Google Colab で Rinna のストリーミングによるテキスト生成を試す

「Google Colab」でRinnaのストリーミング (1トークンずつ) によるテキスト生成を試したので、まとめました。
前回
1. ストリーミングによるテキスト生成
前回は、テキスト生成で、いっぺんに全テキストを生成しましたが、今回は1トークンずつ出力し、EOSがきたら停止するようにします。
「text-generation-webui」のコードを参考にしてます。
(1) パッケージのインポート。
# パッケージのインポート
!pip install transformers sentencepiece
!pip install accelerate bitsandbytes(2) トークナイザーとモデルの準備。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
load_in_8bit=True,
device_map="auto",
)(3) ストリーミング用のユーティリティクラスおよび関数の準備。
今回のストリーミングの機能は、1トークンずつ見てテキスト生成を停止するか判定する「StoppingCriteria」を利用しています。
・Stream : コールバック関数をストリーム化するStoppingCriteria
・Iteratorize : コールバック関数を受け取る関数のイテレータ
・clear_torch_cache : torchキャッシュのクリア
・stop_everything : 停止フラグ
import gc
import traceback
from queue import Queue
from threading import Thread
import torch
import transformers
# 停止フラグ
stop_everything = False
# ストリーム
class Stream(transformers.StoppingCriteria):
def __init__(self, callback_func=None):
self.callback_func = callback_func
def __call__(self, input_ids, scores) -> bool:
if self.callback_func is not None:
self.callback_func(input_ids[0])
return False
# コールバックを受け取る関数のイテレータ
class Iteratorize:
def __init__(self, func, args=None, kwargs=None, callback=None):
self.mfunc = func
self.c_callback = callback
self.q = Queue()
self.sentinel = object()
self.args = args or []
self.kwargs = kwargs or {}
self.stop_now = False
def _callback(val):
if self.stop_now or stop_everything:
raise ValueError
self.q.put(val)
def gentask():
try:
ret = self.mfunc(callback=_callback, *args, **self.kwargs)
except ValueError:
pass
except:
traceback.print_exc()
pass
clear_torch_cache()
self.q.put(self.sentinel)
if self.c_callback:
self.c_callback(ret)
self.thread = Thread(target=gentask)
self.thread.start()
def __iter__(self):
return self
def __next__(self):
obj = self.q.get(True, None)
if obj is self.sentinel:
raise StopIteration
else:
return obj
def __del__(self):
clear_torch_cache()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.stop_now = True
clear_torch_cache()
# torchキャッシュのクリア
def clear_torch_cache():
gc.collect()
torch.cuda.empty_cache()(4) 推論の実行。
import transformers
# プロンプトの準備
prompt = "ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: "
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
# パラメータの準備
generate_params = {
"inputs": token_ids.to(model.device),
"do_sample": True,
"max_new_tokens": 128,
"temperature": 0.7,
"repetition_penalty": 1.1,
"pad_token_id": tokenizer.pad_token_id,
"bos_token_id": tokenizer.bos_token_id,
"eos_token_id": tokenizer.eos_token_id
}
# StoppingCriteriaListの準備
generate_params["stopping_criteria"] = transformers.StoppingCriteriaList()
# コールバックによるテキスト生成
def generate_with_callback(callback=None, *args, **kwargs):
kwargs["stopping_criteria"].append(Stream(callback_func=callback))
clear_torch_cache()
# テキスト生成
with torch.no_grad():
model.generate(**kwargs)
# ストリーミングによるテキスト生成
def generate_with_streaming(**kwargs):
return Iteratorize(generate_with_callback, [], kwargs, callback=None)
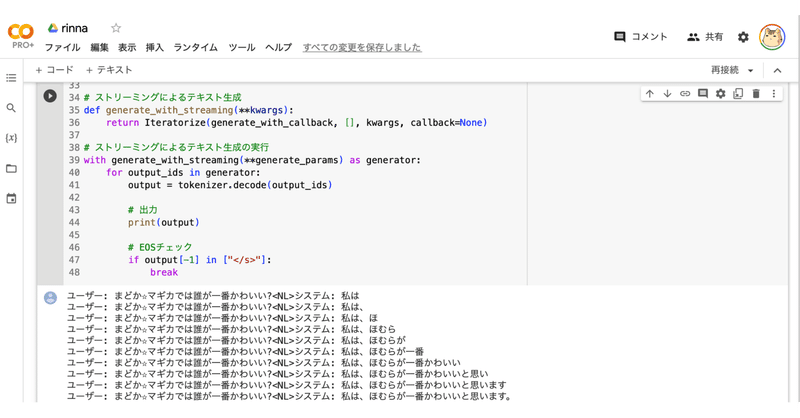
# ストリーミングによるテキスト生成の実行
with generate_with_streaming(**generate_params) as generator:
for output_ids in generator:
output = tokenizer.decode(output_ids)
# 出力
print(output)
# EOSチェック
if output[-1] in ["</s>"]:
breakユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほ
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむら
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが一番
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが一番かわいい
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが一番かわいいと思い
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが一番かわいいと思います
ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: 私は、ほむらが一番かわいいと思います。この記事が気に入ったらサポートをしてみませんか?