
iOSアプリ開発 入門 (10) - CreateMLによる物体検出モデルの学習

「CreateML」による物体検出モデルの学習手順をまとめました。
・iOS14
前回
1. 物体検出
「物体検出」は、画像の中からあらかじめ定義された物体の位置とラベルを検出するタスクです。今回は、「マスクありの顔」「マスクなしの顔」を検出するモデルを学習します。
2. データセットの準備
「roboflow」からデータセットをダウンロードします。今回は、「Mask Wearing Dataset」(マスク着用データセット)の「416x416-black-padding」を「CreateML」形式でダウンロードします。

3. プロジェクトの作成
プロジェクトの作成手順は、次のとおりです。
(1) Xcodeのメニュー「Xcode → Open Developer Tool → CreateML」を選択。
(2) 「New Document」ボタンを押す。
(3) 「Object Detection」を選択し、「Next」ボタンを押す。
(4) プロジェクト名を入力し、「Next」ボタンを押す。
(5) 「Create」ボタンを押す。
フォルダ構成は、次のとおりです。
・Mask Wearing.v1-416x416-black-padding.createml
・test
- _annotations.createml.json
- XXXX.jpg x 15
・train
- _annotations.createml.json
- XXXX.jpg x 105
・valid
- _annotations.createml.json
- XXXX.jpg x 29
JSON内は、次のようにCreateMLの書式で物体の位置とラベルが記述されています。
[
{
"image": "w1240-p16x9-0e48e0098f6e832f27d8b581b33bbc72b9967a63_jpg.rf.34ed1e8f70eebdabaf43ab9d40dc1c9b.jpg",
"annotations": [
{
"label": "mask",
"coordinates": {
"x": 282,
"y": 145,
"width": 112,
"height": 100
}
},
{
"label": "no-mask",
"coordinates": {
"x": 116,
"y": 158,
"width": 109,
"height": 92
}
}
]
},
:
]4. 物体検出モデルの学習
(1) 「Train Data」に先程準備した「train」フォルダを指定し、「Algorithm」に「Transfer Learning」を選択。
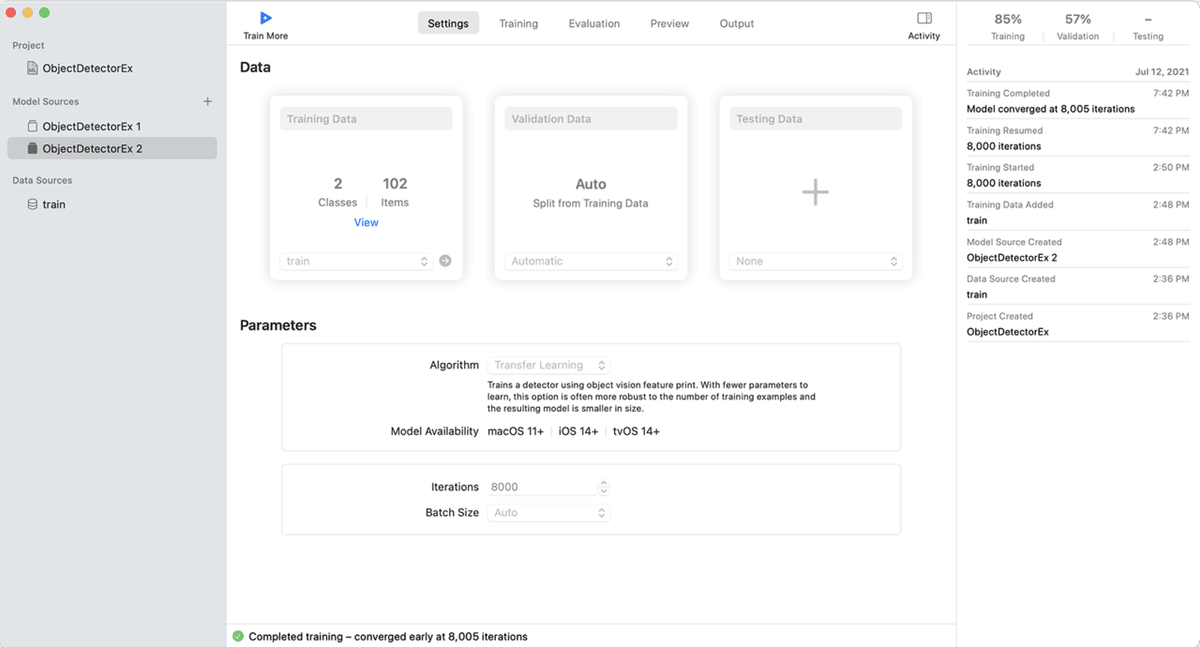
物体検出のパラメータは、次の通りです。
・Algorithm : Full Network or Transfer Learning
・Iteration : 学習回数 (デフォルトはデータ数に応じた数)
・Batch Size : 1回に学習する画像数 (デフォルトは環境における最大数)
・Grid Size:アスペクト比とオブジェクトの位置の精度に影響。(Full Netowrkのみ)
アルゴリズムは、次のとおり。
・Full Network
・Yolo v2で学習。
・1クラスあたり200画像。
・Transfer Learning
・Photosの学習済みモデルで転移学習。
・1クラスあたり80画像。
(2) 左上の「Train」ボタンを押下。
数時間待つと学習完了し、以下のように精度が表示されます。学習データの精度85%、検証データの精度57%です。学習は良いですが、検証はいまひとつなようです。

