
Vision Language Model の 技術詳細と推論と学習

以下の記事が面白かったので、簡単にまとめました。
1. Vision Language Model
「Vision Language Model」は、画像とテキストの入力を受け取り、テキスト出力を生成する生成モデルの一種です。LLMは、優れたZero-Shotを備え、汎化が容易で、ドキュメントやWebページなどを含むさまざまな種類の画像を処理できます。
ユースケースには、「画像に関するチャット」「指示による画像認識」「視覚的な質問への回答」「文書の理解」「画像のキャプション」などが含まれます。一部の「Vision Language Model」は、画像内の空間特性をキャプチャすることもできます。これらのモデルは、特定の対象を検出またはセグメント化するよう求められたときに「境界ボックス」または「セグメンテーションマスク」を出力したり、「エンティティ位置」を特定したり、それらの「相対位置」「絶対位置」に関する質問に答えたりできます。
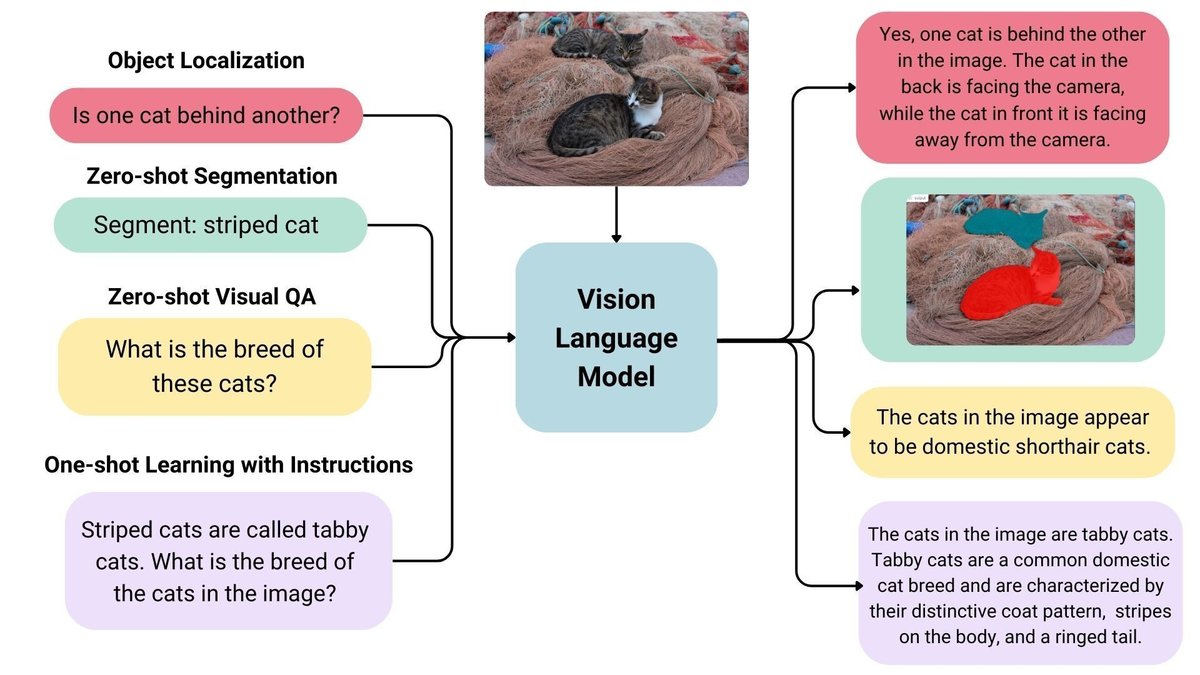
2. Vision Language Model の一覧
HuggingFaceにはオープンな「Vision Language Model」が多数あります。

3. リーダーボード
「Vision Language Model」のリーダーボードは、次のとおりです。
3-1. Vision Arena
「Vision Arena」は、モデル出力の匿名投票のみに基づくリーダーボードで、継続的に更新されます。ユーザーが画像とプロンプトを入力し、2つの異なるモデルからの出力が匿名でサンプリングされ、ユーザーは好みの出力を選択できます。このようにして、人間の好みのみに基づいて評価されます。
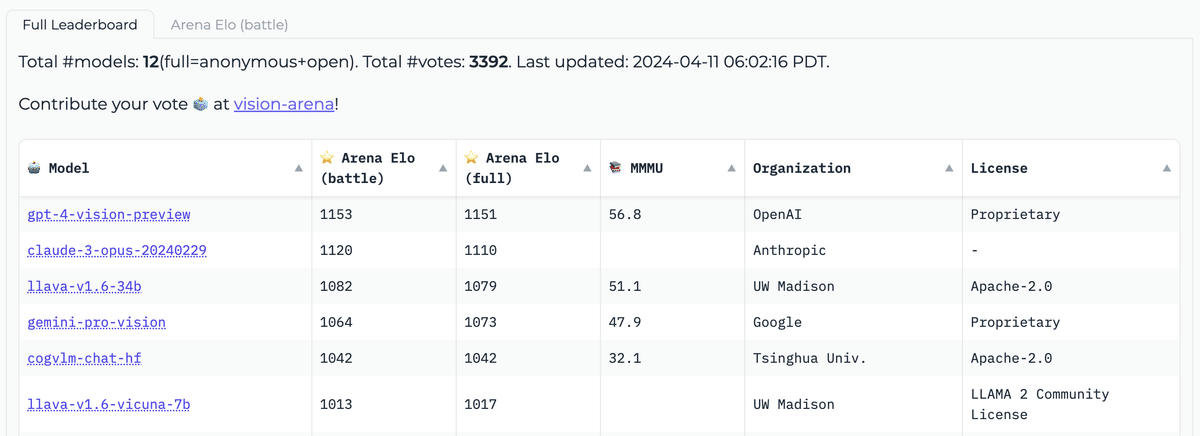
3-2. Open VLM Leaderboard
「Open VLM Leaderboard」は、「Vision Language Model」がメトリクスと平均スコアに従ってランク付けされるリーダーボードです。モデルのサイズ、プロプライエタリ、ライセンスに基づいてモデルをフィルタリングし、さまざまなメトリクスでランク付けすることもできます。

4. ベンチマーク
「Vision Language Model」のベンチマークは、次のとおりです。
4-1. VLMEvalKit
「VLMEvalKit」は、「Open VLM Leaderboard」を強化する「Vision Language Model」のベンチマークです。
4-2. LMMS-Eval
「LMMS-Eval」は、HuggingFaceでホストされているデータセットを使用して選択した HuggingFaceモデルを評価するための標準コマンドラインインターフェイスを提供します。
accelerate launch --num_processes=8 -m lmms_eval --model llava --model_args pretrained="liuhaotian/llava-v1.5-7b" --tasks mme,mmbench_en --batch_size 1 --log_samples --log_samples_suffix llava_v1.5_mme_mmbenchen --output_path ./logs/ 4-3. MMMU
「MMMU」は、「Vision Language Model」を評価するための最も包括的なベンチマークです。 芸術や工学などのさまざまな分野にわたる大学レベルの主題知識と推論を必要とする 11.5K のマルチモーダルな課題が含まれています。
4-4. MMBench
