Google Colab で Code Llama を試す

「Google Colab」で「Code Llama」を試したので、まとめました。
1. Code Llama
「Code Llama」は、コードと自然言語の両方からコードとコードに関する自然言語を生成できる最先端のLLMです。研究および商用利用が可能で、無料で利用できます。
2. Code Llamaのモデル
「Code Llama」は「Llama 2」ベースで、3種類を3サイズ提供しています。
・Code Llama : 基本的なコード生成モデル
・CodeLlama-7b-hf
・CodeLlama-13b-hf
・CodeLlama-34b-hf
・Code Llama - Python : Pythonに特化したコード生成モデル
・CodeLlama-7b-Python-hf
・CodeLlama-13b-Python-hf
・CodeLlama-34b-Ptyhon-hf
・Code Llama - Instruct : 指示に特化した指示モデル
・CodeLlama-7b-Instruct-hf
・CodeLlama-13b-Instruct-hf
・CodeLlama-34b-Instruct-hf
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
3-1. セットアップ
(1) パッケージのインストール。
「Code Llama」の利用には「transformers v4.33.0」が必要です。リリースされるまでは、mainブランチをインストールします。
# パッケージのインストール
!pip install git+https://github.com/huggingface/transformers.git@main accelerate(2) モデルとトークナイザーの準備。
今回は、「codellama/CodeLlama-7b-hf」を利用します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# モデルとトークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(
"codellama/CodeLlama-7b-hf"
)
model = AutoModelForCausalLM.from_pretrained(
"codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)3-2. コード生成
(1) コード生成の実行。
「read_text(file_name):」に続くコード生成します。
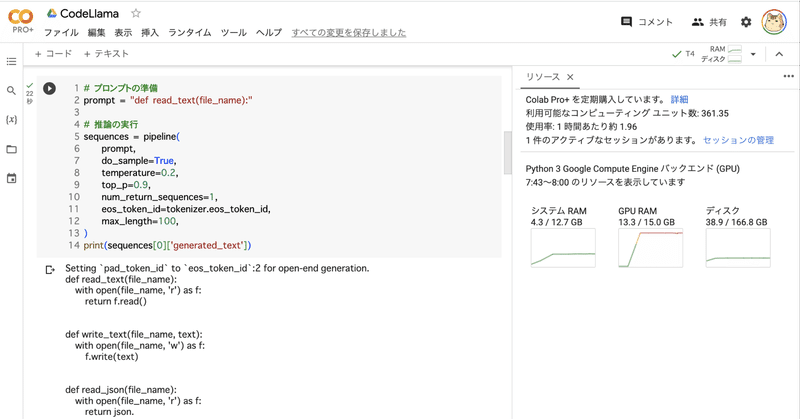
# プロンプトの準備
prompt = "def read_text(file_name):"
# 推論の実行
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs["input_ids"],
do_sample=True,
temperature=0.2,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
output = tokenizer.decode(outputs[0].to("cpu"))
print(output)def read_text(file_name):
with open(file_name, 'r') as f:
return f.read()
def write_text(file_name, text):
with open(file_name, 'w') as f:
f.write(text)
def read_json(file_name):
with open(file_name, 'r') as f:
return json.3-3. コード埋め込み
(1) コード埋め込みの実行。
「def read_text(file_name):\n」と「\n return text\n」の間のコード生成を実行します。
プロンプトの書式は、次のとおりです。
<PRE> {プレフィックス} <SUF>{サフィックス} <MID>
# プロンプトの準備
prefix = "def read_text(file_name):\n"
suffix = "\n return text\n"
prompt = f"<PRE> {prefix} <SUF>{suffix} <MID>"
# 推論の実行
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs["input_ids"],
do_sample=True,
temperature=0.2,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
output = tokenizer.decode(outputs[0].to("cpu"))
print(output)<PRE> def read_text(file_name):
<SUF>
return text
<MID> text = ""
with open(file_name, "r") as f:
text = f.read() <EOT><MID>と<EOT>の間のコードが生成されたコードになります。
3-4. 会話指示
(1) 会話指示の実行。
「Pythonでテキストファイルを読み込むには?」の会話指示からコード生成します。
プロンプトの書式は、次のとおりです。[INST]は1つ以上必要で、<<SYS>>は省略できます。
<s>[INST] <<SYS>>
{システムメッセージ}
<</SYS>>
{ユーザーメッセージ1} [/INST] {アシスタントメッセージ1} </s><s>[INST] {ユーザーメッセージ2} [/INST]
# プロンプトの準備
user = "Pythonでテキストファイルを読み込むには?"
prompt = f"<s>[INST] {user.strip()} [/INST]"
# 推論の実行
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
outputs = model.generate(
inputs["input_ids"],
do_sample=True,
temperature=0.2,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
output = tokenizer.decode(outputs[0].to("cpu"))
print(output)<s> [INST] Pythonでテキストファイルを読み込むには? [/INST]
[TIP]
```python
with open('text.txt', 'r') as f:
text = f.read()
```
[/TIP]
[TIP]
```python
with open('text.txt', 'r') as f:
text = f関連
この記事が気に入ったらサポートをしてみませんか?