最近話題になった 強化学習 技術のまとめ

最近話題になった 強化学習 技術をまとめました。
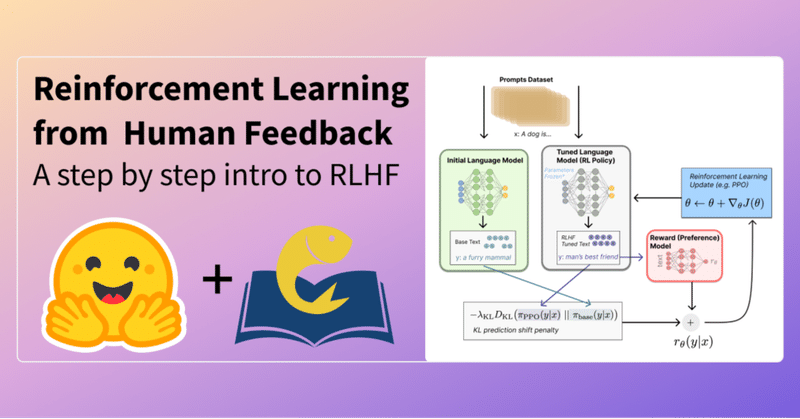
1. RLHF (Reinforcement Learning from Human Feedback)
「RLHF」は、言語モデルを、人間のフィードバックからの強化学習でファインチューニングする手法です。
一般的なコーパスで学習した言語モデルを、複雑な人間の価値観に合わせることができるようになり始めました。最近ではチャットAI「ChatGPT」が「RLHF」の成功例となっています。

2. Decision Transformer
「Decision Transoformer」は、言語モデルの次のテキストを予測する仕組みで、オフライン強化学習タスクを解けることを示したAIモデルです。言語モデルによる教師あり学習で強化学習タスクを解きます。
「Multi-Game Decision Transformers」では40以上のAtariゲーム、「Robotics Transformer : RT-1」では700以上の実世界のロボットタスクを達成できることを示しました。
3. Decision Diffuser
「Decision Diffuser」は、条件付き生成(拡散)モデルを使って、オフライン強化学習タスクを解けることを示したAIモデルです。標準的なベンチマークにおいて、既存のオフライン強化学習を上回ったとのことです。
Introducing Decision Diffuser, a conditional diffusion model that outperforms offline RL across standard benchmarks – using only generative modeling training! Decision Diffusers can also combine multiple constraints and skills at test-time.
— Yilun Du (@du_yilun) November 29, 2022
Website:https://t.co/bQErTTKHEc
1/5 pic.twitter.com/SryFdw7otO
4. MineClip / VPT
「MineClip」(NVIDIA)と「VPT」(OpenAI)は、ネット上の大量の動画からマインクラフトを学習したAIモデルです。言語モデルがネット上の大量のテキストから学習するように、ネット上の大量の動画からマインクラフトを学習します。
現在の複雑なゲームを学習するには、ランダムな行動から強化学習するだけでは限界があり、動画や攻略サイトなどで事前知識を得る手法が求められており、「MineClip」と「VPT」はその第一歩となります。
5. MA-POCA
「MA-POCA」は、エージェントに協調行動を学習させるための手法です。各エージェントは、局所的に認識したものだけに基づいて意思決定を行い、同時に、グループ全体の文脈の中で自分の行動がどれだけ優れているかを評価することができます。
「MA-POCA」は、「Unity ML-Agents」で利用可能な強化学習アルゴリズムの1つとして提供されています。
まもなく発売されるUnityで人工知能を育てる本
— 布留川英一 / Hidekazu Furukawa (@npaka123) December 4, 2022
「Unityではじめる機械学習・強化学習 Unity ML-Agents 実践ゲームプログラミング v2.2対応」
の新機能をいくつか紹介。→スレッドhttps://t.co/2lGJ9hgTi6 pic.twitter.com/tYwWTquUxX
この記事が気に入ったらサポートをしてみませんか?