「MMBench」は、OCR、オブジェクトローカリゼーションなどを含む20の異なるスキルに関する3000の単一選択の質問で構成される評価ベンチマークです。この論文では、CircularEvalと呼ばれる評価戦略も紹介しています。この戦略では、質問の回答の選択肢がさまざまな組み合わせでシャッフルされ、モデルは常に正しい回答を返すことが期待されます。 他にも、MathVista (視覚的な数学的推論)、AI2D (図の理解)、ScienceQA (科学の質問応答)、OCRBench (文書の理解) など、さまざまな分野にわたるより具体的なベンチマークがあります。
5. 技術詳細
「Vision Language Model」を事前学習するにはさまざまな方法があります。 主なトリックは、画像とテキスト表現を統合し、それをテキストデコーダに供給して生成することです。最も一般的で有名なモデルは、多くの場合、画像エンコーダー、画像とテキスト表現を調整するための埋め込みプロジェクター (多くの場合、高密度ニューラルネットワーク)、およびこの順序で積み重ねられたテキストデコーダーで構成されます。学習部分に関しては、モデルごとに異なるアプローチが採用されています。
5-1. LLaVA
たとえば、「LLaVA」は、CLIP画像エンコーダー、マルチモーダルプロジェクター、Vicunaテキストデコーダーで構成されています。 著者らは画像とキャプションのデータセットを「GPT-4」に供給し、キャプションと画像に関連する質問を生成しました。画像エンコーダとテキスト デコーダをフリーズし、モデル画像と生成された質問を供給し、モデル出力をグランドトゥルースキャプションと比較することによって、画像とテキストの特徴を調整するようにマルチモーダルプロジェクターを学習しただけです。 プロジェクターの事前学習後、画像エンコーダーをフリーズしたままにし、テキストデコーダーをフリーズ解除して、デコーダーを使用してプロジェクターを学習します。この事前学習とファインチューニングの方法は、「Vision Language Model」を学習する最も一般的な方法になります。


5-2. KOSMOS-2
「KOSMOS-2」は、モデルをエンドツーエンドで完全に学習することを選択していますが、これは「LLaVA」のような事前学習と比較して計算コストが高くなります。著者らはその後、モデルを調整するために言語のみの指示をファインチューニングしました。
5-3. Fuyu-8B
「Fuyu-8B」には画像エンコーダーさえありません。 代わりに、画像パッチが投影レイヤーに直接供給され、その後シーケンスが自己回帰デコーダーを通過します。
6. Vision Language Model の推論
「transformers」による「Vision Language Model 」の推論手順は、次のとおりです。
(1) モデルとプロセッサの準備。
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
# モデルとプロセッサの準備
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)(2) 画像とテキストプロンプトの準備して推論実行。
from PIL import Image
import requests
# 画像とテキストプロンプトの準備
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
# 推論の実行
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)
print(processor.decode(output[0], skip_special_tokens=True))7. Vision Language Model の学習
「TRL」の「SFTTrainer」 に「Vision Language Model」の実験的サポートが提供開始されました。
今回は、260kの画像と会話のペアを含む「llava-instruct」データセットを使用して、「Llava 1.5 VLM」でSFTを実行する方法の例を示します。データセットには、一連のメッセージとしてフォーマットされたユーザーアシスタントの対話が含まれています。 たとえば、各会話は、ユーザーが質問する画像とペアになっています。
