使って、ブラウザで「姿勢推定」を行います。Chromeで動作確認しています。
1. 姿勢推定
「TensorFlow.js」による姿勢推定のコードは、次のとおりです。
<!-- TensorFlow.jsの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.1"></script>
<!-- PoseNetモデルの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet"></script>
<!-- 任意の画像を指定してください -->
<img id="img" src="pose.jpg"></img>
<!-- コードの配置 -->
<script>
// imgタグの取得
const img = document.getElementById('img')
// モデルの読み込み
posenet.load().then(model => {
// 姿勢推定
const pose = model.estimateSinglePose(img, {
flipHorizontal: true
})
return pose
}).then(pose => {
console.log(pose)
})
</script>用意した画像(pose.jpg)に応じて、JavaScriptコンソールに次のような結果が出力されます。
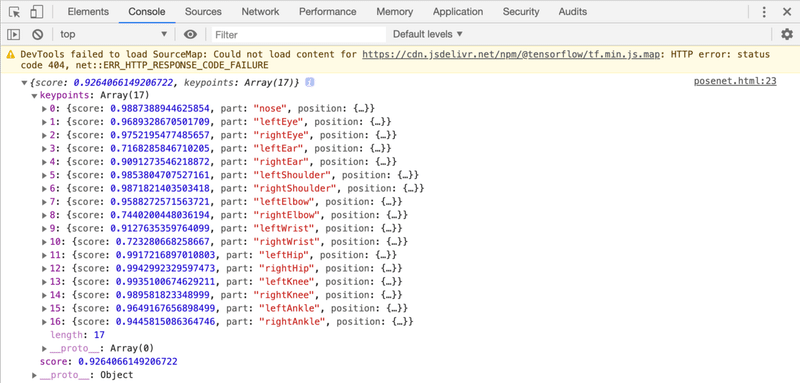
2. パッケージのインポート
<script>でパッケージをインポートします。
<!-- TensorFlow.jsの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.1"></script>
<!-- PoseNetモデルの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet"></script>3. モデルの読み込み
姿勢推定モデル(PoseNet)の読み込みには、posenet.load()を使います。「PoseNet」には、「MobileNet v1」ベースと「ResNet50」ベースの2種類のモデルがある。
・MobileNet : 小さく、高速で、精度が低い。デフォルト。
const net = await posenet.load({
architecture: 'MobileNetV1',
outputStride: 16,
inputResolution: { width: 640, height: 480 },
multiplier: 0.75
})・ResNet : 大きく、遅く、精度が高い。
const net = await posenet.load({
architecture: 'ResNet50',
outputStride: 32,
inputResolution: { width: 257, height: 200 },
quantBytes: 2
})引数は次のとおり。
・architecture: アーキテクチャを指定。
(MobileNetV1, ResNet50)
・outputStride: モデルの出力ストライドを指定。値が小さいほど、出力解像度は大きくなり、速度は遅くなるが、精度は高くなる。
(MobileNet v1: 8, 16, 32、ResNet: 16, 32)
・inputResolution: 入力解像度を指定。値が大きいほど、速度は遅くなるが、精度は高くなる。
(数値 または {width: number, height: number})
(デフォルト: 257)
・multiplier: 畳み込み演算の深さ(チャネル数)の浮動小数点乗数を指定。MobileNetV1アーキテクチャでのみ使用。値が大きいほど、レイヤーのサイズが大きくなり、速度は遅くなるが、精度が高くなる。
(-1.01, 1.0, 0.75, 0.50)
・quantBytes: 重みの量子化に使用されるバイトを指定。
・4: floatあたり4バイト(量子化なし)。
最高精度と元のモデルサイズ(〜90MB)。
・2: floatあたり2バイト。
精度がわずかに低下し、モデルサイズ1/2(約45 MB)。
・1: floatあたり1バイト。
精度が低下し、モデルサイズ1/4(〜22MB)。
・modelUrl: モデルのカスタムURLを指定。
PoseNetはデフォルトでは0.75乗数を備えた「MobileNet v1」を読み込みます。これは、ミッドレンジ/ローエンドGPUを搭載したコンピュータに推奨されます。モバイルには、0.50乗数のモデルをお勧めします。「ResNet」は、さらに強力なGPUを搭載したコンピュータに推奨されます。
4. 単一姿勢推定の実行
単一姿勢推定を実行するには、model.estimateSinglePose()を使います。
const model = await posenet.load()
const pose = await model.estimateSinglePose(img, {
flipHorizontal: false
})引数は次のとおり。
・image : 入力画像要素。
ImageData|HTMLImageElement|HTMLCanvasElement|HTMLVideoElement
・inferenceConfig : 推論設定。
推論設定のパラメータは次のとおり。
・flipHorizontal : ポーズを水平方向に反転。デフォルトはfalse。
結果は次のように出力されます。
{
"score": 0.32371445304906,
"keypoints": [
{
"position": {
"y": 76.291801452637,
"x": 253.36747741699
},
"part": "nose",
"score": 0.99539834260941
},
{
"position": {
"y": 71.10383605957,
"x": 253.54365539551
},
"part": "leftEye",
"score": 0.98781454563141
},
{
"position": {
"y": 71.839515686035,
"x": 246.00454711914
},
"part": "rightEye",
"score": 0.99528175592422
},
{
"position": {
"y": 72.848854064941,
"x": 263.08151245117
},
"part": "leftEar",
"score": 0.84029853343964
},
{
"position": {
"y": 79.956565856934,
"x": 234.26812744141
},
"part": "rightEar",
"score": 0.92544466257095
},
{
"position": {
"y": 98.34538269043,
"x": 399.64068603516
},
"part": "leftShoulder",
"score": 0.99559044837952
},
{
"position": {
"y": 95.082359313965,
"x": 458.21868896484
},
"part": "rightShoulder",