5. 物体検出モデルのプレビュー
「Preview」タブで画像ファイルをドラッグ&ドロップすることで、物体検出モデルを試すことができます。

【注意】「Transfoer Learning」で学習したモデルは、「Xcode 12.5.1」の「CreateML」のプレビューで「Unexpected Error」が発生して推論できませんでした。実機の「CoreML」では問題なく推論できるので、「CreateML」のプレビュー機能の問題のようです。
6. 物体検出モデルの出力
「Output」タブのGetボタンでmlmodelファイルを取得できます。
7. 学習データと学習方法の比較
学習データと学習方法の組み合わせを、1000イテレーションで学習して、比較してみました。
・416x416-black-padding + Full Network
・416x416-black-padding + Transfoer Learning
・raw + Full Network
・raw + Transfoer Learning
◎ 評価の比較
「Evaluation」タブの「Training」「Validation」を比較すると、次のようになります。
・416x416-black-padding + Full Network
・Training : 57 %
・Validation : 49%
・416x416-black-padding + Transfoer Learning
・Training : 84 %
・Validation : 49%
・raw + Full Network
・Training : 56 %
・Validation : 53%
・raw + Transfoer Learning
・Training : 92 %
・Validation : 50%
「I/U」「Varied I/U」を比較すると、次のようになります。
・416x416-black-padding + Full Network
・mask : 65% / 35 %
・no-mask : 49% / 21 %
・416x416-black-padding + Transfoer Learning
・mask : 87% / 77 %
・no-mask : 82% / 76 %
・raw + Full Network
・mask : 64% / 31 %
・no-mask : 49% / 21 %
・raw + Transfoer Learning
・mask : 91% / 80 %
・no-mask : 92% / 84 %
1000イテレーションであれば、「Full Network」より「Transfoer Learning」の方が精度が高いことがわかります。「416x416-black-padding + Transfoer Learning」より「raw + Transfoer Learning」が高いのは、転移学習のベースモデルがblack-paddingでないのが原因と思われます。
◎ 入力画像の比較
「Output」タブの入力画像サイズを比較すると、次のようになります。
・Full Network : 419x419
・Transfer Learning : 299x299
「Transfer Learning」より「Full Network」の方が大きい入力画像を使っていることがわかります。転移学習のベースモデルの入力画像が299x299なのが原因と思われます。
この記事が気に入ったらサポートをしてみませんか?