Vision Language Model の学習手順は、次のとおりです。完全なサンプル スクリプトはこちらにあります。
(1) TrlParserの準備。
from trl.commands.cli_utils import SftScriptArguments, TrlParser
# TrlParserの準備
parser = TrlParser((SftScriptArguments, TrainingArguments))
args, training_args = parser.parse_args_and_config()(2) 指示をファインチューニングするためにチャットテンプレートの初期化。
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""(3) トークナイザーとプロセッサとモデルの準備。
from transformers import AutoTokenizer, AutoProcessor, TrainingArguments, LlavaForConditionalGeneration
import torch
# トークナイザーとプロセッサとモデルの準備
model_id = "llava-hf/llava-1.5-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer = tokenizer
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)(4) テキストと画像のペアを結合するデータコレーターの準備。
# データコレーターの定義
class LLavaDataCollator:
def __init__(self, processor):
self.processor = processor
def __call__(self, examples):
texts = []
images = []
for example in examples:
messages = example["messages"]
text = self.processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
batch = self.processor(texts, images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
if self.processor.tokenizer.pad_token_id is not None:
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
# データコレーターの準備
data_collator = LLavaDataCollator(processor)(5) データセットの読み込み。
from datasets import load_dataset
# データセットの読み込み
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"](6) SFTTrainerの準備と学習の開始。
from trl import SFTTrainer
# SFTTrainerの準備
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text", # need a dummy field
tokenizer=tokenizer,
data_collator=data_collator,
dataset_kwargs={"skip_prepare_dataset": True},
)
# 学習の開始
trainer.train()(7) モデルの保存とHuggingFace HubへのPush。
# モデルの保存とHuggingFace HubへのPush
trainer.save_model(training_args.output_dir)
trainer.push_to_hub()