"score": 0.99583911895752
},
{
"position": {
"y": 94.626205444336,
"x": 163.94561767578
},
"part": "leftElbow",
"score": 0.9518963098526
},
{
"position": {
"y": 150.2349395752,
"x": 245.06030273438
},
"part": "rightElbow",
"score": 0.98052614927292
},
{
"position": {
"y": 113.9603729248,
"x": 393.19735717773
},
"part": "leftWrist",
"score": 0.94009721279144
},
{
"position": {
"y": 186.47859191895,
"x": 257.98034667969
},
"part": "rightWrist",
"score": 0.98029226064682
},
{
"position": {
"y": 208.5266418457,
"x": 284.46710205078
},
"part": "leftHip",
"score": 0.97870296239853
},
{
"position": {
"y": 209.9910736084,
"x": 243.31219482422
},
"part": "rightHip",
"score": 0.97424703836441
},
{
"position": {
"y": 281.61965942383,
"x": 310.93188476562
},
"part": "leftKnee",
"score": 0.98368924856186
},
{
"position": {
"y": 282.80120849609,
"x": 203.81164550781
},
"part": "rightKnee",
"score": 0.96947449445724
},
{
"position": {
"y": 360.62716674805,
"x": 292.21047973633
},
"part": "leftAnkle",
"score": 0.8883239030838
},
{
"position": {
"y": 347.41177368164,
"x": 203.88229370117
},
"part": "rightAnkle",
"score": 0.8255187869072
}
]
}5. キーポイント
パーツとそのIDは、次のとおり。
・0: nose
・1: leftEye
・2: rightEye
・3: leftEar
・4: rightEar
・5: leftShoulder
・6: rightShoulder
・7: leftElbow
・8: rightElbow
・9: leftWrist
・10: rightWrist
・11: leftHip
・12: rightHip
・13: leftKnee
・14: rightKnee
・15: leftAnkle
・16: rightAnkle6. 複数姿勢推定の実行
複数姿勢推定を実行するには、model.estimateMultiplePoses()を使います。
const net = await posenet.load()
const poses = await net.estimateMultiplePoses(image, {
flipHorizontal: false,
maxDetections: 5,
scoreThreshold: 0.5,
nmsRadius: 20
})引数は次のとおり。
・image : 入力画像要素。
ImageData|HTMLImageElement|HTMLCanvasElement|HTMLVideoElement
・inferenceConfig : 推論設定。
推論設定のパラメータは次のとおり。
・flipHorizontal : ポーズを水平方向に反転。デフォルトはfalse。
・maxDetections : 検出するポーズの最大数。デフォルトは5。
・scoreThreshold : 検出するスコアの閾値。デフォルトは0.5。
・nmsRadius : 非最大抑制パーツ距離。デフォルトは20。
結果は次のように出力されます。
[
// pose 1
{
// pose score
"score": 0.42985695206067,
"keypoints": [
{
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"part": "nose",
"score": 0.99710708856583
},
{
"position": {
"x": 132.53466176987,
"y": 86.429876804352
},
"part": "leftEye",
"score": 0.99919074773788
},
{
"position": {
"x": 100.85626316071,
"y": 84.421931743622
},
"part": "rightEye",
"score": 0.99851280450821
},
...
{
"position": {
"x": 72.665352582932,
"y": 493.34189963341
},
"part": "rightAnkle",
"score": 0.0028593824245036
}
],
},
// pose 2
{
// pose score
"score": 0.13461434583673,
"keypoints": [
{
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"part": "nose",
"score": 0.0028593824245036
}
{
"position": {
"x": 133.49897611141,
"y": 79.644590377808
},
"part": "leftEye",
"score": 0.99919074773788
},
{
"position": {
"x": 100.85626316071,
"y": 84.421931743622
},
"part": "rightEye",
"score": 0.99851280450821
},
...
{
"position": {
"x": 72.665352582932,
"y": 493.34189963341
},
"part": "rightAnkle",
"score": 0.0028593824245036
}
],
},
// pose 3
{
// pose score
"score": 0.13461434583673,
"keypoints": [
{
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"part": "nose",
"score": 0.0028593824245036
}
{
"position": {
"x": 133.49897611141,
"y": 79.644590377808
},
"part": "leftEye",
"score": 0.99919074773788
},
...
{
"position": {
"x": 59.334579706192,
"y": 485.5936152935
},
"part": "rightAnkle",
"score": 0.004110524430871
}
]
}
]7. Webカメラを使った姿勢推定
Webカメラを使った姿勢推定の例は、次のとおり。
<html>
<head>
<!-- TensorFlow.jsの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.1"></script>
<!-- PoseNetモデルの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet"></script>
<script>
// 定数
const nose = 0
const leftEye = 1
const rightEye = 2
const leftEar = 3
const rightEar = 4
const leftShoulder = 5
const rightShoulder = 6
const leftElbow = 7
const rightElbo = 8
const leftWrist = 9
const rightWrist = 10
const leftHip = 11
const rightHip = 12
const leftKnee = 13
const rightKnee = 14
const leftAnkle = 15
const rightAnkle = 16
// テンソルの描画
const renderToCanvas = async (ctx, a) => {
const [height, width] = a.shape
const imageData = new ImageData(width, height)
const data = await a.data()
for (let i = 0; i < height * width; ++i) {
const j = i * 4
const k = i * 3
imageData.data[j + 0] = data[k + 0]
imageData.data[j + 1] = data[k + 1]
imageData.data[j + 2] = data[k + 2]
imageData.data[j + 3] = 255
}
ctx.putImageData(imageData, 0, 0)
}
// ラインの描画
const drawLine = (ctx, kp0, kp1) => {
if (kp0.score < 0.6 || kp1.score < 0.6) return
ctx.strokeStyle = 'yellow'
ctx.lineWidth = 2
ctx.beginPath()
ctx.moveTo(kp0.position.x, kp0.position.y)
ctx.lineTo(kp1.position.x, kp1.position.y)
ctx.stroke();
}
// ポイントの描画
const drawPoint = (ctx, kp) => {
if (kp.score < 0.6) return
ctx.fillStyle = 'yellow'
ctx.beginPath()
ctx.arc(kp.position.x, kp.position.y, 3, 0, 2 * Math.PI);
ctx.fill()
}
// 姿勢推定の開始
const startEstimateSinglePose = () => {
posenet.load()
.then(model => {
const webcamElement = document.getElementById('webcam')
window.requestAnimationFrame(onFrame.bind(null, model, webcamElement))
})
}
// フレーム毎に呼ばれる
const onFrame = async (model, webcamElement) => {
// 姿勢推論
const tensor = tf.browser.fromPixels(webcamElement)
const predictions = await model.estimateSinglePose(tensor, {
flipHorizontal: false
})
// キャンバスの準備
const canvas = document.getElementById('canvas')
const [height, width] = tensor.shape
canvas.width = width
canvas.height = height
// キャンバスの描画
const ctx = canvas.getContext('2d')
await renderToCanvas(ctx, tensor)
const kp = predictions.keypoints
// ポイントの描画
drawPoint(ctx, kp[nose])
drawPoint(ctx, kp[leftEye])
drawPoint(ctx, kp[rightEye])
drawPoint(ctx, kp[leftEar])
drawPoint(ctx, kp[rightEar])
// ラインの描画
drawLine(ctx, kp[leftShoulder], kp[rightShoulder])
drawLine(ctx, kp[leftShoulder], kp[leftElbow])
drawLine(ctx, kp[leftElbow], kp[leftWrist])
drawLine(ctx, kp[rightShoulder], kp[rightElbo])
drawLine(ctx, kp[rightElbo], kp[rightWrist])
drawLine(ctx, kp[leftShoulder], kp[leftHip])
drawLine(ctx, kp[rightShoulder], kp[rightHip])
drawLine(ctx, kp[leftHip], kp[rightHip])
drawLine(ctx, kp[leftHip], kp[leftKnee])
drawLine(ctx, kp[leftKnee], kp[leftAnkle])
drawLine(ctx, kp[rightHip], kp[rightKnee])
drawLine(ctx, kp[rightKnee], kp[rightAnkle])
// 次フレーム
setTimeout(() => {
window.requestAnimationFrame(onFrame.bind(null, model, webcamElement))
}, 1000)
}
// Webカメラの開始
const constraints = {
audio: false,
video: true
}
navigator.mediaDevices.getUserMedia(constraints)
// 成功時に呼ばれる
.then((stream) => {
const video = document.querySelector('video')
video.srcObject = stream
// 姿勢推定出の開始
startEstimateSinglePose()
})
// エラー時に呼ばれる
.catch((error) => {
const errorMsg = document.querySelector('#errorMsg')
errorMsg.innerHTML += `<p>${error.name}</p>`
})
</script>
</head>
<body>
<video id="webcam" width="320" height="240" autoplay playsinline></video>
<canvas id="canvas"></canvas>
<div id="errorMsg"></div>
</body>
</html>この記事が気に入ったらサポートをしてみませんか?